 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D mesh convolution-based autoencoder for geometry compression
Mar 02, 2026In this paper, we introduce a novel 3D mesh convolution-based autoencoder for geometry compression, able to deal with irregular mesh data without requiring neither preprocessing nor manifold/watertightness conditions. The proposed approach extracts meaningful latent representations by learning features directly from the mesh faces, while preserving connectivity through dedicated pooling and unpooling operations. The encoder compresses the input mesh into a compact base mesh space, which ensures that the latent space remains comparable. The decoder reconstructs the original connectivity and restores the compressed geometry to its full resolution. Extensive experiments on multi-class datasets demonstrate that our method outperforms state-of-the-art approaches in both 3D mesh geometry reconstruction and latent space classification tasks. Code available at: github.com/germainGB/MeshConv3D
Variational Contrastive Learning for Skeleton-based Action Recognition
Jan 12, 2026In recent years, self-supervised representation learning for skeleton-based action recognition has advanced with the development of contrastive learning methods. However, most of contrastive paradigms are inherently discriminative and often struggle to capture the variability and uncertainty intrinsic to human motion. To address this issue, we propose a variational contrastive learning framework that integrates probabilistic latent modeling with contrastive self-supervised learning. This formulation enables the learning of structured and semantically meaningful representations that generalize across different datasets and supervision levels. Extensive experiments on three widely used skeleton-based action recognition benchmarks show that our proposed method consistently outperforms existing approaches, particularly in low-label regimes. Moreover, qualitative analyses show that the features provided by our method are more relevant given the motion and sample characteristics, with more focus on important skeleton joints, when compared to the other methods.
Refining Gaussian Splatting: A Volumetric Densification Approach
Aug 07, 2025
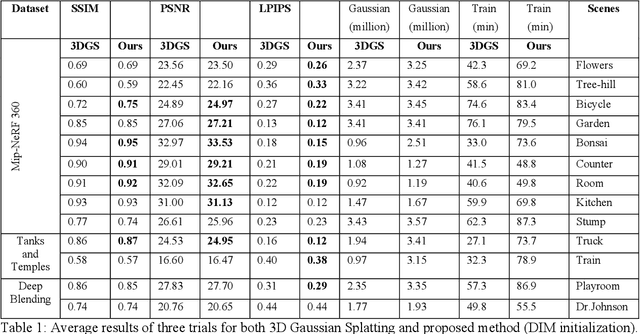

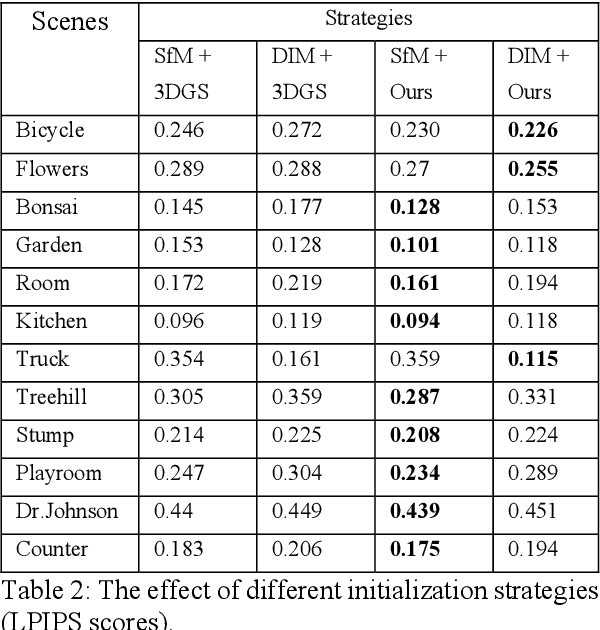
Achieving high-quality novel view synthesis in 3D Gaussian Splatting (3DGS) often depends on effective point primitive management. The underlying Adaptive Density Control (ADC) process addresses this issue by automating densification and pruning. Yet, the vanilla 3DGS densification strategy shows key shortcomings. To address this issue, in this paper we introduce a novel density control method, which exploits the volumes of inertia associated to each Gaussian function to guide the refinement process. Furthermore, we study the effect of both traditional Structure from Motion (SfM) and Deep Image Matching (DIM) methods for point cloud initialization. Extensive experimental evaluations on the Mip-NeRF 360 dataset demonstrate that our approach surpasses 3DGS in reconstruction quality, delivering encouraging performance across diverse scenes.
MeshConv3D: Efficient convolution and pooling operators for triangular 3D meshes
Jan 07, 2025Convolutional neural networks (CNNs) have been pivotal in various 2D image analysis tasks, including computer vision, image indexing and retrieval or semantic classification. Extending CNNs to 3D data such as point clouds and 3D meshes raises significant challenges since the very basic convolution and pooling operators need to be completely re-visited and re-defined in an appropriate manner to tackle irregular connectivity issues. In this paper, we introduce MeshConv3D, a 3D mesh-dedicated methodology integrating specialized convolution and face collapse-based pooling operators. MeshConv3D operates directly on meshes of arbitrary topology, without any need of prior re-meshing/conversion techniques. In order to validate our approach, we have considered a semantic classification task. The experimental results obtained on three distinct benchmark datasets show that the proposed approach makes it possible to achieve equivalent or superior classification results, while minimizing the related memory footprint and computational load.
Multi-Modal interpretable automatic video captioning
Nov 11, 2024Video captioning aims to describe video contents using natural language format that involves understanding and interpreting scenes, actions and events that occurs simultaneously on the view. Current approaches have mainly concentrated on visual cues, often neglecting the rich information available from other important modality of audio information, including their inter-dependencies. In this work, we introduce a novel video captioning method trained with multi-modal contrastive loss that emphasizes both multi-modal integration and interpretability. Our approach is designed to capture the dependency between these modalities, resulting in more accurate, thus pertinent captions. Furthermore, we highlight the importance of interpretability, employing multiple attention mechanisms that provide explanation into the model's decision-making process. Our experimental results demonstrate that our proposed method performs favorably against the state-of the-art models on commonly used benchmark datasets of MSR-VTT and VATEX.
Deep self-supervised learning with visualisation for automatic gesture recognition
Jun 18, 2024



Gesture is an important mean of non-verbal communication, with visual modality allows human to convey information during interaction, facilitating peoples and human-machine interactions. However, it is considered difficult to automatically recognise gestures. In this work, we explore three different means to recognise hand signs using deep learning: supervised learning based methods, self-supervised methods and visualisation based techniques applied to 3D moving skeleton data. Self-supervised learning used to train fully connected, CNN and LSTM method. Then, reconstruction method is applied to unlabelled data in simulated settings using CNN as a backbone where we use the learnt features to perform the prediction in the remaining labelled data. Lastly, Grad-CAM is applied to discover the focus of the models. Our experiments results show that supervised learning method is capable to recognise gesture accurately, with self-supervised learning increasing the accuracy in simulated settings. Finally, Grad-CAM visualisation shows that indeed the models focus on relevant skeleton joints on the associated gesture.
Induced Feature Selection by Structured Pruning
Mar 20, 2023



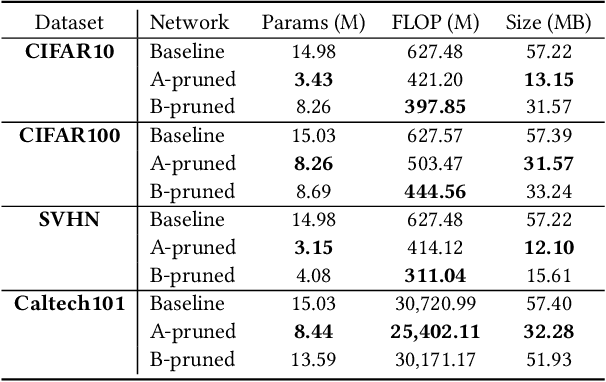
The advent of sparsity inducing techniques in neural networks has been of a great help in the last few years. Indeed, those methods allowed to find lighter and faster networks, able to perform more efficiently in resource-constrained environment such as mobile devices or highly requested servers. Such a sparsity is generally imposed on the weights of neural networks, reducing the footprint of the architecture. In this work, we go one step further by imposing sparsity jointly on the weights and on the input data. This can be achieved following a three-step process: 1) impose a certain structured sparsity on the weights of the network; 2) track back input features corresponding to zeroed blocks of weight; 3) remove useless weights and input features and retrain the network. Performing pruning both on the network and on input data not only allows for extreme reduction in terms of parameters and operations but can also serve as an interpretation process. Indeed, with the help of data pruning, we now have information about which input feature is useful for the network to keep its performance. Experiments conducted on a variety of architectures and datasets: MLP validated on MNIST, CIFAR10/100 and ConvNets (VGG16 and ResNet18), validated on CIFAR10/100 and CALTECH101 respectively, show that it is possible to achieve additional gains in terms of total parameters and in FLOPs by performing pruning on input data, while also increasing accuracy.
Improve Convolutional Neural Network Pruning by Maximizing Filter Variety
Mar 11, 2022
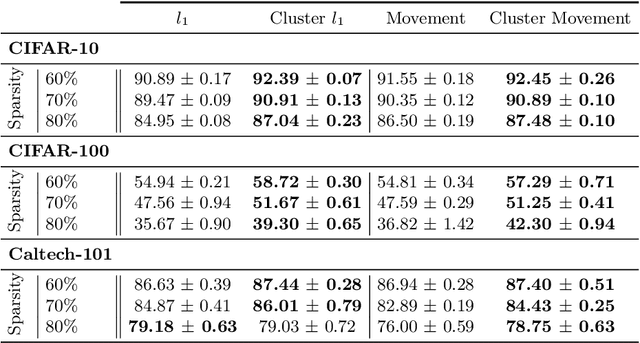

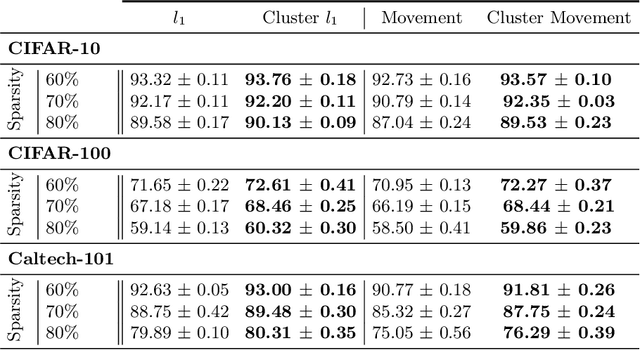
Neural network pruning is a widely used strategy for reducing model storage and computing requirements. It allows to lower the complexity of the network by introducing sparsity in the weights. Because taking advantage of sparse matrices is still challenging, pruning is often performed in a structured way, i.e. removing entire convolution filters in the case of ConvNets, according to a chosen pruning criteria. Common pruning criteria, such as l1-norm or movement, usually do not consider the individual utility of filters, which may lead to: (1) the removal of filters exhibiting rare, thus important and discriminative behaviour, and (2) the retaining of filters with redundant information. In this paper, we present a technique solving those two issues, and which can be appended to any pruning criteria. This technique ensures that the criteria of selection focuses on redundant filters, while retaining the rare ones, thus maximizing the variety of remaining filters. The experimental results, carried out on different datasets (CIFAR-10, CIFAR-100 and CALTECH-101) and using different architectures (VGG-16 and ResNet-18) demonstrate that it is possible to achieve similar sparsity levels while maintaining a higher performance when appending our filter selection technique to pruning criteria. Moreover, we assess the quality of the found sparse sub-networks by applying the Lottery Ticket Hypothesis and find that the addition of our method allows to discover better performing tickets in most cases
An Experimental Study of the Impact of Pre-training on the Pruning of a Convolutional Neural Network
Dec 15, 2021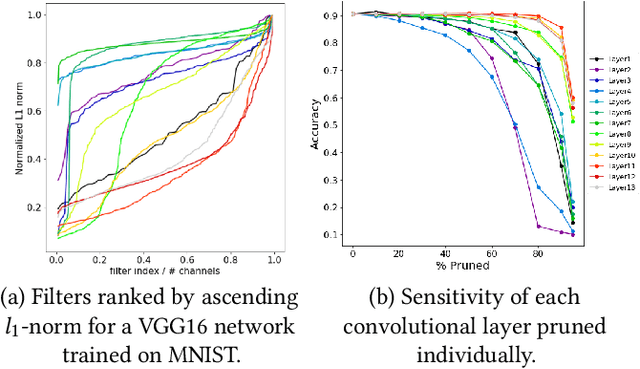
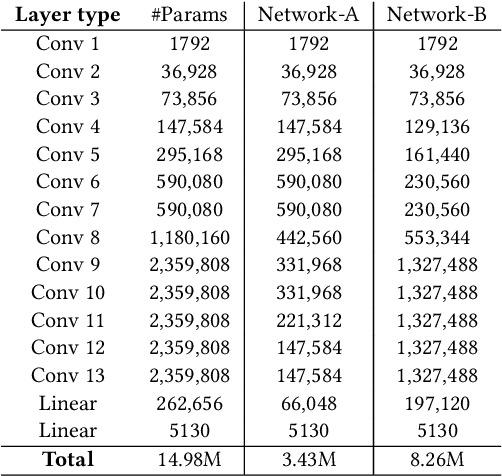
In recent years, deep neural networks have known a wide success in various application domains. However, they require important computational and memory resources, which severely hinders their deployment, notably on mobile devices or for real-time applications. Neural networks usually involve a large number of parameters, which correspond to the weights of the network. Such parameters, obtained with the help of a training process, are determinant for the performance of the network. However, they are also highly redundant. The pruning methods notably attempt to reduce the size of the parameter set, by identifying and removing the irrelevant weights. In this paper, we examine the impact of the training strategy on the pruning efficiency. Two training modalities are considered and compared: (1) fine-tuned and (2) from scratch. The experimental results obtained on four datasets (CIFAR10, CIFAR100, SVHN and Caltech101) and for two different CNNs (VGG16 and MobileNet) demonstrate that a network that has been pre-trained on a large corpus (e.g. ImageNet) and then fine-tuned on a particular dataset can be pruned much more efficiently (up to 80% of parameter reduction) than the same network trained from scratch.
One-Cycle Pruning: Pruning ConvNets Under a Tight Training Budget
Jul 05, 2021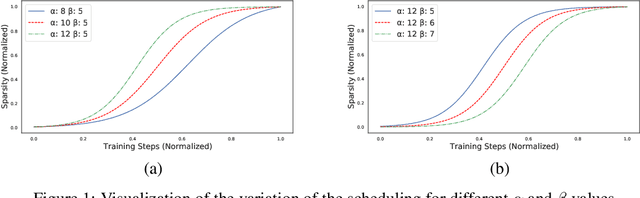
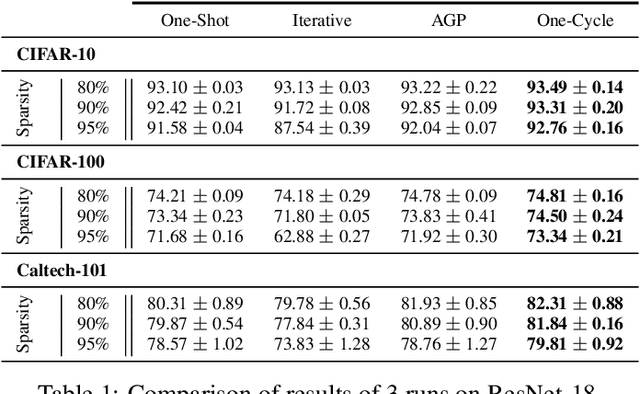
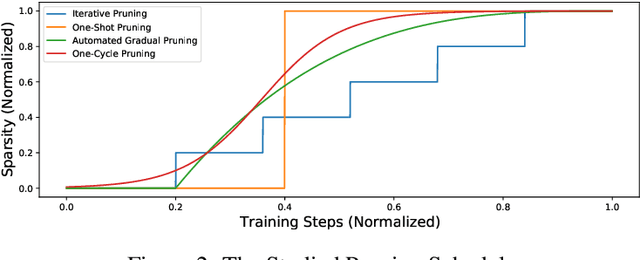

Introducing sparsity in a neural network has been an efficient way to reduce its complexity while keeping its performance almost intact. Most of the time, sparsity is introduced using a three-stage pipeline: 1) train the model to convergence, 2) prune the model according to some criterion, 3) fine-tune the pruned model to recover performance. The last two steps are often performed iteratively, leading to reasonable results but also to a time-consuming and complex process. In our work, we propose to get rid of the first step of the pipeline and to combine the two other steps in a single pruning-training cycle, allowing the model to jointly learn for the optimal weights while being pruned. We do this by introducing a novel pruning schedule, named One-Cycle Pruning, which starts pruning from the beginning of the training, and until its very end. Adopting such a schedule not only leads to better performing pruned models but also drastically reduces the training budget required to prune a model. Experiments are conducted on a variety of architectures (VGG-16 and ResNet-18) and datasets (CIFAR-10, CIFAR-100 and Caltech-101), and for relatively high sparsity values (80%, 90%, 95% of weights removed). Our results show that One-Cycle Pruning consistently outperforms commonly used pruning schedules such as One-Shot Pruning, Iterative Pruning and Automated Gradual Pruning, on a fixed training budget.