 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on the Predictability of Sample Learning Consistency
Jul 07, 2022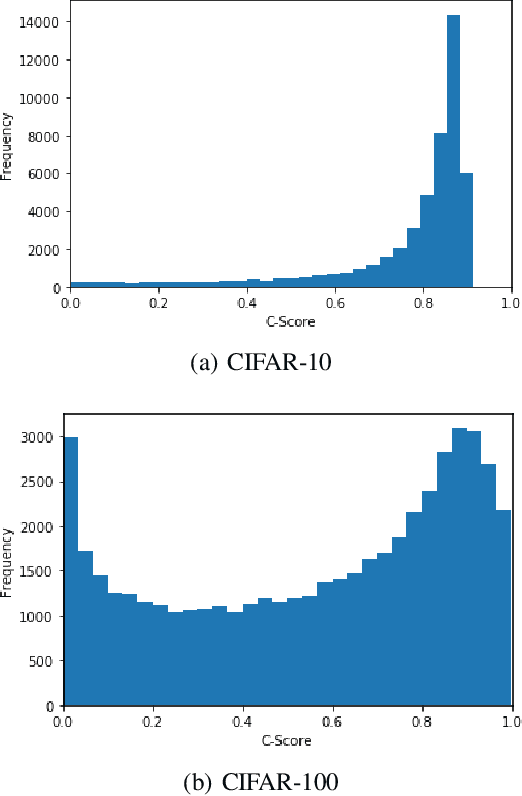
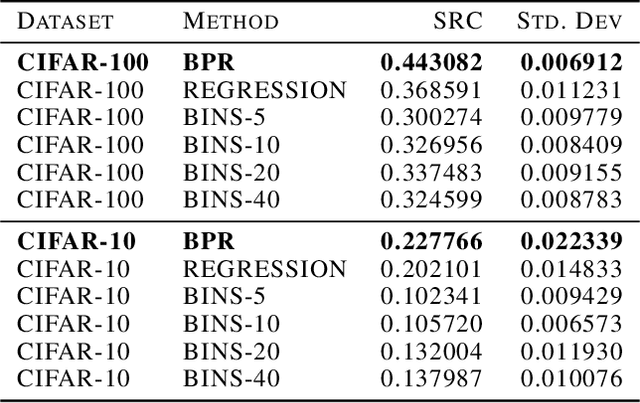
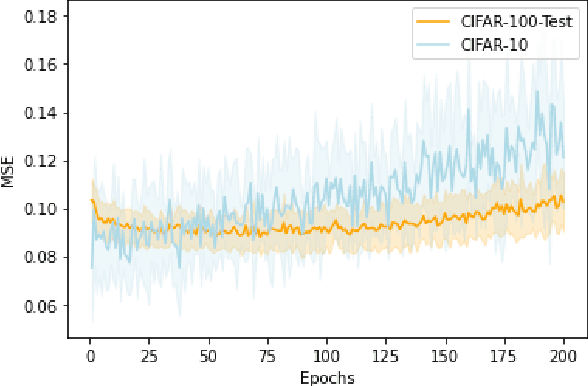
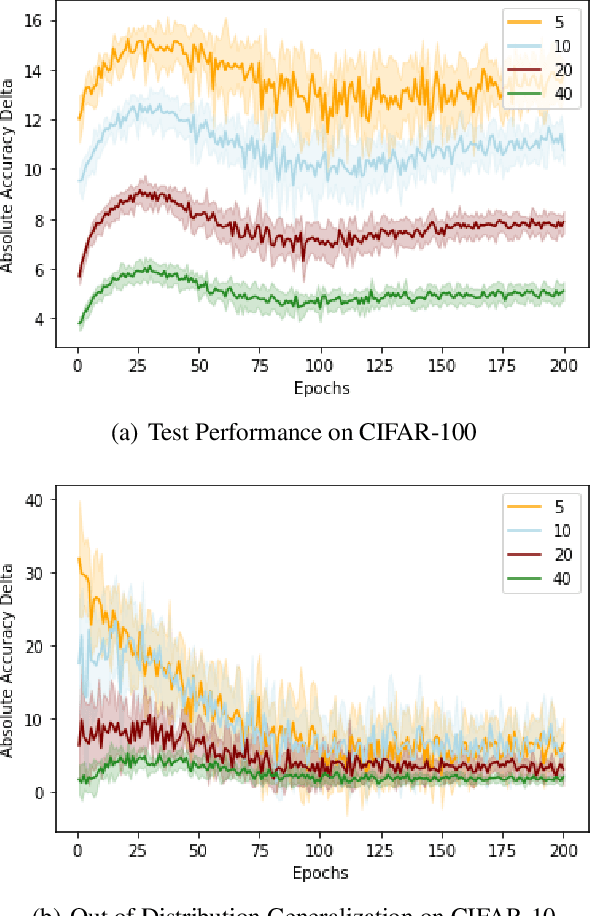
Curriculum Learning is a powerful training method that allows for faster and better training in some settings. This method, however, requires having a notion of which examples are difficult and which are easy, which is not always trivial to provide. A recent metric called C-Score acts as a proxy for example difficulty by relating it to learning consistency. Unfortunately, this method is quite compute intensive which limits its applicability for alternative datasets. In this work, we train models through different methods to predict C-Score for CIFAR-100 and CIFAR-10. We find, however, that these models generalize poorly both within the same distribution as well as out of distribution. This suggests that C-Score is not defined by the individual characteristics of each sample but rather by other factors. We hypothesize that a sample's relation to its neighbours, in particular, how many of them share the same labels, can help in explaining C-Scores. We plan to explore this in future work.
It's all About Consistency: A Study on Memory Composition for Replay-Based Methods in Continual Learning
Jul 04, 2022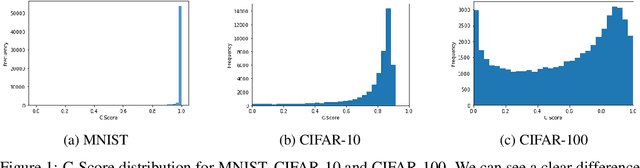

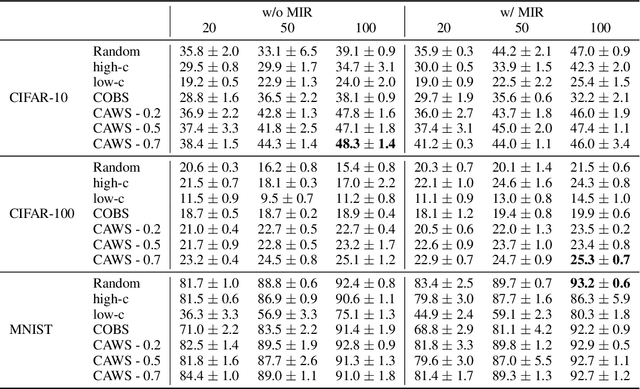
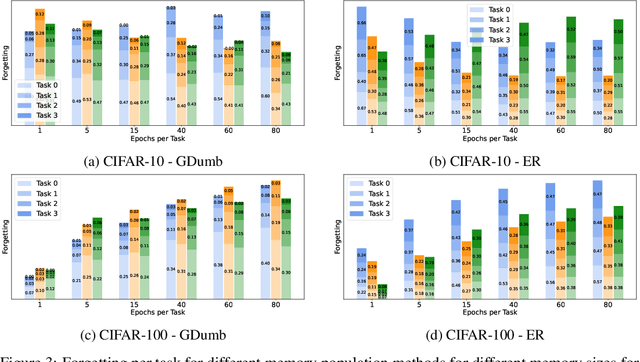
Continual Learning methods strive to mitigate Catastrophic Forgetting (CF), where knowledge from previously learned tasks is lost when learning a new one. Among those algorithms, some maintain a subset of samples from previous tasks when training. These samples are referred to as a memory. These methods have shown outstanding performance while being conceptually simple and easy to implement. Yet, despite their popularity, little has been done to understand which elements to be included into the memory. Currently, this memory is often filled via random sampling with no guiding principles that may aid in retaining previous knowledge. In this work, we propose a criterion based on the learning consistency of a sample called Consistency AWare Sampling (CAWS). This criterion prioritizes samples that are easier to learn by deep networks. We perform studies on three different memory-based methods: AGEM, GDumb, and Experience Replay, on MNIST, CIFAR-10 and CIFAR-100 datasets. We show that using the most consistent elements yields performance gains when constrained by a compute budget; when under no such constrain, random sampling is a strong baseline. However, using CAWS on Experience Replay yields improved performance over the random baseline. Finally, we show that CAWS achieves similar results to a popular memory selection method while requiring significantly less computational resources.
Optimizing Reusable Knowledge for Continual Learning via Metalearning
Jun 09, 2021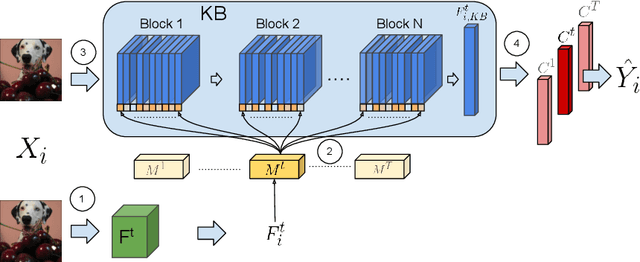

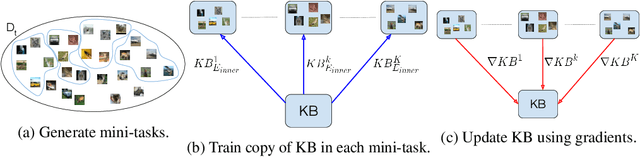

When learning tasks over time, artificial neural networks suffer from a problem known as Catastrophic Forgetting (CF). This happens when the weights of a network are overwritten during the training of a new task causing forgetting of old information. To address this issue, we propose MetA Reusable Knowledge or MARK, a new method that fosters weight reusability instead of overwriting when learning a new task. Specifically, MARK keeps a set of shared weights among tasks. We envision these shared weights as a common Knowledge Base (KB) that is not only used to learn new tasks, but also enriched with new knowledge as the model learns new tasks. Key components behind MARK are two-fold. On the one hand, a metalearning approach provides the key mechanism to incrementally enrich the KB with new knowledge and to foster weight reusability among tasks. On the other hand, a set of trainable masks provides the key mechanism to selectively choose from the KB relevant weights to solve each task. By using MARK, we achieve state of the art results in several popular benchmarks, surpassing the best performing methods in terms of average accuracy by over 10% on the 20-Split-MiniImageNet dataset, while achieving almost zero forgetfulness using 55% of the number of parameters. Furthermore, an ablation study provides evidence that, indeed, MARK is learning reusable knowledge that is selectively used by each task.