 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gradient-based Bilevel Optimization Approach for Tuning Hyperparameters in Machine Learning
Paper and Code
Jul 21, 2020
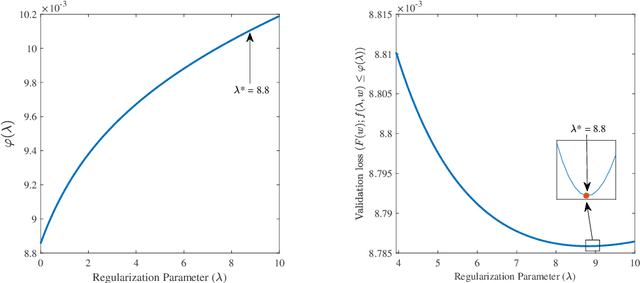
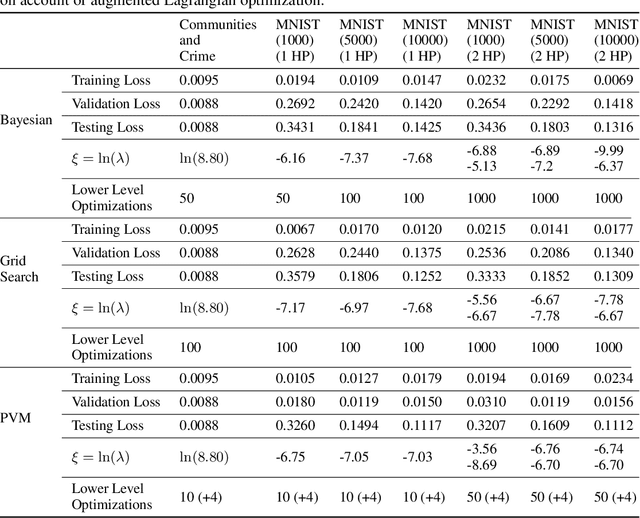
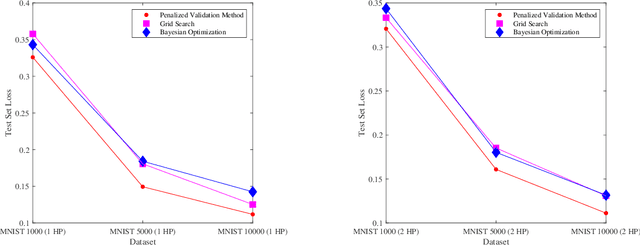
Hyperparameter tuning is an active area of research in machine learning, where the aim is to identify the optimal hyperparameters that provide the best performance on the validation set. Hyperparameter tuning is often achieved using naive techniques, such as random search and grid search. However, most of these methods seldom lead to an optimal set of hyperparameters and often get very expensive. In this paper, we propose a bilevel solution method for solving the hyperparameter optimization problem that does not suffer from the drawbacks of the earlier studies. The proposed method is general and can be easily applied to any class of machine learning algorithms. The idea is based on the approximation of the lower level optimal value function mapping, which is an important mapping in bilevel optimization and helps in reducing the bilevel problem to a single level constrained optimization task. The single-level constrained optimization problem is solved using the augmented Lagrangian method. We discuss the theory behind the proposed algorithm and perform extensive computational study on two datasets that confirm the efficiency of the proposed method. We perform a comparative study against grid search, random search and Bayesian optimization techniques that shows that the proposed algorithm is multiple times faster on problems with one or two hyperparameters. The computational gain is expected to be significantly higher as the number of hyperparameters increase. Corresponding to a given hyperparameter most of the techniques in the literature often assume a unique optimal parameter set that minimizes loss on the training set. Such an assumption is often violated by deep learning architectures and the proposed method does not require any such assumption.