 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Improving Adaptivity in Conformal Prediction through Input Transformations
Nov 17, 2025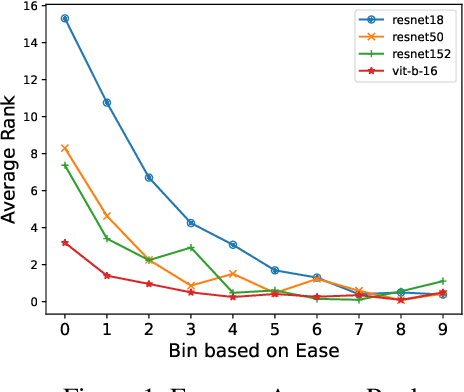
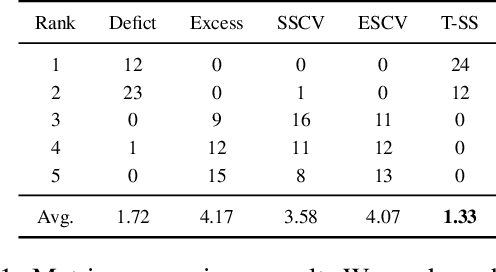
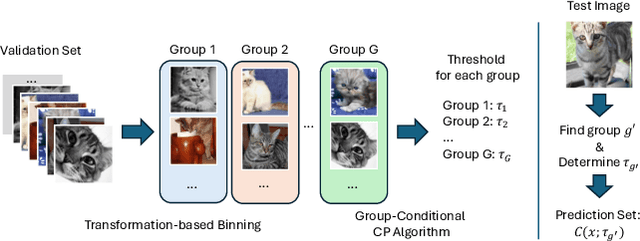
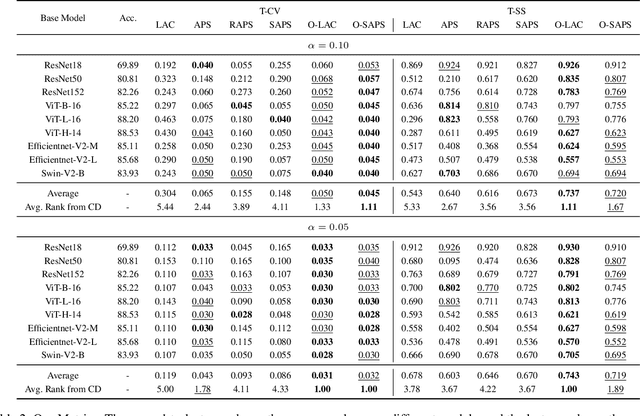
Conformal prediction constructs a set of labels instead of a single point prediction, while providing a probabilistic coverage guarantee. Beyond the coverage guarantee, adaptiveness to example difficulty is an important property. It means that the method should produce larger prediction sets for more difficult examples, and smaller ones for easier examples. Existing evaluation methods for adaptiveness typically analyze coverage rate violation or average set size across bins of examples grouped by difficulty. However, these approaches often suffer from imbalanced binning, which can lead to inaccurate estimates of coverage or set size. To address this issue, we propose a binning method that leverages input transformations to sort examples by difficulty, followed by uniform-mass binning. Building on this binning, we introduce two metrics to better evaluate adaptiveness. These metrics provide more reliable estimates of coverage rate violation and average set size due to balanced binning, leading to more accurate adaptivity assessment. Through experiments, we demonstrate that our proposed metric correlates more strongly with the desired adaptiveness property compared to existing ones. Furthermore, motivated by our findings, we propose a new adaptive prediction set algorithm that groups examples by estimated difficulty and applies group-conditional conformal prediction. This allows us to determine appropriate thresholds for each group. Experimental results on both (a) an Image Classification (ImageNet) (b) a medical task (visual acuity prediction) show that our method outperforms existing approaches according to the new metrics.
Conformal Constrained Policy Optimization for Cost-Effective LLM Agents
Nov 14, 2025While large language models (LLMs) have recently made tremendous progress towards solving challenging AI problems, they have done so at increasingly steep computational and API costs. We propose a novel strategy where we combine multiple LLM models with varying cost/accuracy tradeoffs in an agentic manner, where models and tools are run in sequence as determined by an orchestration model to minimize cost subject to a user-specified level of reliability; this constraint is formalized using conformal prediction to provide guarantees. To solve this problem, we propose Conformal Constrained Policy Optimization (CCPO), a training paradigm that integrates constrained policy optimization with off-policy reinforcement learning and recent advances in online conformal prediction. CCPO jointly optimizes a cost-aware policy (score function) and an adaptive threshold. Across two multi-hop question answering benchmarks, CCPO achieves up to a 30% cost reduction compared to other cost-aware baselines and LLM-guided methods without compromising reliability. Our approach provides a principled and practical framework for deploying LLM agents that are significantly more cost-effective while maintaining reliability.
Fundus Image-based Visual Acuity Assessment with PAC-Guarantees
Dec 09, 2024Timely detection and treatment are essential for maintaining eye health. Visual acuity (VA), which measures the clarity of vision at a distance, is a crucial metric for managing eye health. Machine learning (ML) techniques have been introduced to assist in VA measurement, potentially alleviating clinicians' workloads. However, the inherent uncertainties in ML models make relying solely on them for VA prediction less than ideal. The VA prediction task involves multiple sources of uncertainty, requiring more robust approaches. A promising method is to build prediction sets or intervals rather than point estimates, offering coverage guarantees through techniques like conformal prediction and Probably Approximately Correct (PAC) prediction sets. Despite the potential, to date, these approaches have not been applied to the VA prediction task.To address this, we propose a method for deriving prediction intervals for estimating visual acuity from fundus images with a PAC guarantee. Our experimental results demonstrate that the PAC guarantees are upheld, with performance comparable to or better than that of two prior works that do not provide such guarantees.
Confidence Calibration with Bounded Error Using Transformations
Feb 25, 2021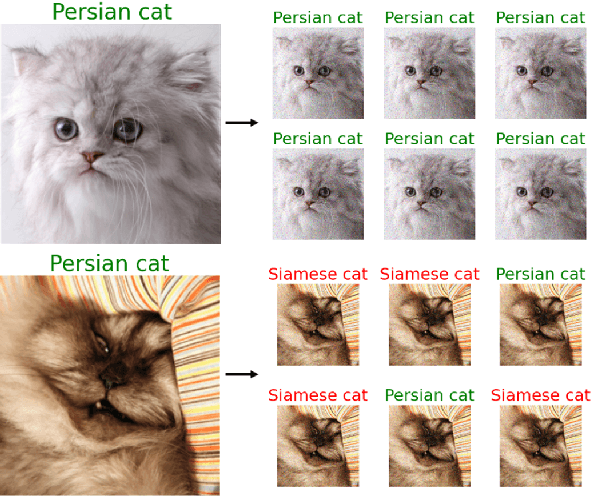
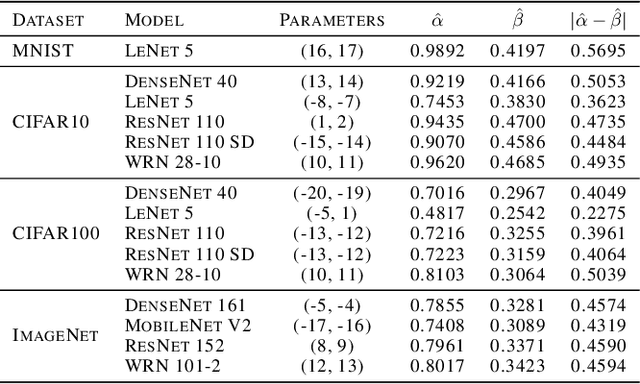


As machine learning techniques become widely adopted in new domains, especially in safety-critical systems such as autonomous vehicles, it is crucial to provide accurate output uncertainty estimation. As a result, many approaches have been proposed to calibrate neural networks to accurately estimate the likelihood of misclassification. However, while these methods achieve low expected calibration error (ECE), few techniques provide theoretical performance guarantees on the calibration error (CE). In this paper, we introduce Hoki, a novel calibration algorithm with a theoretical bound on the CE. Hoki works by transforming the neural network logits and/or inputs and recursively performing calibration leveraging the information from the corresponding change in the output. We provide a PAC-like bounds on CE that is shown to decrease with the number of samples used for calibration, and increase proportionally with ECE and the number of discrete bins used to calculate ECE. We perform experiments on multiple datasets, including ImageNet, and show that the proposed approach generally outperforms state-of-the-art calibration algorithms across multiple datasets and models - providing nearly an order or magnitude improvement in ECE on ImageNet. In addition, Hoki is fast algorithm which is comparable to temperature scaling in terms of learning time.
Improving Classifier Confidence using Lossy Label-Invariant Transformations
Nov 09, 2020

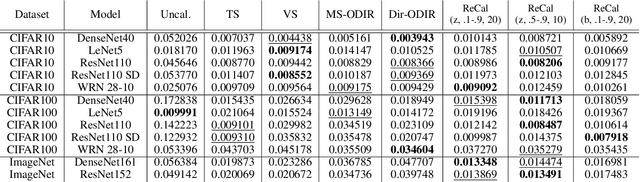

Providing reliable model uncertainty estimates is imperative to enabling robust decision making by autonomous agents and humans alike. While recently there have been significant advances in confidence calibration for trained models, examples with poor calibration persist in most calibrated models. Consequently, multiple techniques have been proposed that leverage label-invariant transformations of the input (i.e., an input manifold) to improve worst-case confidence calibration. However, manifold-based confidence calibration techniques generally do not scale and/or require expensive retraining when applied to models with large input spaces (e.g., ImageNet). In this paper, we present the recursive lossy label-invariant calibration (ReCal) technique that leverages label-invariant transformations of the input that induce a loss of discriminatory information to recursively group (and calibrate) inputs - without requiring model retraining. We show that ReCal outperforms other calibration methods on multiple datasets, especially, on large-scale datasets such as ImageNet.
VisionGuard: Runtime Detection of Adversarial Inputs to Perception Systems
Feb 23, 2020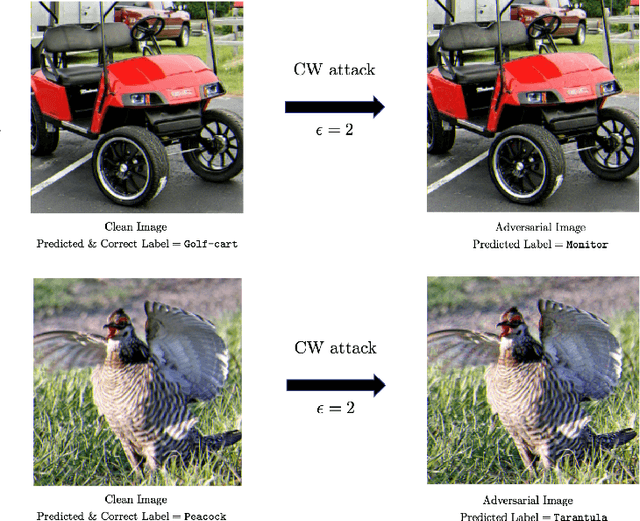
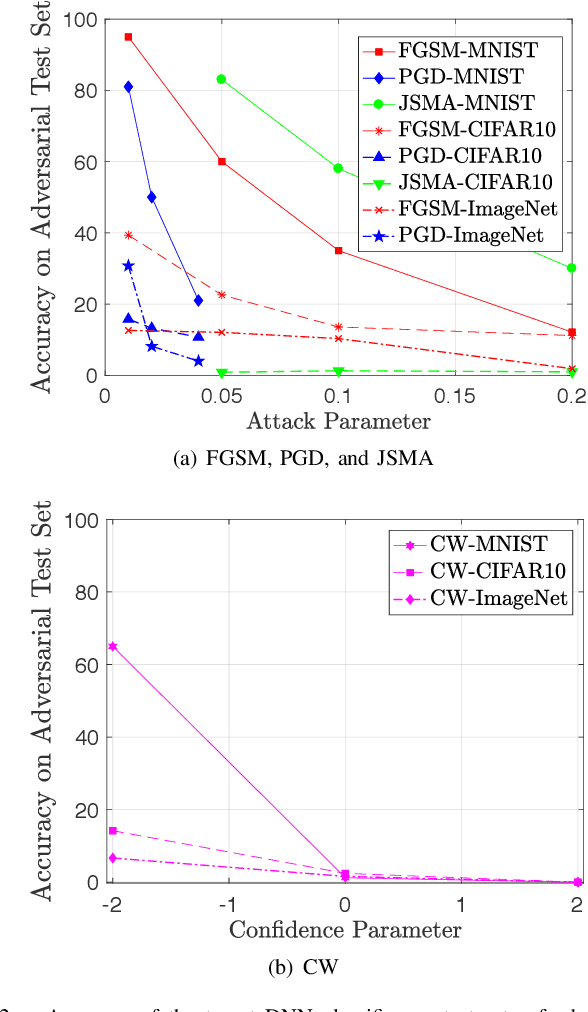
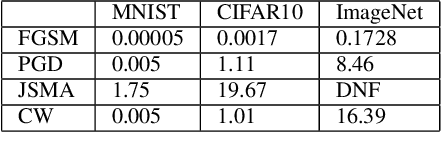
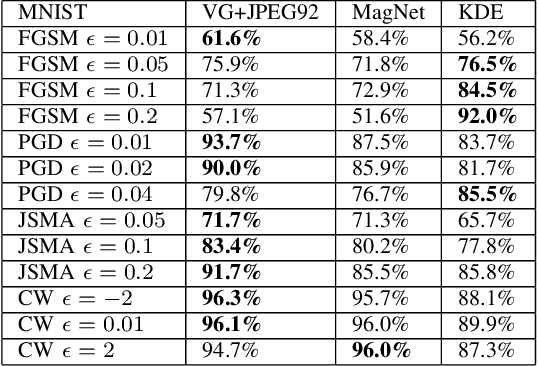
Deep neural network (DNN) models have proven to be vulnerable to adversarial attacks. In this paper, we propose VisionGuard, a novel attack- and dataset-agnostic and computationally-light defense mechanism for adversarial inputs to DNN-based perception systems. In particular, VisionGuard relies on the observation that adversarial images are sensitive to lossy compression transformations. Specifically, to determine if an image is adversarial, VisionGuard checks if the output of the target classifier on a given input image changes significantly after feeding it a transformed version of the image under investigation. Moreover, we show that VisionGuard is computationally-light both at runtime and design-time which makes it suitable for real-time applications that may also involve large-scale image domains. To highlight this, we demonstrate the efficiency of VisionGuard on ImageNet, a task that is computationally challenging for the majority of relevant defenses. Finally, we include extensive comparative experiments on the MNIST, CIFAR10, and ImageNet datasets that show that VisionGuard outperforms existing defenses in terms of scalability and detection performance.