 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's all About Consistency: A Study on Memory Composition for Replay-Based Methods in Continual Learning
Paper and Code
Jul 04, 2022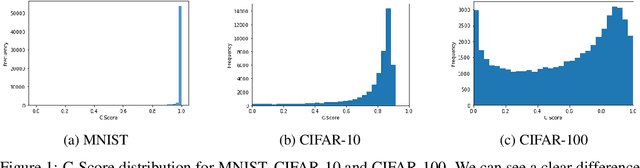

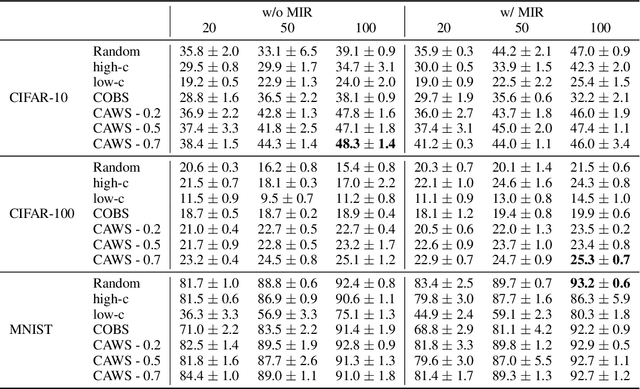
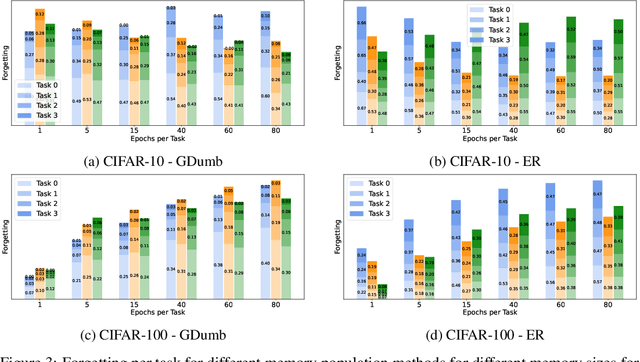
Continual Learning methods strive to mitigate Catastrophic Forgetting (CF), where knowledge from previously learned tasks is lost when learning a new one. Among those algorithms, some maintain a subset of samples from previous tasks when training. These samples are referred to as a memory. These methods have shown outstanding performance while being conceptually simple and easy to implement. Yet, despite their popularity, little has been done to understand which elements to be included into the memory. Currently, this memory is often filled via random sampling with no guiding principles that may aid in retaining previous knowledge. In this work, we propose a criterion based on the learning consistency of a sample called Consistency AWare Sampling (CAWS). This criterion prioritizes samples that are easier to learn by deep networks. We perform studies on three different memory-based methods: AGEM, GDumb, and Experience Replay, on MNIST, CIFAR-10 and CIFAR-100 datasets. We show that using the most consistent elements yields performance gains when constrained by a compute budget; when under no such constrain, random sampling is a strong baseline. However, using CAWS on Experience Replay yields improved performance over the random baseline. Finally, we show that CAWS achieves similar results to a popular memory selection method while requiring significantly less computational resources.