 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonical Cortical Graph Neural Networks and its Application for Speech Enhancement in Future Audio-Visual Hearing Aids
Paper and Code
Jun 06, 2022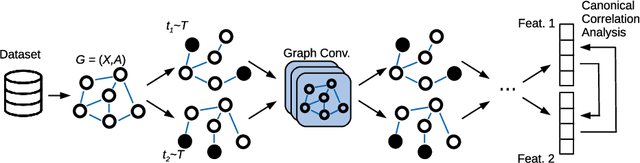
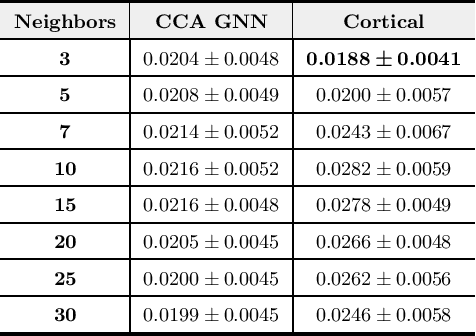
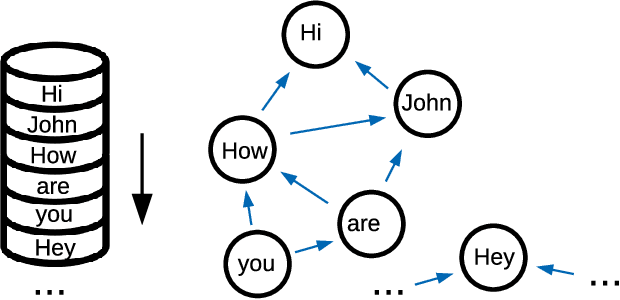
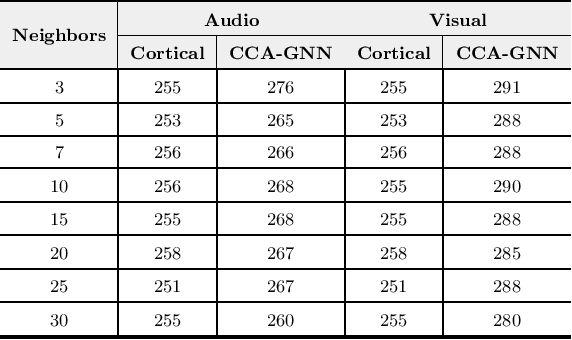
Despite the recent success of machine learning algorithms, most of these models still face several drawbacks when considering more complex tasks requiring interaction between different sources, such as multimodal input data and logical time sequence. On the other hand, the biological brain is highly sharpened in this sense, empowered to automatically manage and integrate such a stream of information through millions of years of evolution. In this context, this paper finds inspiration from recent discoveries on cortical circuits in the brain to propose a more biologically plausible self-supervised machine learning approach that combines multimodal information using intra-layer modulations together with canonical correlation analysis (CCA), as well as a memory mechanism to keep track of temporal data, the so-called Canonical Cortical Graph Neural networks. The approach outperformed recent state-of-the-art results considering both better clean audio reconstruction and energy efficiency, described by a reduced and smother neuron firing rate distribution, suggesting the model as a suitable approach for speech enhancement in future audio-visual hearing aid devices.