 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting affinity ties in a surname network
Jun 02, 2023From administrative registers of last names in Santiago, Chile, we create a surname affinity network that encodes socioeconomic data. This network is a multi-relational graph with nodes representing surnames and edges representing the prevalence of interactions between surnames by socioeconomic decile. We model the prediction of links as a knowledge base completion problem, and find that sharing neighbors is highly predictive of the formation of new links. Importantly, We distinguish between grounded neighbors and neighbors in the embedding space, and find that the latter is more predictive of tie formation. The paper discusses the implications of this finding in explaining the high levels of elite endogamy in Santiago.
Evaluation Benchmarks for Spanish Sentence Representations
Apr 15, 2022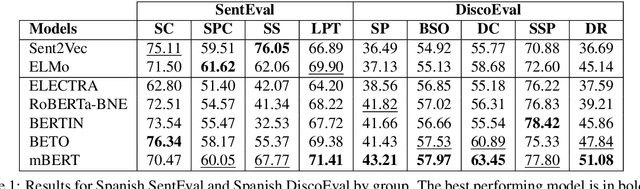
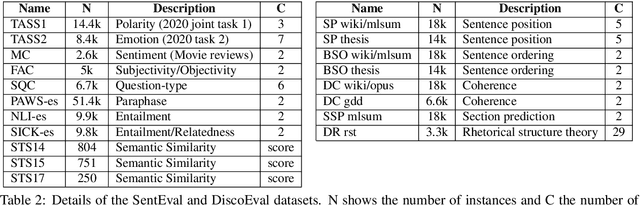
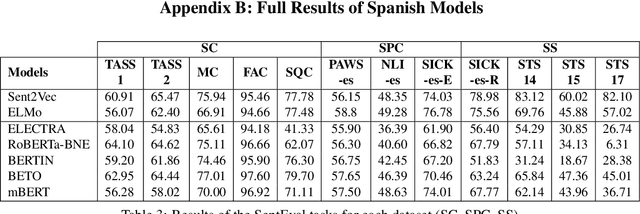
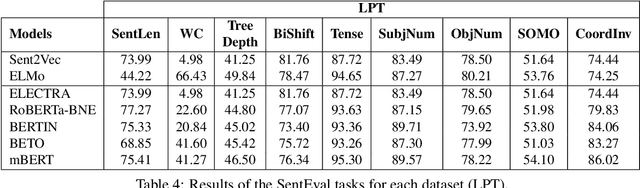
Due to the success of pre-trained language models, versions of languages other than English have been released in recent years. This fact implies the need for resources to evaluate these models. In the case of Spanish, there are few ways to systematically assess the models' quality. In this paper, we narrow the gap by building two evaluation benchmarks. Inspired by previous work (Conneau and Kiela, 2018; Chen et al., 2019), we introduce Spanish SentEval and Spanish DiscoEval, aiming to assess the capabilities of stand-alone and discourse-aware sentence representations, respectively. Our benchmarks include considerable pre-existing and newly constructed datasets that address different tasks from various domains. In addition, we evaluate and analyze the most recent pre-trained Spanish language models to exhibit their capabilities and limitations. As an example, we discover that for the case of discourse evaluation tasks, mBERT, a language model trained on multiple languages, usually provides a richer latent representation than models trained only with documents in Spanish. We hope our contribution will motivate a fairer, more comparable, and less cumbersome way to evaluate future Spanish language models.
Augmenting BERT-style Models with Predictive Coding to Improve Discourse-level Representations
Sep 10, 2021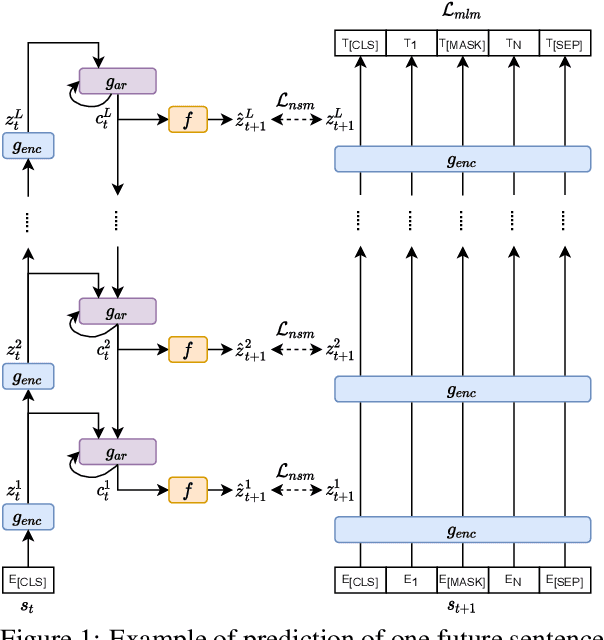
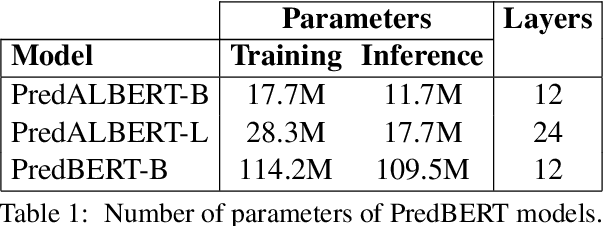
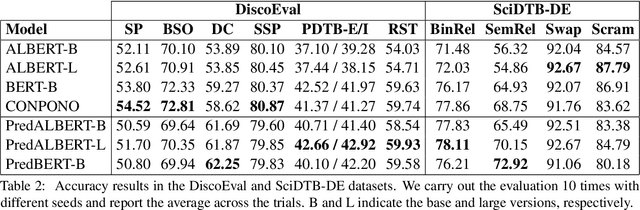
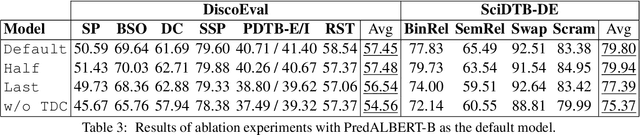
Current language models are usually trained using a self-supervised scheme, where the main focus is learning representations at the word or sentence level. However, there has been limited progress in generating useful discourse-level representations. In this work, we propose to use ideas from predictive coding theory to augment BERT-style language models with a mechanism that allows them to learn suitable discourse-level representations. As a result, our proposed approach is able to predict future sentences using explicit top-down connections that operate at the intermediate layers of the network. By experimenting with benchmarks designed to evaluate discourse-related knowledge using pre-trained sentence representations, we demonstrate that our approach improves performance in 6 out of 11 tasks by excelling in discourse relationship detection.
Neural Abstractive Unsupervised Summarization of Online News Discussions
Jun 19, 2021
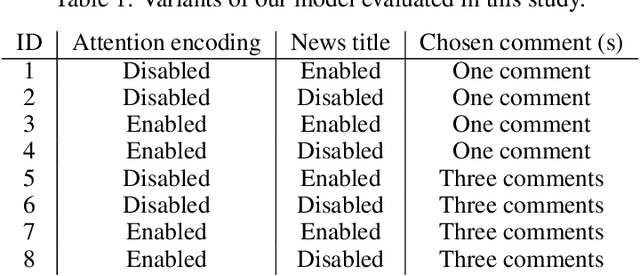

Summarization has usually relied on gold standard summaries to train extractive or abstractive models. Social media brings a hurdle to summarization techniques since it requires addressing a multi-document multi-author approach. We address this challenging task by introducing a novel method that generates abstractive summaries of online news discussions. Our method extends a BERT-based architecture, including an attention encoding that fed comments' likes during the training stage. To train our model, we define a task which consists of reconstructing high impact comments based on popularity (likes). Accordingly, our model learns to summarize online discussions based on their most relevant comments. Our novel approach provides a summary that represents the most relevant aspects of a news item that users comment on, incorporating the social context as a source of information to summarize texts in online social networks. Our model is evaluated using ROUGE scores between the generated summary and each comment on the thread. Our model, including the social attention encoding, significantly outperforms both extractive and abstractive summarization methods based on such evaluation.
Inspecting the concept knowledge graph encoded by modern language models
Jun 02, 2021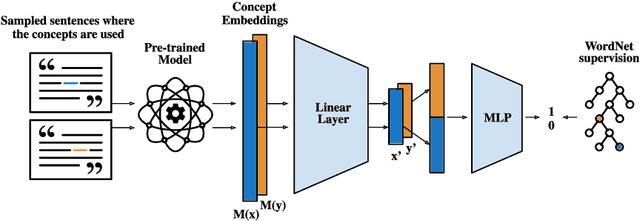
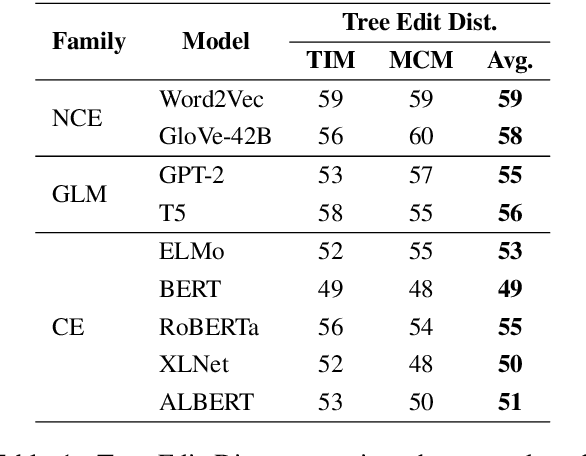
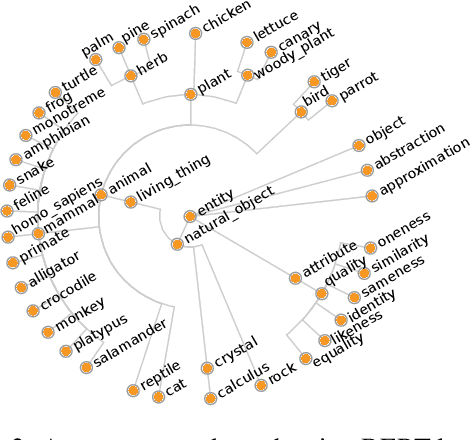
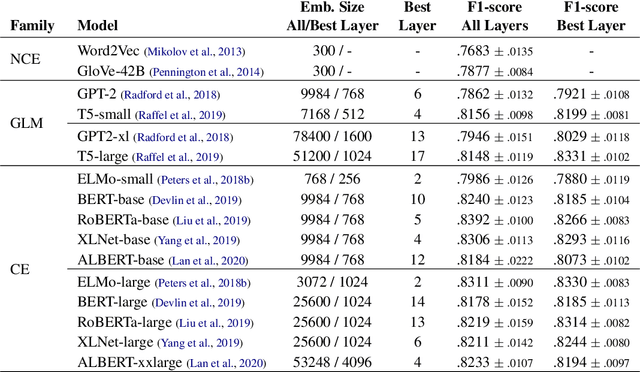
The field of natural language understanding has experienced exponential progress in the last few years, with impressive results in several tasks. This success has motivated researchers to study the underlying knowledge encoded by these models. Despite this, attempts to understand their semantic capabilities have not been successful, often leading to non-conclusive, or contradictory conclusions among different works. Via a probing classifier, we extract the underlying knowledge graph of nine of the most influential language models of the last years, including word embeddings, text generators, and context encoders. This probe is based on concept relatedness, grounded on WordNet. Our results reveal that all the models encode this knowledge, but suffer from several inaccuracies. Furthermore, we show that the different architectures and training strategies lead to different model biases. We conduct a systematic evaluation to discover specific factors that explain why some concepts are challenging. We hope our insights will motivate the development of models that capture concepts more precisely.
A data-driven strategy to combine word embeddings in information retrieval
May 26, 2021
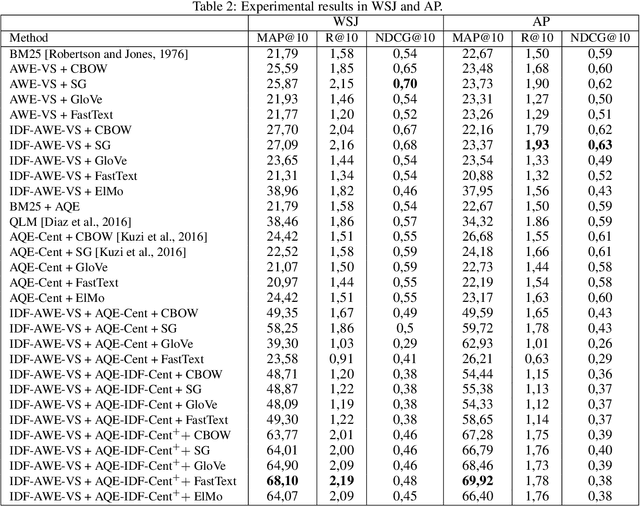

Word embeddings are vital descriptors of words in unigram representations of documents for many tasks in natural language processing and information retrieval. The representation of queries has been one of the most critical challenges in this area because it consists of a few terms and has little descriptive capacity. Strategies such as average word embeddings can enrich the queries' descriptive capacity since they favor the identification of related terms from the continuous vector representations that characterize these approaches. We propose a data-driven strategy to combine word embeddings. We use Idf combinations of embeddings to represent queries, showing that these representations outperform the average word embeddings recently proposed in the literature. Experimental results on benchmark data show that our proposal performs well, suggesting that data-driven combinations of word embeddings are a promising line of research in ad-hoc information retrieval.
Says who? Automatic Text-Based Content Analysis of Television News
Aug 29, 2013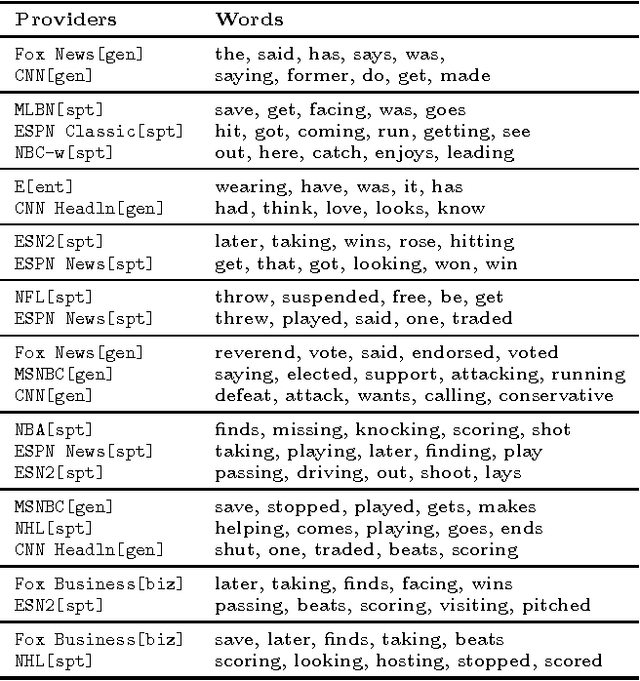
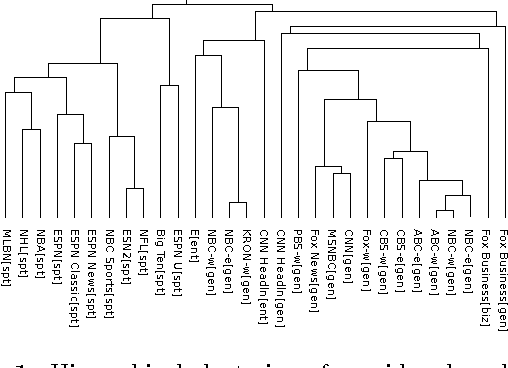
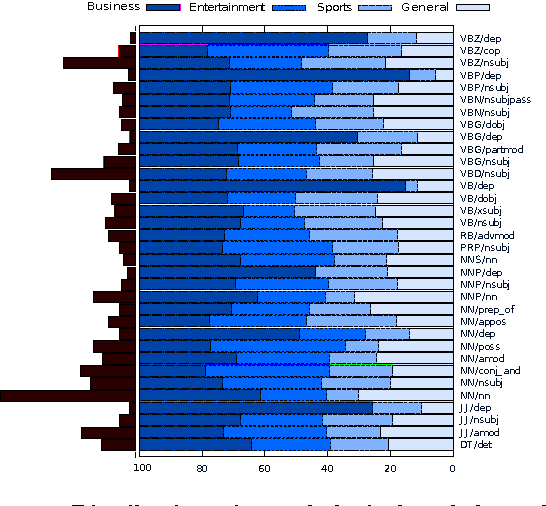

We perform an automatic analysis of television news programs, based on the closed captions that accompany them. Specifically, we collect all the news broadcasted in over 140 television channels in the US during a period of six months. We start by segmenting, processing, and annotating the closed captions automatically. Next, we focus on the analysis of their linguistic style and on mentions of people using NLP methods. We present a series of key insights about news providers, people in the news, and we discuss the biases that can be uncovered by automatic means. These insights are contrasted by looking at the data from multiple points of view, including qualitative assessment.