 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeInfinite: A Memory-Efficient Infinite-Context Transformer for Edge Devices
Mar 28, 2025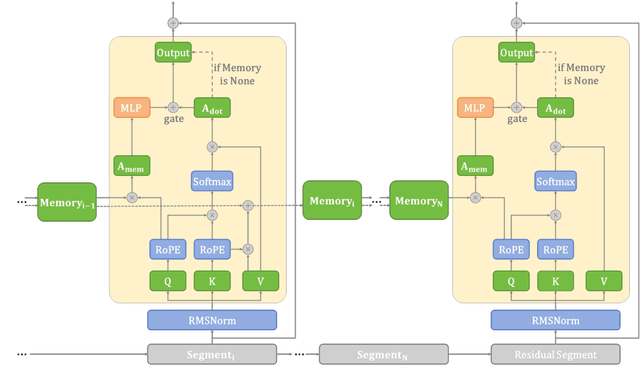
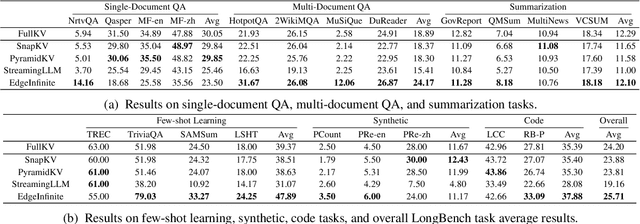
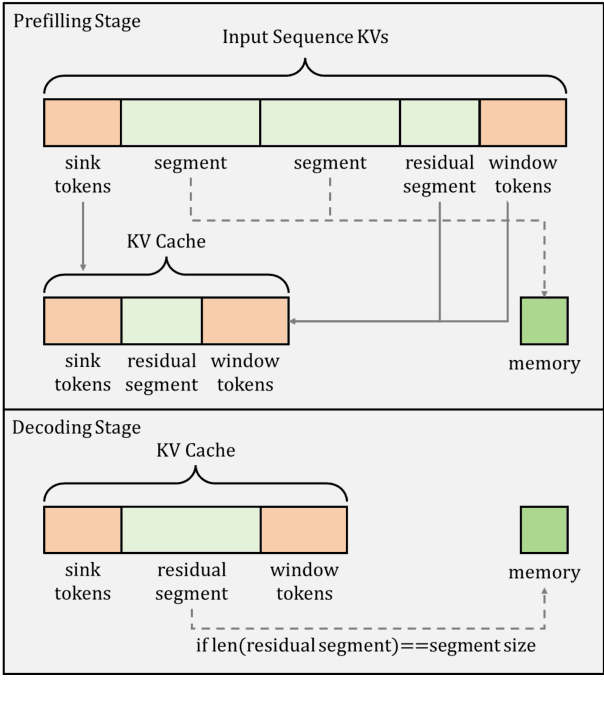
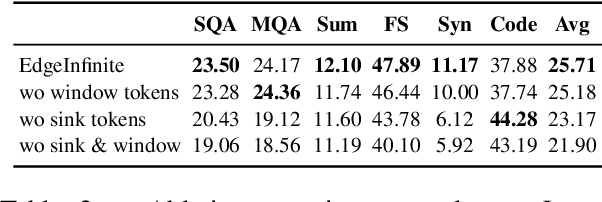
Transformer-based large language models (LLMs) encounter challenges in processing long sequences on edge devices due to the quadratic complexity of attention mechanisms and growing memory demands from Key-Value (KV) cache. Existing KV cache optimizations struggle with irreversible token eviction in long-output tasks, while alternative sequence modeling architectures prove costly to adopt within established Transformer infrastructure. We present EdgeInfinite, a memory-efficient solution for infinite contexts that integrates compressed memory into Transformer-based LLMs through a trainable memory-gating module. This approach maintains full compatibility with standard Transformer architectures, requiring fine-tuning only a small part of parameters, and enables selective activation of the memory-gating module for long and short context task routing. The experimental result shows that EdgeInfinite achieves comparable performance to baseline Transformer-based LLM on long context benchmarks while optimizing memory consumption and time to first token.
Root-KGD: A Novel Framework for Root Cause Diagnosis Based on Knowledge Graph and Industrial Data
Jun 19, 2024With the development of intelligent manufacturing and the increasing complexity of industrial production, root cause diagnosis has gradually become an important research direction in the field of industrial fault diagnosis. However, existing research methods struggle to effectively combine domain knowledge and industrial data, failing to provide accurate, online, and reliable root cause diagnosis results for industrial processes. To address these issues, a novel fault root cause diagnosis framework based on knowledge graph and industrial data, called Root-KGD, is proposed. Root-KGD uses the knowledge graph to represent domain knowledge and employs data-driven modeling to extract fault features from industrial data. It then combines the knowledge graph and data features to perform knowledge graph reasoning for root cause identification. The performance of the proposed method is validated using two industrial process cases, Tennessee Eastman Process (TEP) and Multiphase Flow Facility (MFF). Compared to existing methods, Root-KGD not only gives more accurate root cause variable diagnosis results but also provides interpretable fault-related information by locating faults to corresponding physical entities in knowledge graph (such as devices and streams). In addition, combined with its lightweight nature, Root-KGD is more effective in online industrial applications.
Agents: An Open-source Framework for Autonomous Language Agents
Sep 14, 2023Recent advances on large language models (LLMs) enable researchers and developers to build autonomous language agents that can automatically solve various tasks and interact with environments, humans, and other agents using natural language interfaces. We consider language agents as a promising direction towards artificial general intelligence and release Agents, an open-source library with the goal of opening up these advances to a wider non-specialist audience. Agents is carefully engineered to support important features including planning, memory, tool usage, multi-agent communication, and fine-grained symbolic control. Agents is user-friendly as it enables non-specialists to build, customize, test, tune, and deploy state-of-the-art autonomous language agents without much coding. The library is also research-friendly as its modularized design makes it easily extensible for researchers. Agents is available at https://github.com/aiwaves-cn/agents.
A bag-of-concepts model improves relation extraction in a narrow knowledge domain with limited data
Apr 24, 2019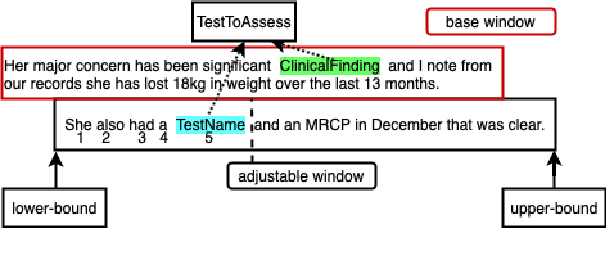
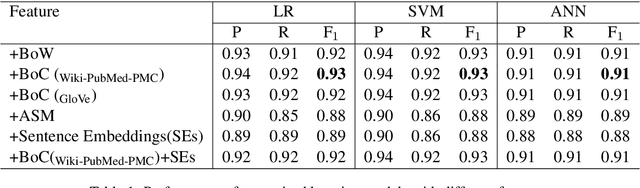
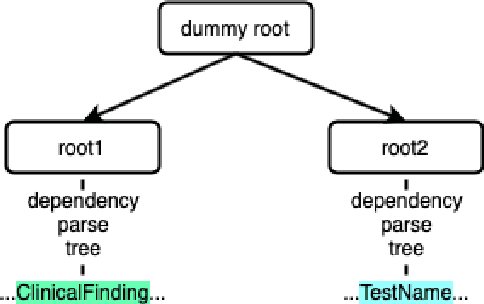
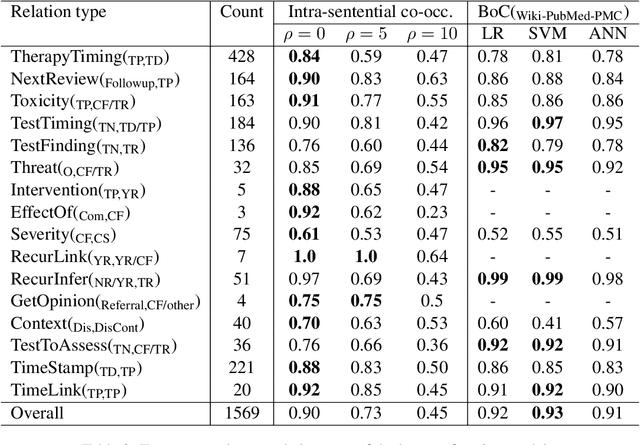
This paper focuses on a traditional relation extraction task in the context of limited annotated data and a narrow knowledge domain. We explore this task with a clinical corpus consisting of 200 breast cancer follow-up treatment letters in which 16 distinct types of relations are annotated. We experiment with an approach to extracting typed relations called window-bounded co-occurrence (WBC), which uses an adjustable context window around entity mentions of a relevant type, and compare its performance with a more typical intra-sentential co-occurrence baseline. We further introduce a new bag-of-concepts (BoC) approach to feature engineering based on the state-of-the-art word embeddings and word synonyms. We demonstrate the competitiveness of BoC by comparing with methods of higher complexity, and explore its effectiveness on this small dataset.
* To appear in Proceedings of the Student Research Workshop at the North American Association for Computational Linguistics (NAACL) meeting 2019
Less is More: Culling the Training Set to Improve Robustness of Deep Neural Networks
Jan 09, 2018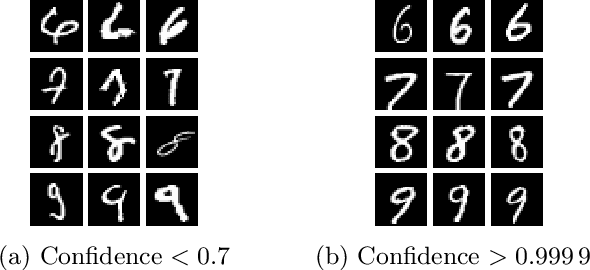

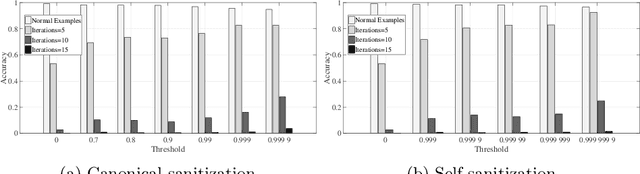
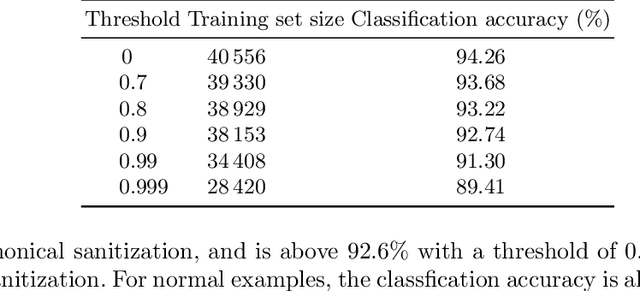
Deep neural networks are vulnerable to adversarial examples. Prior defenses attempted to make deep networks more robust by either improving the network architecture or adding adversarial examples into the training set, with their respective limitations. We propose a new direction. Motivated by recent research that shows that outliers in the training set have a high negative influence on the trained model, our approach makes the model more robust by detecting and removing outliers in the training set without modifying the network architecture or requiring adversarial examples. We propose two methods for detecting outliers based on canonical examples and on training errors, respectively. After removing the outliers, we train the classifier with the remaining examples to obtain a sanitized model. Our evaluation shows that the sanitized model improves classification accuracy and forces the attacks to generate adversarial examples with higher distortions. Moreover, the Kullback-Leibler divergence from the output of the original model to that of the sanitized model allows us to distinguish between normal and adversarial examples reliably.