 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal interpretable automatic video captioning
Nov 11, 2024Video captioning aims to describe video contents using natural language format that involves understanding and interpreting scenes, actions and events that occurs simultaneously on the view. Current approaches have mainly concentrated on visual cues, often neglecting the rich information available from other important modality of audio information, including their inter-dependencies. In this work, we introduce a novel video captioning method trained with multi-modal contrastive loss that emphasizes both multi-modal integration and interpretability. Our approach is designed to capture the dependency between these modalities, resulting in more accurate, thus pertinent captions. Furthermore, we highlight the importance of interpretability, employing multiple attention mechanisms that provide explanation into the model's decision-making process. Our experimental results demonstrate that our proposed method performs favorably against the state-of the-art models on commonly used benchmark datasets of MSR-VTT and VATEX.
Deep self-supervised learning with visualisation for automatic gesture recognition
Jun 18, 2024



Gesture is an important mean of non-verbal communication, with visual modality allows human to convey information during interaction, facilitating peoples and human-machine interactions. However, it is considered difficult to automatically recognise gestures. In this work, we explore three different means to recognise hand signs using deep learning: supervised learning based methods, self-supervised methods and visualisation based techniques applied to 3D moving skeleton data. Self-supervised learning used to train fully connected, CNN and LSTM method. Then, reconstruction method is applied to unlabelled data in simulated settings using CNN as a backbone where we use the learnt features to perform the prediction in the remaining labelled data. Lastly, Grad-CAM is applied to discover the focus of the models. Our experiments results show that supervised learning method is capable to recognise gesture accurately, with self-supervised learning increasing the accuracy in simulated settings. Finally, Grad-CAM visualisation shows that indeed the models focus on relevant skeleton joints on the associated gesture.
Predicting Eye Gaze Location on Websites
Nov 26, 2022



World-wide-web, with the website and webpage as the main interface, facilitates the dissemination of important information. Hence it is crucial to optimize them for better user interaction, which is primarily done by analyzing users' behavior, especially users' eye-gaze locations. However, gathering these data is still considered to be labor and time intensive. In this work, we enable the development of automatic eye-gaze estimations given a website screenshots as the input. This is done by the curation of a unified dataset that consists of website screenshots, eye-gaze heatmap and website's layout information in the form of image and text masks. Our pre-processed dataset allows us to propose an effective deep learning-based model that leverages both image and text spatial location, which is combined through attention mechanism for effective eye-gaze prediction. In our experiment, we show the benefit of careful fine-tuning using our unified dataset to improve the accuracy of eye-gaze predictions. We further observe the capability of our model to focus on the targeted areas (images and text) to achieve high accuracy. Finally, the comparison with other alternatives shows the state-of-the-art result of our model establishing the benchmark for the eye-gaze prediction task.
Machine Learning based Lie Detector applied to a Collected and Annotated Dataset
Apr 26, 2021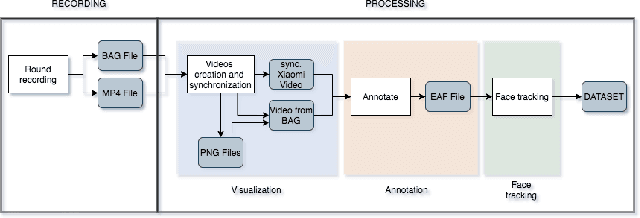



Lie detection is considered a concern for everyone in their day to day life given its impact on human interactions. Hence, people are normally not only pay attention to what their interlocutors are saying but also try to inspect their visual appearances, including faces, to find any signs that indicate whether the person is telling the truth or not. Unfortunately to date, the automatic lie detection, which may help us to understand this lying characteristics are still fairly limited. Mainly due to lack of a lie dataset and corresponding evaluations. In this work, we have collected a dataset that contains annotated images and 3D information of different participants faces during a card game that incentivise the lying. Using our collected dataset, we evaluated several types of machine learning based lie detector through generalize, personal and cross lie lie experiments. In these experiments, we showed the superiority of deep learning based model in recognizing the lie with best accuracy of 57\% for generalized task and 63\% when dealing with a single participant. Finally, we also highlight the limitation of the deep learning based lie detector when dealing with different types of lie tasks.
An Enhanced Adversarial Network with Combined Latent Features for Spatio-Temporal Facial Affect Estimation in the Wild
Feb 18, 2021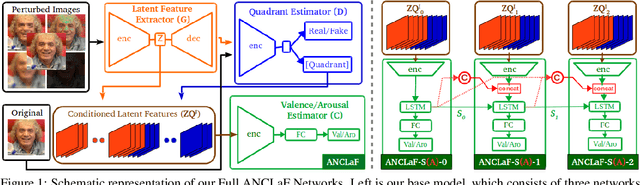
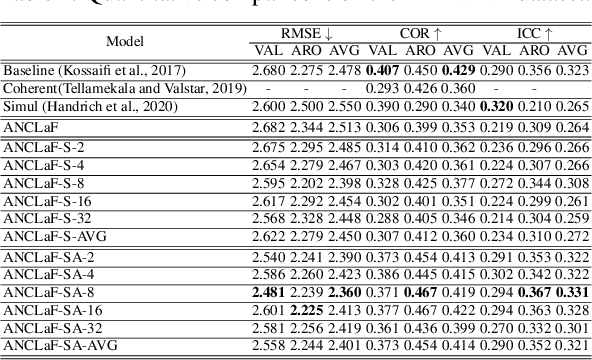
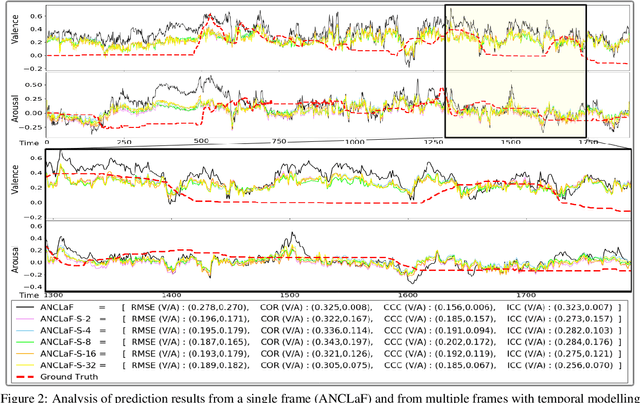
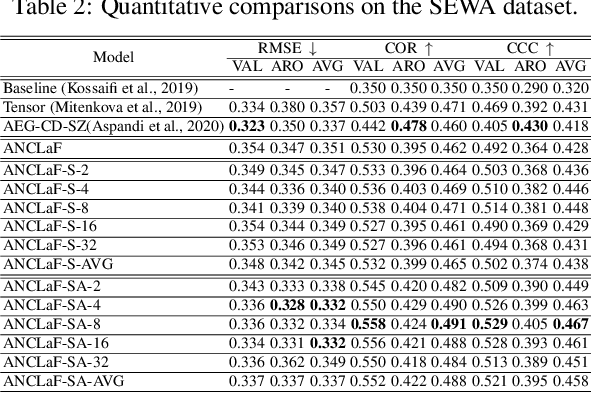
Affective Computing has recently attracted the attention of the research community, due to its numerous applications in diverse areas. In this context, the emergence of video-based data allows to enrich the widely used spatial features with the inclusion of temporal information. However, such spatio-temporal modelling often results in very high-dimensional feature spaces and large volumes of data, making training difficult and time consuming. This paper addresses these shortcomings by proposing a novel model that efficiently extracts both spatial and temporal features of the data by means of its enhanced temporal modelling based on latent features. Our proposed model consists of three major networks, coined Generator, Discriminator, and Combiner, which are trained in an adversarial setting combined with curriculum learning to enable our adaptive attention modules. In our experiments, we show the effectiveness of our approach by reporting our competitive results on both the AFEW-VA and SEWA datasets, suggesting that temporal modelling improves the affect estimates both in qualitative and quantitative terms. Furthermore, we find that the inclusion of attention mechanisms leads to the highest accuracy improvements, as its weights seem to correlate well with the appearance of facial movements, both in terms of temporal localisation and intensity. Finally, we observe the sequence length of around 160\,ms to be the optimum one for temporal modelling, which is consistent with other relevant findings utilising similar lengths.
Adversarial-based neural networks for affect estimations in the wild
Feb 09, 2020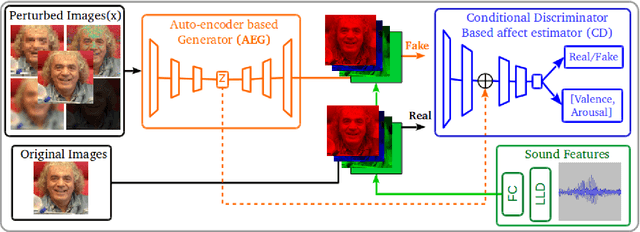

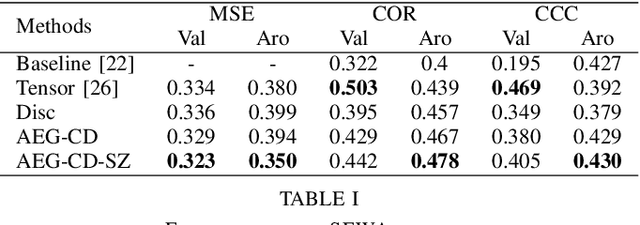
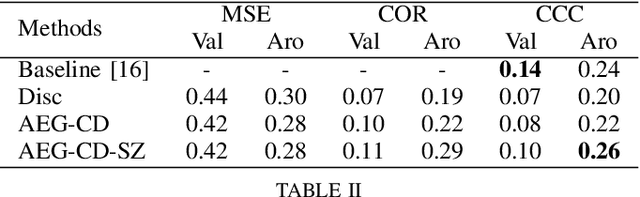
There is a growing interest in affective computing research nowadays given its crucial role in bridging humans with computers. This progress has been recently accelerated due to the emergence of bigger data. One recent advance in this field is the use of adversarial learning to improve model learning through augmented samples. However, the use of latent features, which is feasible through adversarial learning, is not largely explored, yet. This technique may also improve the performance of affective models, as analogously demonstrated in related fields, such as computer vision. To expand this analysis, in this work, we explore the use of latent features through our proposed adversarial-based networks for valence and arousal recognition in the wild. Specifically, our models operate by aggregating several modalities to our discriminator, which is further conditioned to the extracted latent features by the generator. Our experiments on the recently released SEWA dataset suggest the progressive improvements of our results. Finally, we show our competitive results on the Affective Behavior Analysis in-the-Wild (ABAW) challenge dataset
End-to-end facial and physiological model for Affective Computing and applications
Jan 20, 2020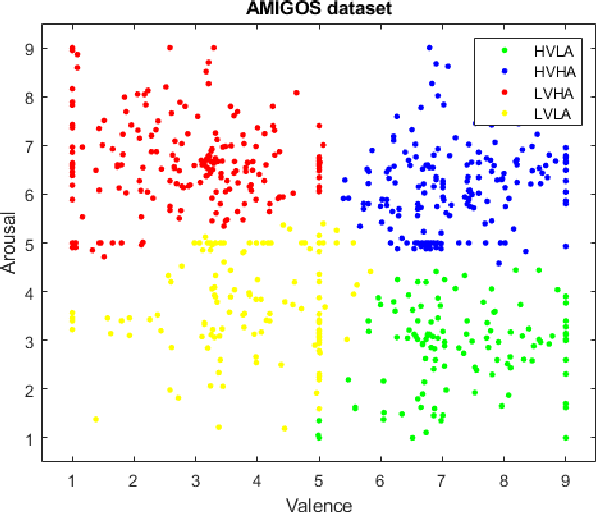
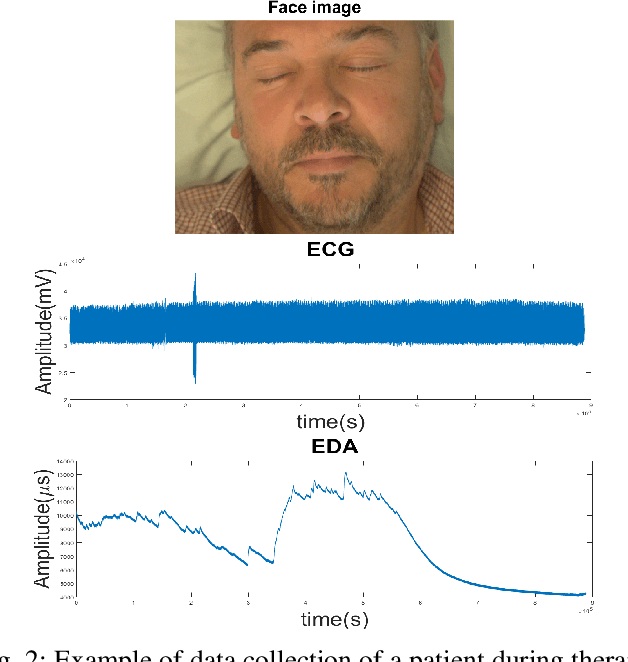
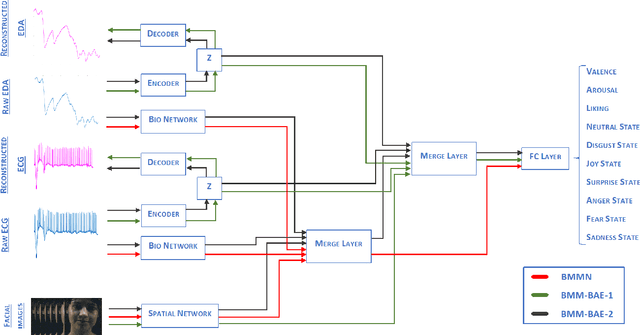
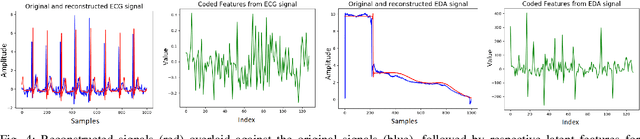
In recent years, Affective Computing and its applications have become a fast-growing research topic. Furthermore, the rise of Deep Learning has introduced significant improvements in the emotion recognition system compared to classical methods. In this work, we propose a multi-modal emotion recognition model based on deep learning techniques using the combination of peripheral physiological signals and facial expressions. Moreover, we present an improvement to proposed models by introducing latent features extracted from our internal Bio Auto-Encoder (BAE). Both models are trained and evaluated on AMIGOS datasets reporting valence, arousal, and emotion state classification. Finally, to demonstrate a possible medical application in affective computing using deep learning techniques, we applied the proposed method to the assessment of anxiety therapy. To this purpose, a reduced multi-modal database has been collected by recording facial expressions and peripheral signals such as Electrocardiogram (ECG) and Galvanic Skin Response (GSR) of each patient. Valence and arousal estimation was extracted using the proposed model from the beginning until the end of the therapy, with successful evaluation to the different emotional changes in the temporal domain.