 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed 4D X-ray image reconstruction from ultra-sparse spatiotemporal data
Apr 04, 2025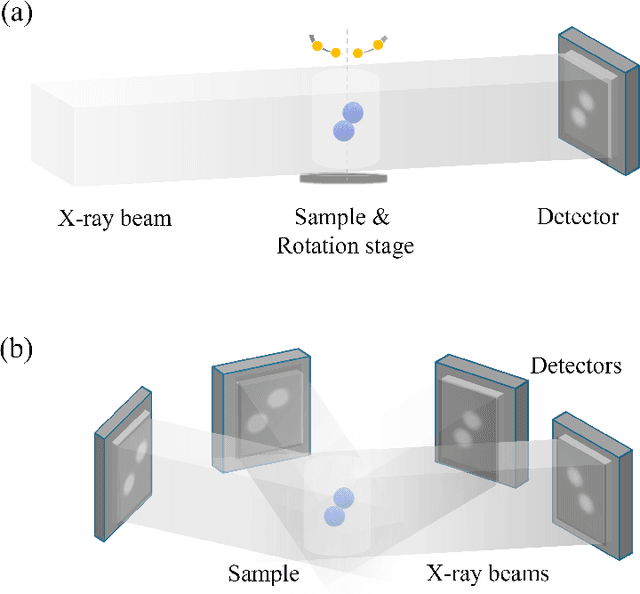

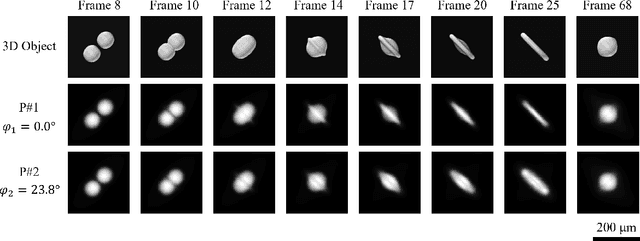
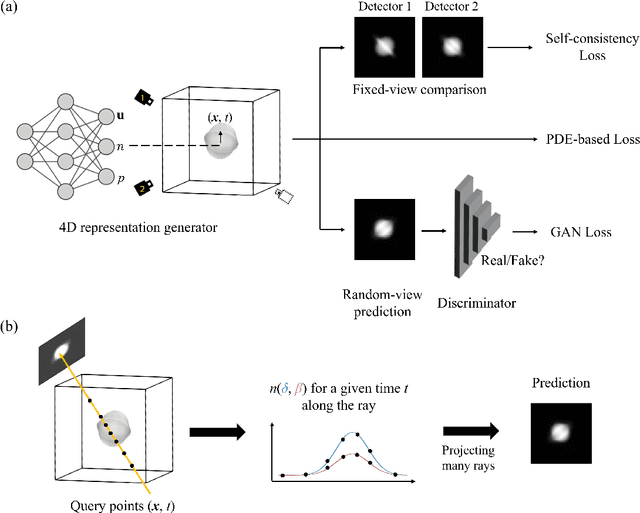
The unprecedented X-ray flux density provided by modern X-ray sources offers new spatiotemporal possibilities for X-ray imaging of fast dynamic processes. Approaches to exploit such possibilities often result in either i) a limited number of projections or spatial information due to limited scanning speed, as in time-resolved tomography, or ii) a limited number of time points, as in stroboscopic imaging, making the reconstruction problem ill-posed and unlikely to be solved by classical reconstruction approaches. 4D reconstruction from such data requires sample priors, which can be included via deep learning (DL). State-of-the-art 4D reconstruction methods for X-ray imaging combine the power of AI and the physics of X-ray propagation to tackle the challenge of sparse views. However, most approaches do not constrain the physics of the studied process, i.e., a full physical model. Here we present 4D physics-informed optimized neural implicit X-ray imaging (4D-PIONIX), a novel physics-informed 4D X-ray image reconstruction method combining the full physical model and a state-of-the-art DL-based reconstruction method for 4D X-ray imaging from sparse views. We demonstrate and evaluate the potential of our approach by retrieving 4D information from ultra-sparse spatiotemporal acquisitions of simulated binary droplet collisions, a relevant fluid dynamic process. We envision that this work will open new spatiotemporal possibilities for various 4D X-ray imaging modalities, such as time-resolved X-ray tomography and more novel sparse acquisition approaches like X-ray multi-projection imaging, which will pave the way for investigations of various rapid 4D dynamics, such as fluid dynamics and composite testing.
Beyond Color and Lines: Zero-Shot Style-Specific Image Variations with Coordinated Semantics
Oct 24, 2024



Traditionally, style has been primarily considered in terms of artistic elements such as colors, brushstrokes, and lighting. However, identical semantic subjects, like people, boats, and houses, can vary significantly across different artistic traditions, indicating that style also encompasses the underlying semantics. Therefore, in this study, we propose a zero-shot scheme for image variation with coordinated semantics. Specifically, our scheme transforms the image-to-image problem into an image-to-text-to-image problem. The image-to-text operation employs vision-language models e.g., BLIP) to generate text describing the content of the input image, including the objects and their positions. Subsequently, the input style keyword is elaborated into a detailed description of this style and then merged with the content text using the reasoning capabilities of ChatGPT. Finally, the text-to-image operation utilizes a Diffusion model to generate images based on the text prompt. To enable the Diffusion model to accommodate more styles, we propose a fine-tuning strategy that injects text and style constraints into cross-attention. This ensures that the output image exhibits similar semantics in the desired style. To validate the performance of the proposed scheme, we constructed a benchmark comprising images of various styles and scenes and introduced two novel metrics. Despite its simplicity, our scheme yields highly plausible results in a zero-shot manner, particularly for generating stylized images with high-fidelity semantics.
4D-ONIX: A deep learning approach for reconstructing 3D movies from sparse X-ray projections
Feb 02, 2024



The X-ray flux provided by X-ray free-electron lasers and storage rings offers new spatiotemporal possibilities to study in-situ and operando dynamics, even using single pulses of such facilities. X-ray Multi-Projection Imaging (XMPI) is a novel technique that enables volumetric information using single pulses of such facilities and avoids centrifugal forces induced by state-of-the-art time-resolved 3D methods such as time-resolved tomography. As a result, XMPI can acquire 3D movies (4D) at least three orders of magnitude faster than current methods. However, it is exceptionally challenging to reconstruct 4D from highly sparse projections as acquired by XMPI with current algorithms. Here, we present 4D-ONIX, a Deep Learning (DL)-based approach that learns to reconstruct 3D movies (4D) from an extremely limited number of projections. It combines the computational physical model of X-ray interaction with matter and state-of-the-art DL methods. We demonstrate the potential of 4D-ONIX to generate high-quality 4D by generalizing over multiple experiments with only two projections per timestamp for binary droplet collisions. We envision that 4D-ONIX will become an enabling tool for 4D analysis, offering new spatiotemporal resolutions to study processes not possible before.
Megahertz X-ray Multi-projection imaging
May 19, 2023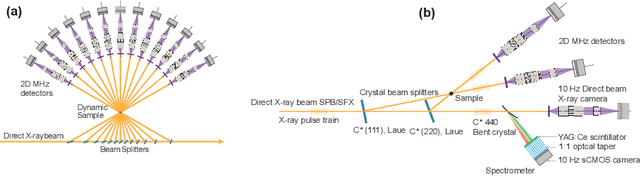
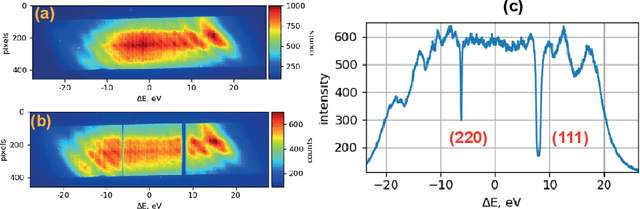

X-ray time-resolved tomography is one of the most popular X-ray techniques to probe dynamics in three dimensions (3D). Recent developments in time-resolved tomography opened the possibility of recording kilohertz-rate 3D movies. However, tomography requires rotating the sample with respect to the X-ray beam, which prevents characterization of faster structural dynamics. Here, we present megahertz (MHz) X-ray multi-projection imaging (MHz-XMPI), a technique capable of recording volumetric information at MHz rates and micrometer resolution without scanning the sample. We achieved this by harnessing the unique megahertz pulse structure and intensity of the European X-ray Free-electron Laser with a combination of novel detection and reconstruction approaches that do not require sample rotations. Our approach enables generating multiple X-ray probes that simultaneously record several angular projections for each pulse in the megahertz pulse burst. We provide a proof-of-concept demonstration of the MHz-XMPI technique's capability to probe 4D (3D+time) information on stochastic phenomena and non-reproducible processes three orders of magnitude faster than state-of-the-art time-resolved X-ray tomography, by generating 3D movies of binary droplet collisions. We anticipate that MHz-XMPI will enable in-situ and operando studies that were impossible before, either due to the lack of temporal resolution or because the systems were opaque (such as for MHz imaging based on optical microscopy).
EPCS: Endpoint-based Part-aware Curve Skeleton Extraction for Low-quality Point Clouds
Nov 17, 2022The curve skeleton is an important shape descriptor that has been utilized in various applications in computer graphics, machine vision, and artificial intelligence. In this study, the endpoint-based part-aware curve skeleton (EPCS) extraction method for low-quality point clouds is proposed. The novel random center shift (RCS) method is first proposed for detecting the endpoints on point clouds. The endpoints are used as the initial seed points for dividing each part into layers, and then the skeletal points are obtained by computing the center points of the oriented bounding box (OBB) of the layers. Subsequently, the skeletal points are connected, thus forming the branches. Furthermore, the multi-vector momentum-driven (MVMD) method is also proposed for locating the junction points that connect the branches. Due to the shape differences between different parts on point clouds, the global topology of the skeleton is finally optimized by removing the redundant junction points, re-connecting some branches using the proposed MVMD method, and applying an interpolation method based on the splitting operator. Consequently, a complete and smooth curve skeleton is achieved. The proposed EPCS method is compared with several state-of-the-art methods, and the experimental results verify its robustness, effectiveness, and efficiency. Furthermore, the skeleton extraction and model segmentation results on the point clouds of broken Terracotta also highlight the utility of the proposed method.
ONIX: an X-ray deep-learning tool for 3D reconstructions from sparse views
Mar 01, 2022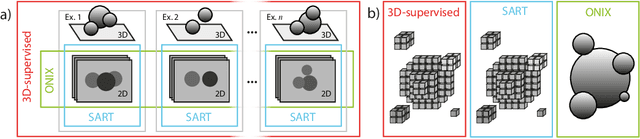

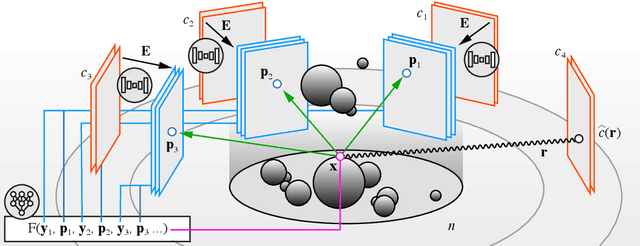
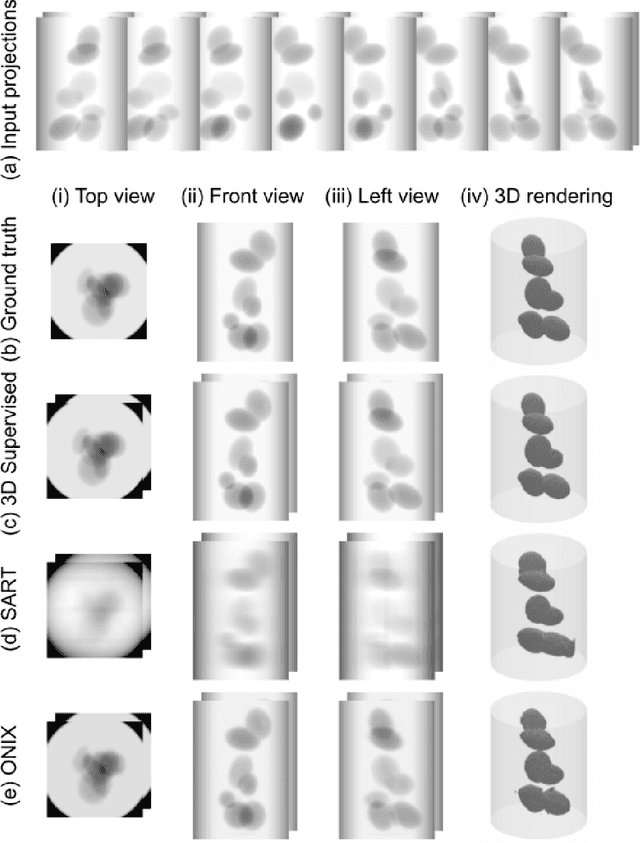
Three-dimensional (3D) X-ray imaging techniques like tomography and confocal microscopy are crucial for academic and industrial applications. These approaches access 3D information by scanning the sample with respect to the X-ray source. However, the scanning process limits the temporal resolution when studying dynamics and is not feasible for some applications, such as surgical guidance in medical applications. Alternatives to obtaining 3D information when scanning is not possible are X-ray stereoscopy and multi-projection imaging. However, these approaches suffer from limited volumetric information as they only acquire a small number of views or projections compared to traditional 3D scanning techniques. Here, we present ONIX (Optimized Neural Implicit X-ray imaging), a deep-learning algorithm capable of retrieving 3D objects with arbitrary large resolution from only a set of sparse projections. ONIX, although it does not have access to any volumetric information, outperforms current 3D reconstruction approaches because it includes the physics of image formation with X-rays, and it generalizes across different experiments over similar samples to overcome the limited volumetric information provided by sparse views. We demonstrate the capabilities of ONIX compared to state-of-the-art tomographic reconstruction algorithms by applying it to simulated and experimental datasets, where a maximum of eight projections are acquired. We anticipate that ONIX will become a crucial tool for the X-ray community by i) enabling the study of fast dynamics not possible today when implemented together with X-ray multi-projection imaging, and ii) enhancing the volumetric information and capabilities of X-ray stereoscopic imaging in medical applications.