 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural language models for text classification in evidence-based medicine
Dec 01, 2020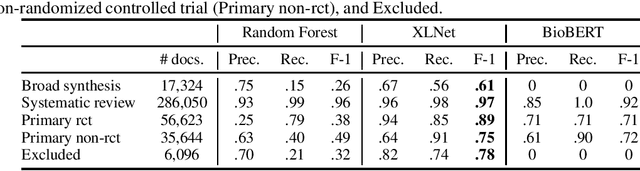
The COVID-19 has brought about a significant challenge to the whole of humanity, but with a special burden upon the medical community. Clinicians must keep updated continuously about symptoms, diagnoses, and effectiveness of emergent treatments under a never-ending flood of scientific literature. In this context, the role of evidence-based medicine (EBM) for curating the most substantial evidence to support public health and clinical practice turns essential but is being challenged as never before due to the high volume of research articles published and pre-prints posted daily. Artificial Intelligence can have a crucial role in this situation. In this article, we report the results of an applied research project to classify scientific articles to support Epistemonikos, one of the most active foundations worldwide conducting EBM. We test several methods, and the best one, based on the XLNet neural language model, improves the current approach by 93\% on average F1-score, saving valuable time from physicians who volunteer to curate COVID-19 research articles manually.
On Adversarial Examples for Biomedical NLP Tasks
Apr 23, 2020
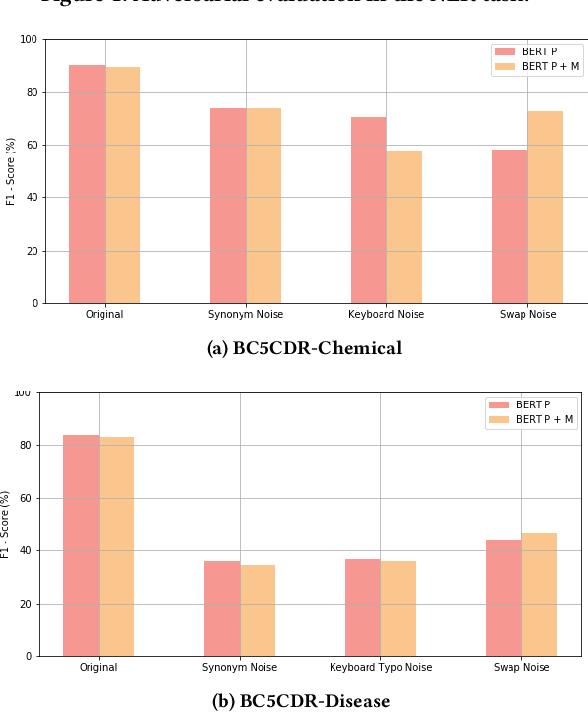
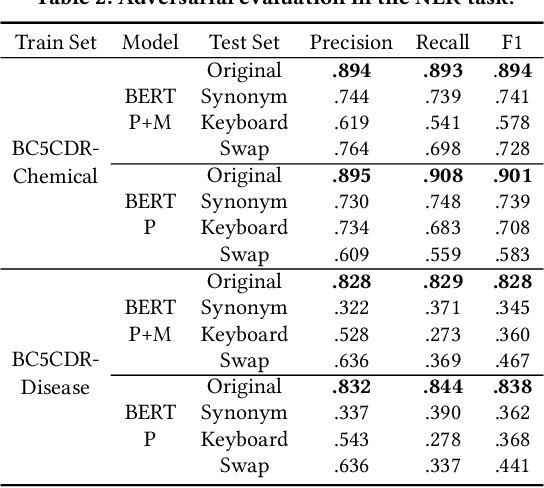
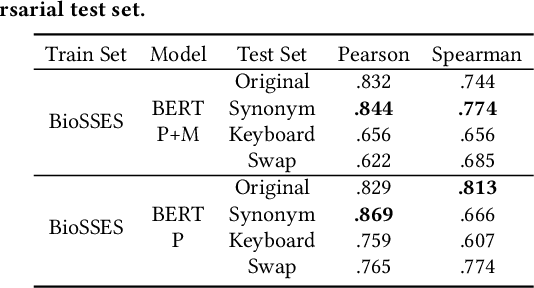
The success of pre-trained word embeddings has motivated its use in tasks in the biomedical domain. The BERT language model has shown remarkable results on standard performance metrics in tasks such as Named Entity Recognition (NER) and Semantic Textual Similarity (STS), which has brought significant progress in the field of NLP. However, it is unclear whether these systems work seemingly well in critical domains, such as legal or medical. For that reason, in this work, we propose an adversarial evaluation scheme on two well-known datasets for medical NER and STS. We propose two types of attacks inspired by natural spelling errors and typos made by humans. We also propose another type of attack that uses synonyms of medical terms. Under these adversarial settings, the accuracy of the models drops significantly, and we quantify the extent of this performance loss. We also show that we can significantly improve the robustness of the models by training them with adversarial examples. We hope our work will motivate the use of adversarial examples to evaluate and develop models with increased robustness for medical tasks.