 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Language Generation with Sentence Coherence Objective
Sep 07, 2020
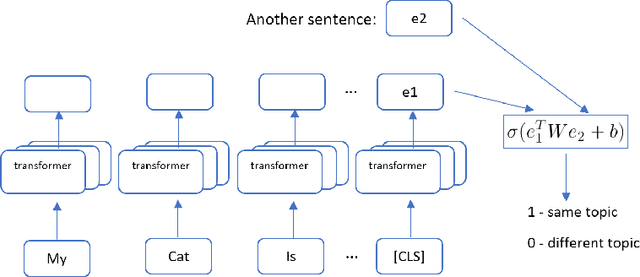

Conditional story generation and contextual text continuation have become increasingly popular topics in NLP community. Existing models are often prone to output paragraphs of texts that gradually diverge from the given prompt. Although the generated text may have a reasonable perplexity and diversity, it could easily be identified by human as gibberish. The goal of our project is to improve the coherence and consistency across sentences in a language-generation model. We aim to solve this issue by first training a sentence pair coherence classifier with GPT-2 pretrained model, and then co-train the GPT-2 language model with this new coherence objective using a method analogous to the REINFORCE algorithm. This fine-tuned language model is able to generate lengthy paragraph conditioned on a given topic without diverging too much. The simplicity of this model allows it to be applicable to a variety of underlying language model architecture since it only modifies the final layer of the pre-trained model.
Real-Time Well Log Prediction From Drilling Data Using Deep Learning
Jan 28, 2020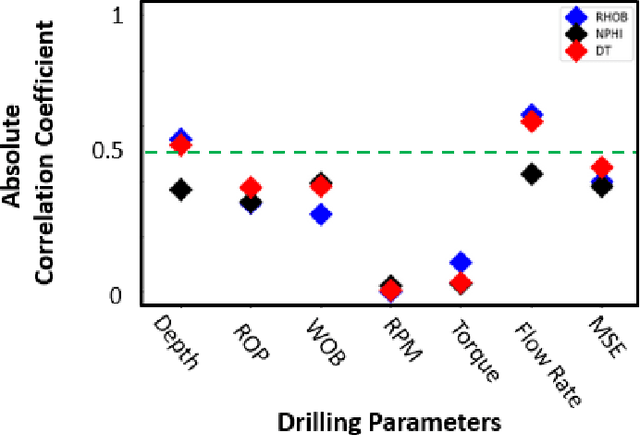


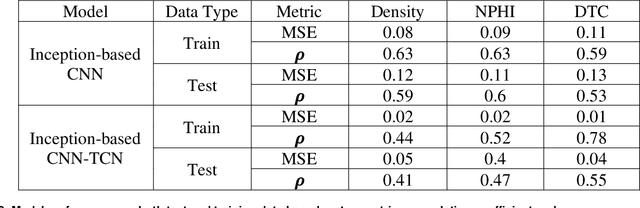
The objective is to study the feasibility of predicting subsurface rock properties in wells from real-time drilling data. Geophysical logs, namely, density, porosity and sonic logs are of paramount importance for subsurface resource estimation and exploitation. These wireline petro-physical measurements are selectively deployed as they are expensive to acquire; meanwhile, drilling information is recorded in every drilled well. Hence a predictive tool for wireline log prediction from drilling data can help management make decisions about data acquisition, especially for delineation and production wells. This problem is non-linear with strong ineractions between drilling parameters; hence the potential for deep learning to address this problem is explored. We present a workflow for data augmentation and feature engineering using Distance-based Global Sensitivity Analysis. We propose an Inception-based Convolutional Neural Network combined with a Temporal Convolutional Network as the deep learning model. The model is designed to learn both low and high frequency content of the data. 12 wells from the Equinor dataset for the Volve field in the North Sea are used for learning. The model predictions not only capture trends but are also physically consistent across density, porosity, and sonic logs. On the test data, the mean square error reaches a low value of 0.04 but the correlation coefficient plateaus around 0.6. The model is able however to differentiate between different types of rocks such as cemented sandstone, unconsolidated sands, and shale.