 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Relevant is Selective Memory Population in Lifelong Language Learning?
Oct 03, 2022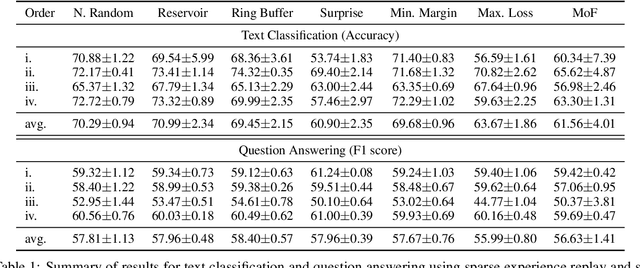
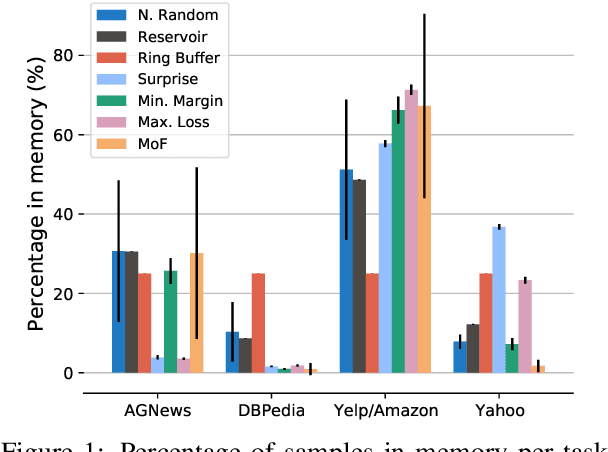

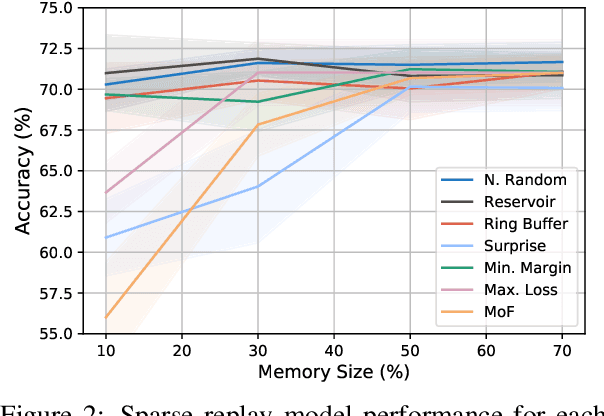
Lifelong language learning seeks to have models continuously learn multiple tasks in a sequential order without suffering from catastrophic forgetting. State-of-the-art approaches rely on sparse experience replay as the primary approach to prevent forgetting. Experience replay usually adopts sampling methods for the memory population; however, the effect of the chosen sampling strategy on model performance has not yet been studied. In this paper, we investigate how relevant the selective memory population is in the lifelong learning process of text classification and question-answering tasks. We found that methods that randomly store a uniform number of samples from the entire data stream lead to high performances, especially for low memory size, which is consistent with computer vision studies.
Pre-trained Speech Representations as Feature Extractors for Speech Quality Assessment in Online Conferencing Applications
Oct 01, 2022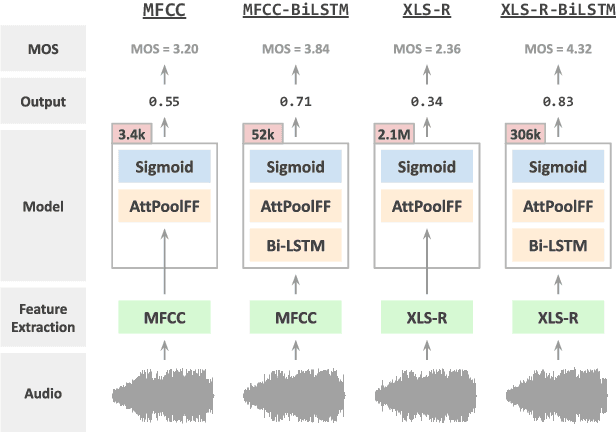
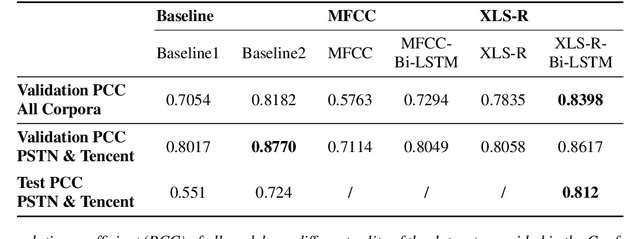
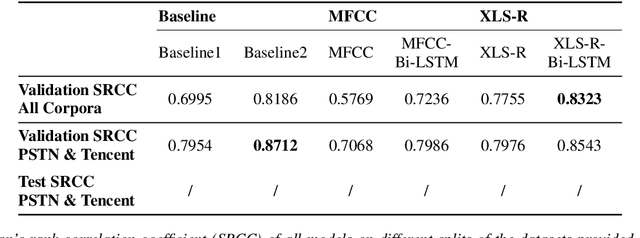
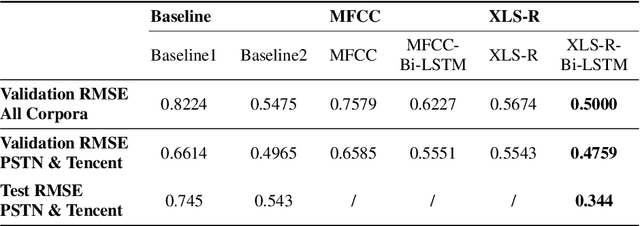
Speech quality in online conferencing applications is typically assessed through human judgements in the form of the mean opinion score (MOS) metric. Since such a labor-intensive approach is not feasible for large-scale speech quality assessments in most settings, the focus has shifted towards automated MOS prediction through end-to-end training of deep neural networks (DNN). Instead of training a network from scratch, we propose to leverage the speech representations from the pre-trained wav2vec-based XLS-R model. However, the number of parameters of such a model exceeds task-specific DNNs by several orders of magnitude, which poses a challenge for resulting fine-tuning procedures on smaller datasets. Therefore, we opt to use pre-trained speech representations from XLS-R in a feature extraction rather than a fine-tuning setting, thereby significantly reducing the number of trainable model parameters. We compare our proposed XLS-R-based feature extractor to a Mel-frequency cepstral coefficient (MFCC)-based one, and experiment with various combinations of bidirectional long short term memory (Bi-LSTM) and attention pooling feedforward (AttPoolFF) networks trained on the output of the feature extractors. We demonstrate the increased performance of pre-trained XLS-R embeddings in terms a reduced root mean squared error (RMSE) on the ConferencingSpeech 2022 MOS prediction task.
* 5 pages, submitted to INTERSPEECH 2022