 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Relevant is Selective Memory Population in Lifelong Language Learning?
Paper and Code
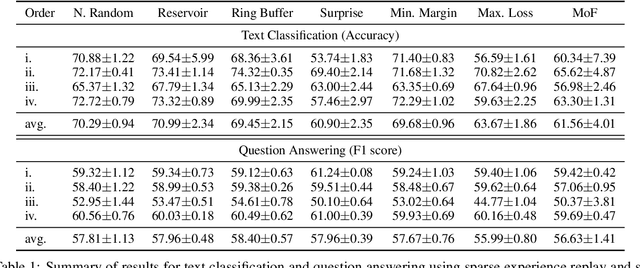
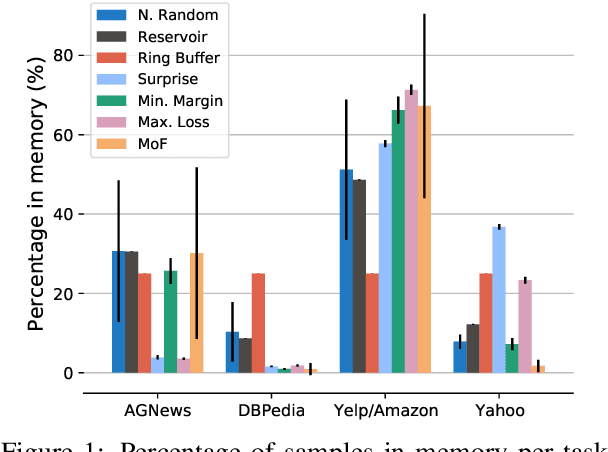

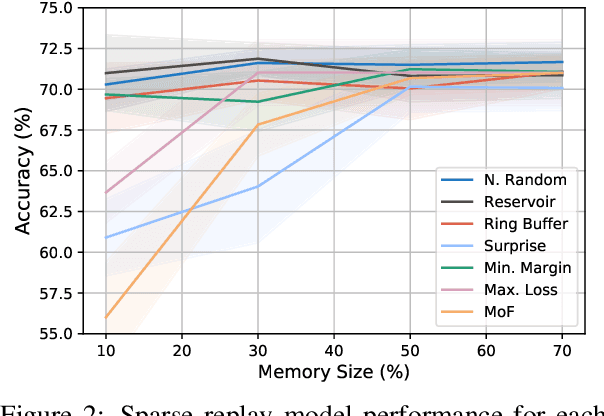
Lifelong language learning seeks to have models continuously learn multiple tasks in a sequential order without suffering from catastrophic forgetting. State-of-the-art approaches rely on sparse experience replay as the primary approach to prevent forgetting. Experience replay usually adopts sampling methods for the memory population; however, the effect of the chosen sampling strategy on model performance has not yet been studied. In this paper, we investigate how relevant the selective memory population is in the lifelong learning process of text classification and question-answering tasks. We found that methods that randomly store a uniform number of samples from the entire data stream lead to high performances, especially for low memory size, which is consistent with computer vision studies.