 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Alternative Techniques for Improving Adversarial Robustness: Analysis of Adversarial Training at a Spectrum of Perturbations
Paper and Code
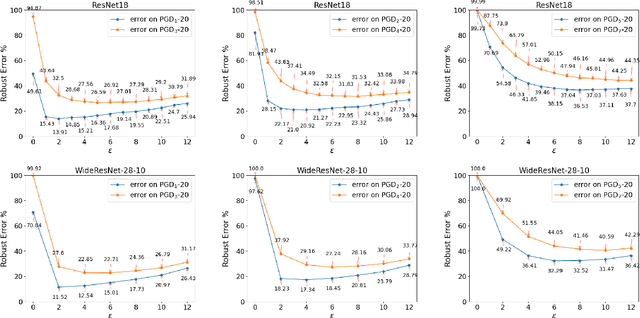
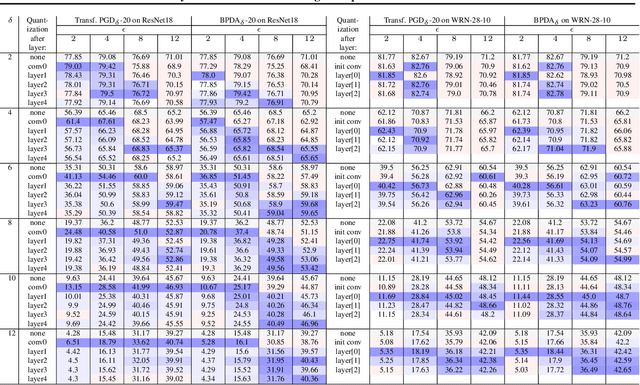
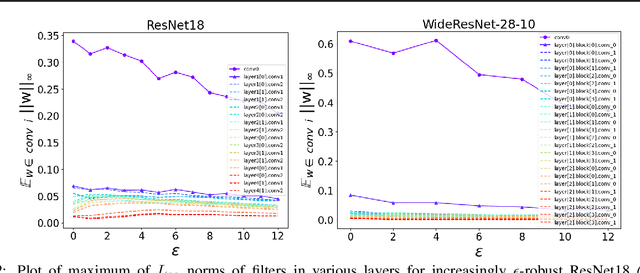
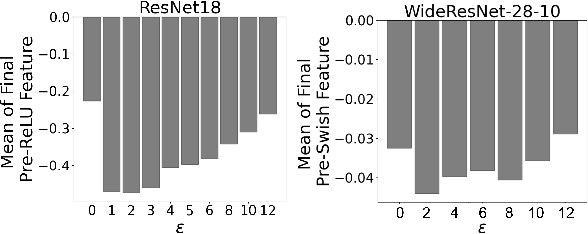
Adversarial training (AT) and its variants have spearheaded progress in improving neural network robustness to adversarial perturbations and common corruptions in the last few years. Algorithm design of AT and its variants are focused on training models at a specified perturbation strength $\epsilon$ and only using the feedback from the performance of that $\epsilon$-robust model to improve the algorithm. In this work, we focus on models, trained on a spectrum of $\epsilon$ values. We analyze three perspectives: model performance, intermediate feature precision and convolution filter sensitivity. In each, we identify alternative improvements to AT that otherwise wouldn't have been apparent at a single $\epsilon$. Specifically, we find that for a PGD attack at some strength $\delta$, there is an AT model at some slightly larger strength $\epsilon$, but no greater, that generalizes best to it. Hence, we propose overdesigning for robustness where we suggest training models at an $\epsilon$ just above $\delta$. Second, we observe (across various $\epsilon$ values) that robustness is highly sensitive to the precision of intermediate features and particularly those after the first and second layer. Thus, we propose adding a simple quantization to defenses that improves accuracy on seen and unseen adaptive attacks. Third, we analyze convolution filters of each layer of models at increasing $\epsilon$ and notice that those of the first and second layer may be solely responsible for amplifying input perturbations. We present our findings and demonstrate our techniques through experiments with ResNet and WideResNet models on the CIFAR-10 and CIFAR-10-C datasets.