 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying latent disease factors differently expressed in patient subgroups using group factor analysis
Oct 10, 2024



In this study, we propose a novel approach to uncover subgroup-specific and subgroup-common latent factors addressing the challenges posed by the heterogeneity of neurological and mental disorders, which hinder disease understanding, treatment development, and outcome prediction. The proposed approach, sparse Group Factor Analysis (GFA) with regularised horseshoe priors, was implemented with probabilistic programming and can uncover associations (or latent factors) among multiple data modalities differentially expressed in sample subgroups. Synthetic data experiments showed the robustness of our sparse GFA by correctly inferring latent factors and model parameters. When applied to the Genetic Frontotemporal Dementia Initiative (GENFI) dataset, which comprises patients with frontotemporal dementia (FTD) with genetically defined subgroups, the sparse GFA identified latent disease factors differentially expressed across the subgroups, distinguishing between "subgroup-specific" latent factors within homogeneous groups and "subgroup common" latent factors shared across subgroups. The latent disease factors captured associations between brain structure and non-imaging variables (i.e., questionnaires assessing behaviour and disease severity) across the different genetic subgroups, offering insights into disease profiles. Importantly, two latent factors were more pronounced in the two more homogeneous FTD patient subgroups (progranulin (GRN) and microtubule-associated protein tau (MAPT) mutation), showcasing the method's ability to reveal subgroup-specific characteristics. These findings underscore the potential of sparse GFA for integrating multiple data modalities and identifying interpretable latent disease factors that can improve the characterization and stratification of patients with neurological and mental health disorders.
Analysis of XLS-R for Speech Quality Assessment
Aug 23, 2023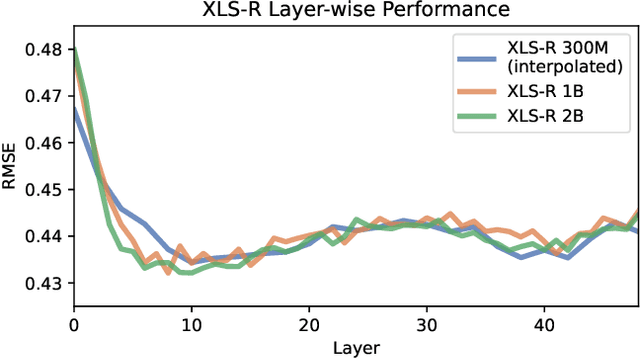
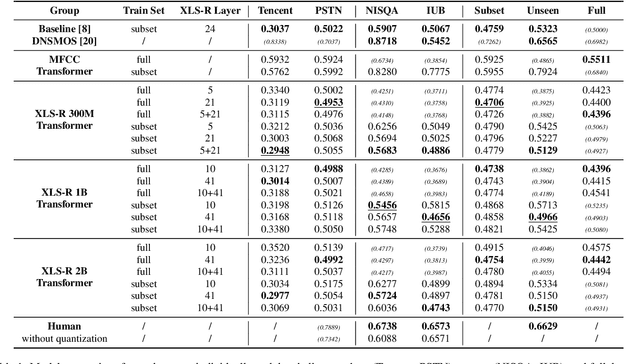
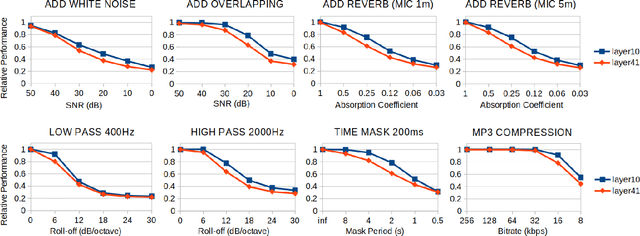
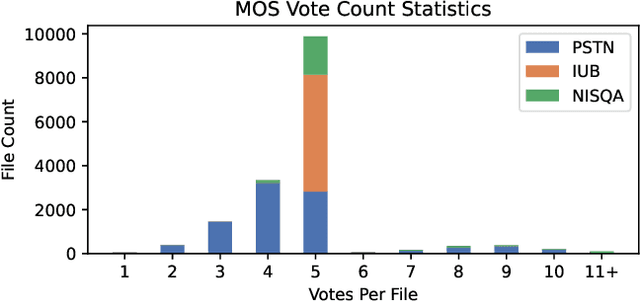
In online conferencing applications, estimating the perceived quality of an audio signal is crucial to ensure high quality of experience for the end user. The most reliable way to assess the quality of a speech signal is through human judgments in the form of the mean opinion score (MOS) metric. However, such an approach is labor intensive and not feasible for large-scale applications. The focus has therefore shifted towards automated speech quality assessment through end-to-end training of deep neural networks. Recently, it was shown that leveraging pre-trained wav2vec-based XLS-R embeddings leads to state-of-the-art performance for the task of speech quality prediction. In this paper, we perform an in-depth analysis of the pre-trained model. First, we analyze the performance of embeddings extracted from each layer of XLS-R and also for each size of the model (300M, 1B, 2B parameters). Surprisingly, we find two optimal regions for feature extraction: one in the lower-level features and one in the high-level features. Next, we investigate the reason for the two distinct optima. We hypothesize that the lower-level features capture characteristics of noise and room acoustics, whereas the high-level features focus on speech content and intelligibility. To investigate this, we analyze the sensitivity of the MOS predictions with respect to different levels of corruption in each category. Afterwards, we try fusing the two optimal feature depths to determine if they contain complementary information for MOS prediction. Finally, we compare the performance of the proposed models and assess the generalizability of the models on unseen datasets.
Cross-Lingual Transfer Learning for Alzheimer's Detection From Spontaneous Speech
Mar 06, 2023Alzheimer's disease (AD) is a progressive neurodegenerative disease most often associated with memory deficits and cognitive decline. With the aging population, there has been much interest in automated methods for cognitive impairment detection. One approach that has attracted attention in recent years is AD detection through spontaneous speech. While the results are promising, it is not certain whether the learned speech features can be generalized across languages. To fill this gap, the ADReSS-M challenge was organized. This paper presents our submission to this ICASSP-2023 Signal Processing Grand Challenge (SPGC). The model was trained on 228 English samples of a picture description task and was transferred to Greek using only 8 samples. We obtained an accuracy of 82.6% for AD detection, a root-mean-square error of 4.345 for cognitive score prediction, and ranked 2nd place in the competition out of 24 competitors.
Pre-trained Speech Representations as Feature Extractors for Speech Quality Assessment in Online Conferencing Applications
Oct 01, 2022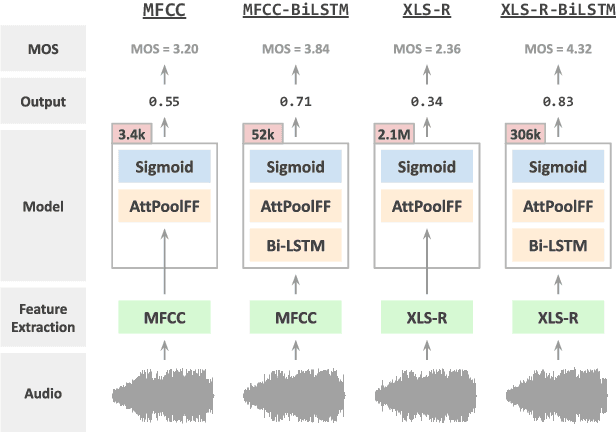
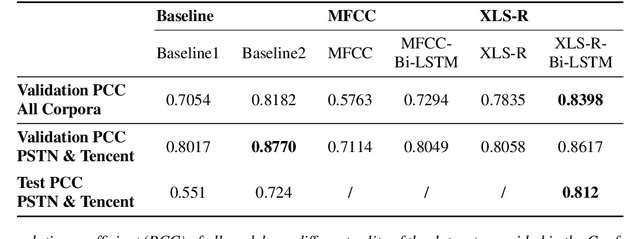
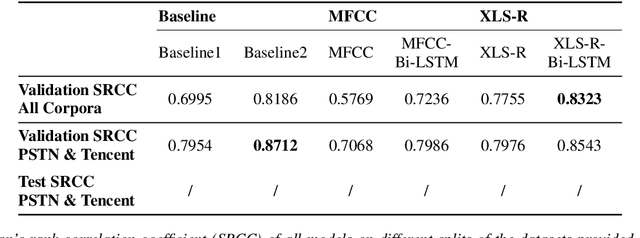
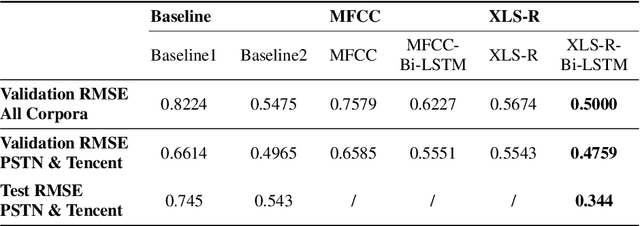
Speech quality in online conferencing applications is typically assessed through human judgements in the form of the mean opinion score (MOS) metric. Since such a labor-intensive approach is not feasible for large-scale speech quality assessments in most settings, the focus has shifted towards automated MOS prediction through end-to-end training of deep neural networks (DNN). Instead of training a network from scratch, we propose to leverage the speech representations from the pre-trained wav2vec-based XLS-R model. However, the number of parameters of such a model exceeds task-specific DNNs by several orders of magnitude, which poses a challenge for resulting fine-tuning procedures on smaller datasets. Therefore, we opt to use pre-trained speech representations from XLS-R in a feature extraction rather than a fine-tuning setting, thereby significantly reducing the number of trainable model parameters. We compare our proposed XLS-R-based feature extractor to a Mel-frequency cepstral coefficient (MFCC)-based one, and experiment with various combinations of bidirectional long short term memory (Bi-LSTM) and attention pooling feedforward (AttPoolFF) networks trained on the output of the feature extractors. We demonstrate the increased performance of pre-trained XLS-R embeddings in terms a reduced root mean squared error (RMSE) on the ConferencingSpeech 2022 MOS prediction task.
* 5 pages, submitted to INTERSPEECH 2022