 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentPS: Agentic Process Supervision for Multi-modal Content Quality Assurance through Multi-round QA
Dec 15, 2024



The advanced processing and reasoning capabilities of multimodal large language models (MLLMs) have driven substantial progress in vision-language (VL) understanding tasks. However, while effective for tasks governed by straightforward logic, MLLMs often encounter challenges when reasoning over complex, interdependent logic structures. To address this limitation, we introduce \textit{AgentPS}, a novel framework that integrates Agentic Process Supervision into MLLMs via multi-round question answering during fine-tuning. \textit{AgentPS} demonstrates significant performance improvements over baseline MLLMs on proprietary TikTok datasets, due to its integration of process supervision and structured sequential reasoning. Furthermore, we show that replacing human-annotated labels with LLM-generated labels retains much of the performance gain, highlighting the framework's practical scalability in industrial applications. These results position \textit{AgentPS} as a highly effective and efficient architecture for multimodal classification tasks. Its adaptability and scalability, especially when enhanced by automated annotation generation, make it a powerful tool for handling large-scale, real-world challenges.
Improving Language Generation with Sentence Coherence Objective
Sep 07, 2020
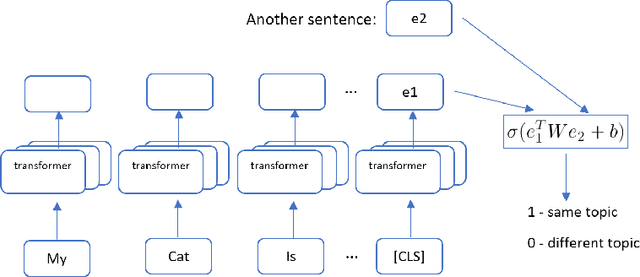

Conditional story generation and contextual text continuation have become increasingly popular topics in NLP community. Existing models are often prone to output paragraphs of texts that gradually diverge from the given prompt. Although the generated text may have a reasonable perplexity and diversity, it could easily be identified by human as gibberish. The goal of our project is to improve the coherence and consistency across sentences in a language-generation model. We aim to solve this issue by first training a sentence pair coherence classifier with GPT-2 pretrained model, and then co-train the GPT-2 language model with this new coherence objective using a method analogous to the REINFORCE algorithm. This fine-tuned language model is able to generate lengthy paragraph conditioned on a given topic without diverging too much. The simplicity of this model allows it to be applicable to a variety of underlying language model architecture since it only modifies the final layer of the pre-trained model.
Transferable Natural Language Interface to Structured Queries aided by Adversarial Generation
Dec 07, 2018



A natural language interface (NLI) to structured query is intriguing due to its wide industrial applications and high economical values. In this work, we tackle the problem of domain adaptation for NLI with limited data on target domain. Two important approaches are considered: (a) effective general-knowledge-learning on source domain semantic parsing, and (b) data augmentation on target domain. We present a Structured Query Inference Network (SQIN) to enhance learning for domain adaptation, by separating schema information from NL and decoding SQL in a more structural-aware manner; we also propose a GAN-based augmentation technique (AugmentGAN) to mitigate the issue of lacking target domain data. We report solid results on GeoQuery, Overnight, and WikiSQL to demonstrate state-of-the-art performances for both in-domain and domain-transfer tasks.