 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π$, But Make It Fly: Physics-Guided Transfer of VLA Models to Aerial Manipulation
Mar 26, 2026Vision-Language-Action (VLA) models such as $π_0$ have demonstrated remarkable generalization across diverse fixed-base manipulators. However, transferring these foundation models to aerial platforms remains an open challenge due to the fundamental mismatch between the quasi-static dynamics of fixed-base arms and the underactuated, highly dynamic nature of flight. In this work, we introduce AirVLA, a system that investigates the transferability of manipulation-pretrained VLAs to aerial pick-and-place tasks. We find that while visual representations transfer effectively, the specific control dynamics required for flight do not. To bridge this "dynamics gap" without retraining the foundation model, we introduce a Payload-Aware Guidance mechanism that injects payload constraints directly into the policy's flow-matching sampling process. To overcome data scarcity, we further utilize a Gaussian Splatting pipeline to synthesize navigation training data. We evaluate our method through a cumulative 460 real-world experiments which demonstrate that this synthetic data is a key enabler of performance, unlocking 100% success in navigation tasks where directly fine-tuning on teleoperation data alone attains 81% success. Our inference-time intervention, Payload-Aware Guidance, increases real-world pick-and-place task success from 23% to 50%. Finally, we evaluate the model on a long-horizon compositional task, achieving a 62% overall success rate. These results suggest that pre-trained manipulation VLAs, with appropriate data augmentation and physics-informed guidance, can transfer to aerial manipulation and navigation, as well as the composition of these tasks.
BountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems
May 21, 2025AI agents have the potential to significantly alter the cybersecurity landscape. To help us understand this change, we introduce the first framework to capture offensive and defensive cyber-capabilities in evolving real-world systems. Instantiating this framework with BountyBench, we set up 25 systems with complex, real-world codebases. To capture the vulnerability lifecycle, we define three task types: Detect (detecting a new vulnerability), Exploit (exploiting a specific vulnerability), and Patch (patching a specific vulnerability). For Detect, we construct a new success indicator, which is general across vulnerability types and provides localized evaluation. We manually set up the environment for each system, including installing packages, setting up server(s), and hydrating database(s). We add 40 bug bounties, which are vulnerabilities with monetary awards from \$10 to \$30,485, and cover 9 of the OWASP Top 10 Risks. To modulate task difficulty, we devise a new strategy based on information to guide detection, interpolating from identifying a zero day to exploiting a specific vulnerability. We evaluate 5 agents: Claude Code, OpenAI Codex CLI, and custom agents with GPT-4.1, Gemini 2.5 Pro Preview, and Claude 3.7 Sonnet Thinking. Given up to three attempts, the top-performing agents are Claude Code (5% on Detect, mapping to \$1,350), Custom Agent with Claude 3.7 Sonnet Thinking (5% on Detect, mapping to \$1,025; 67.5% on Exploit), and OpenAI Codex CLI (5% on Detect, mapping to \$2,400; 90% on Patch, mapping to \$14,422). OpenAI Codex CLI and Claude Code are more capable at defense, achieving higher Patch scores of 90% and 87.5%, compared to Exploit scores of 32.5% and 57.5% respectively; in contrast, the custom agents are relatively balanced between offense and defense, achieving Exploit scores of 40-67.5% and Patch scores of 45-60%.
"Task Success" is not Enough: Investigating the Use of Video-Language Models as Behavior Critics for Catching Undesirable Agent Behaviors
Feb 06, 2024Large-scale generative models are shown to be useful for sampling meaningful candidate solutions, yet they often overlook task constraints and user preferences. Their full power is better harnessed when the models are coupled with external verifiers and the final solutions are derived iteratively or progressively according to the verification feedback. In the context of embodied AI, verification often solely involves assessing whether goal conditions specified in the instructions have been met. Nonetheless, for these agents to be seamlessly integrated into daily life, it is crucial to account for a broader range of constraints and preferences beyond bare task success (e.g., a robot should grasp bread with care to avoid significant deformations). However, given the unbounded scope of robot tasks, it is infeasible to construct scripted verifiers akin to those used for explicit-knowledge tasks like the game of Go and theorem proving. This begs the question: when no sound verifier is available, can we use large vision and language models (VLMs), which are approximately omniscient, as scalable Behavior Critics to catch undesirable robot behaviors in videos? To answer this, we first construct a benchmark that contains diverse cases of goal-reaching yet undesirable robot policies. Then, we comprehensively evaluate VLM critics to gain a deeper understanding of their strengths and failure modes. Based on the evaluation, we provide guidelines on how to effectively utilize VLM critiques and showcase a practical way to integrate the feedback into an iterative process of policy refinement. The dataset and codebase are released at: https://guansuns.github.io/pages/vlm-critic.
A Systematic Study on Quantifying Bias in GAN-Augmented Data
Aug 23, 2023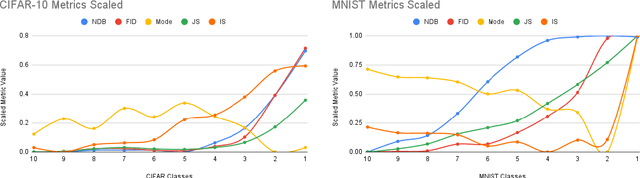
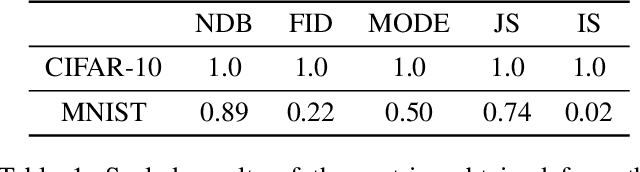
Generative adversarial networks (GANs) have recently become a popular data augmentation technique used by machine learning practitioners. However, they have been shown to suffer from the so-called mode collapse failure mode, which makes them vulnerable to exacerbating biases on already skewed datasets, resulting in the generated data distribution being less diverse than the training distribution. To this end, we address the problem of quantifying the extent to which mode collapse occurs. This study is a systematic effort focused on the evaluation of state-of-the-art metrics that can potentially quantify biases in GAN-augmented data. We show that, while several such methods are available, there is no single metric that quantifies bias exacerbation reliably over the span of different image domains.