 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning based Lie Detector applied to a Collected and Annotated Dataset
Apr 26, 2021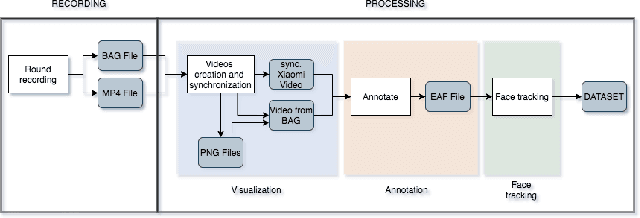



Lie detection is considered a concern for everyone in their day to day life given its impact on human interactions. Hence, people are normally not only pay attention to what their interlocutors are saying but also try to inspect their visual appearances, including faces, to find any signs that indicate whether the person is telling the truth or not. Unfortunately to date, the automatic lie detection, which may help us to understand this lying characteristics are still fairly limited. Mainly due to lack of a lie dataset and corresponding evaluations. In this work, we have collected a dataset that contains annotated images and 3D information of different participants faces during a card game that incentivise the lying. Using our collected dataset, we evaluated several types of machine learning based lie detector through generalize, personal and cross lie lie experiments. In these experiments, we showed the superiority of deep learning based model in recognizing the lie with best accuracy of 57\% for generalized task and 63\% when dealing with a single participant. Finally, we also highlight the limitation of the deep learning based lie detector when dealing with different types of lie tasks.
An Enhanced Adversarial Network with Combined Latent Features for Spatio-Temporal Facial Affect Estimation in the Wild
Feb 18, 2021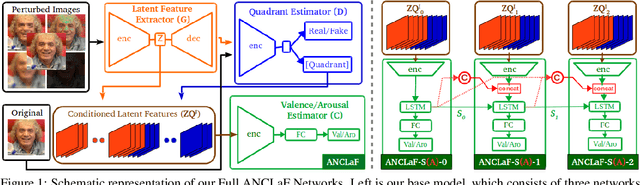
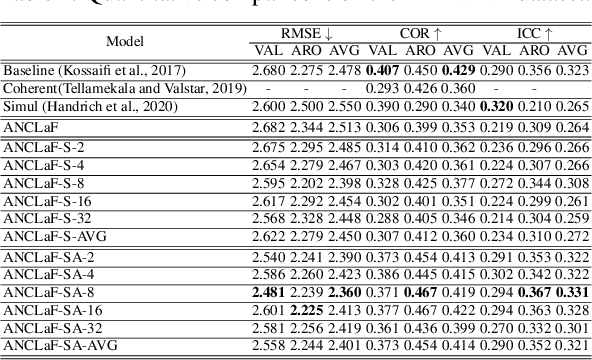
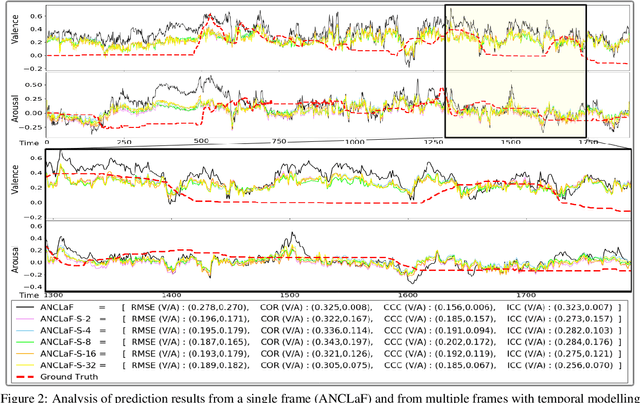
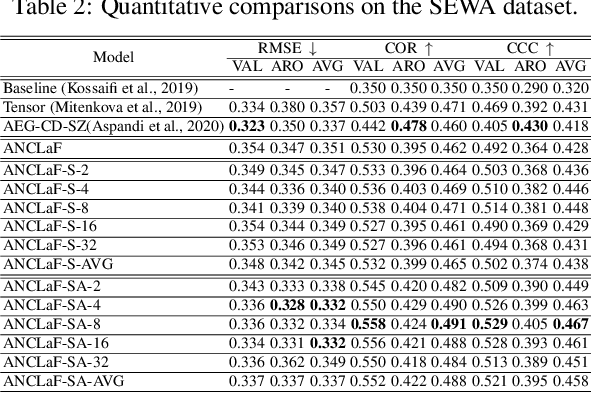
Affective Computing has recently attracted the attention of the research community, due to its numerous applications in diverse areas. In this context, the emergence of video-based data allows to enrich the widely used spatial features with the inclusion of temporal information. However, such spatio-temporal modelling often results in very high-dimensional feature spaces and large volumes of data, making training difficult and time consuming. This paper addresses these shortcomings by proposing a novel model that efficiently extracts both spatial and temporal features of the data by means of its enhanced temporal modelling based on latent features. Our proposed model consists of three major networks, coined Generator, Discriminator, and Combiner, which are trained in an adversarial setting combined with curriculum learning to enable our adaptive attention modules. In our experiments, we show the effectiveness of our approach by reporting our competitive results on both the AFEW-VA and SEWA datasets, suggesting that temporal modelling improves the affect estimates both in qualitative and quantitative terms. Furthermore, we find that the inclusion of attention mechanisms leads to the highest accuracy improvements, as its weights seem to correlate well with the appearance of facial movements, both in terms of temporal localisation and intensity. Finally, we observe the sequence length of around 160\,ms to be the optimum one for temporal modelling, which is consistent with other relevant findings utilising similar lengths.
Adversarial-based neural networks for affect estimations in the wild
Feb 09, 2020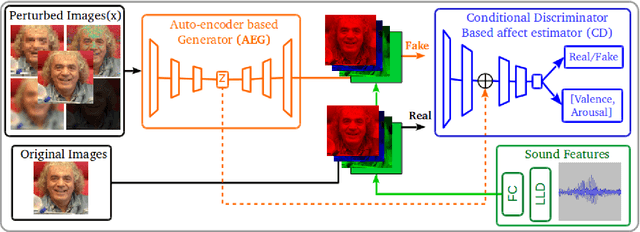

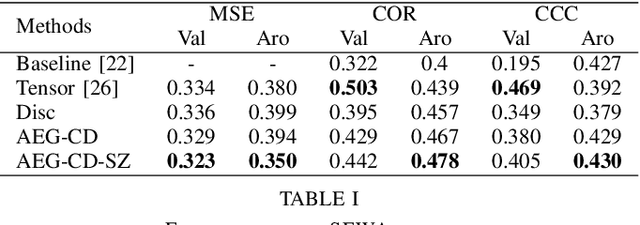
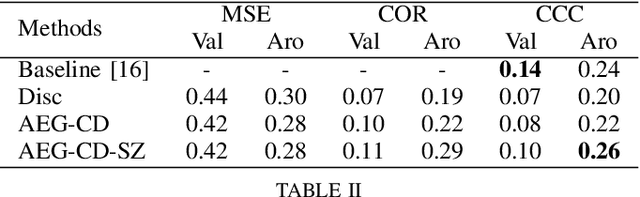
There is a growing interest in affective computing research nowadays given its crucial role in bridging humans with computers. This progress has been recently accelerated due to the emergence of bigger data. One recent advance in this field is the use of adversarial learning to improve model learning through augmented samples. However, the use of latent features, which is feasible through adversarial learning, is not largely explored, yet. This technique may also improve the performance of affective models, as analogously demonstrated in related fields, such as computer vision. To expand this analysis, in this work, we explore the use of latent features through our proposed adversarial-based networks for valence and arousal recognition in the wild. Specifically, our models operate by aggregating several modalities to our discriminator, which is further conditioned to the extracted latent features by the generator. Our experiments on the recently released SEWA dataset suggest the progressive improvements of our results. Finally, we show our competitive results on the Affective Behavior Analysis in-the-Wild (ABAW) challenge dataset
End-to-end facial and physiological model for Affective Computing and applications
Jan 20, 2020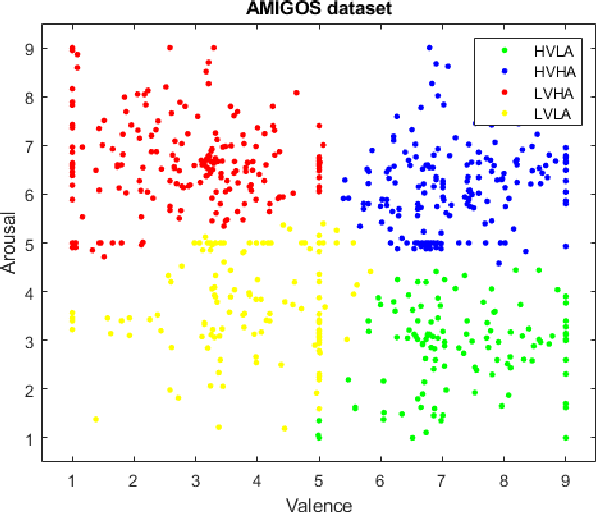
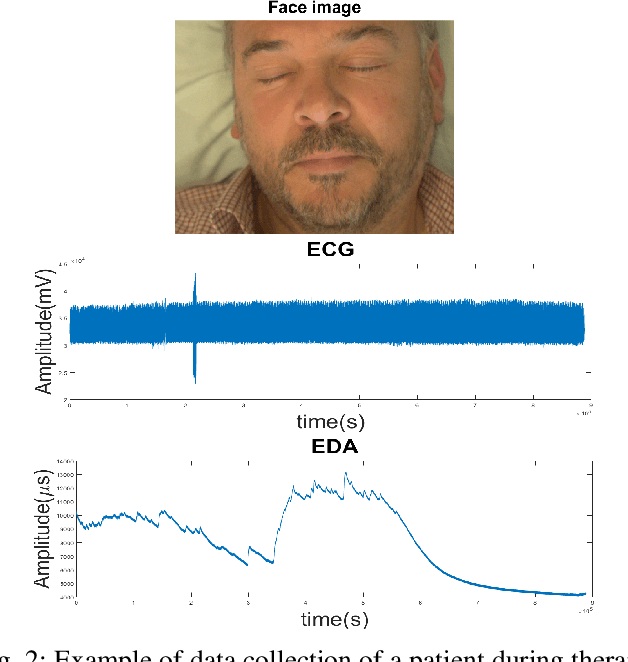
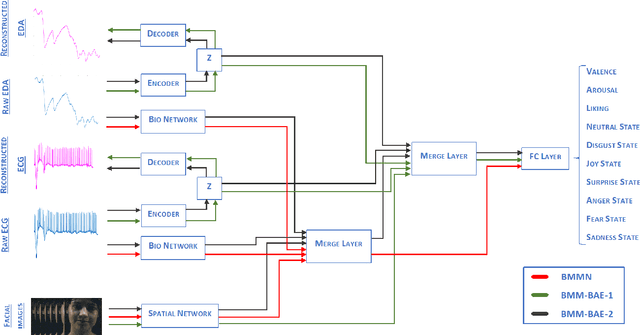
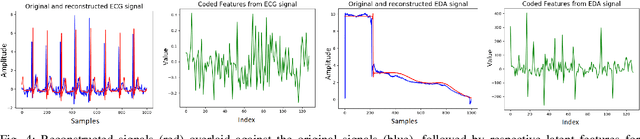
In recent years, Affective Computing and its applications have become a fast-growing research topic. Furthermore, the rise of Deep Learning has introduced significant improvements in the emotion recognition system compared to classical methods. In this work, we propose a multi-modal emotion recognition model based on deep learning techniques using the combination of peripheral physiological signals and facial expressions. Moreover, we present an improvement to proposed models by introducing latent features extracted from our internal Bio Auto-Encoder (BAE). Both models are trained and evaluated on AMIGOS datasets reporting valence, arousal, and emotion state classification. Finally, to demonstrate a possible medical application in affective computing using deep learning techniques, we applied the proposed method to the assessment of anxiety therapy. To this purpose, a reduced multi-modal database has been collected by recording facial expressions and peripheral signals such as Electrocardiogram (ECG) and Galvanic Skin Response (GSR) of each patient. Valence and arousal estimation was extracted using the proposed model from the beginning until the end of the therapy, with successful evaluation to the different emotional changes in the temporal domain.
Learning Disentangled Representations with Reference-Based Variational Autoencoders
Jan 24, 2019
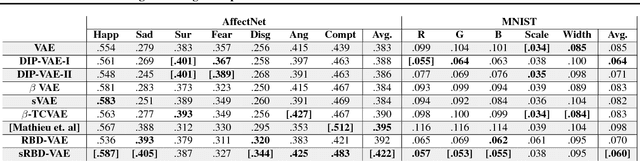
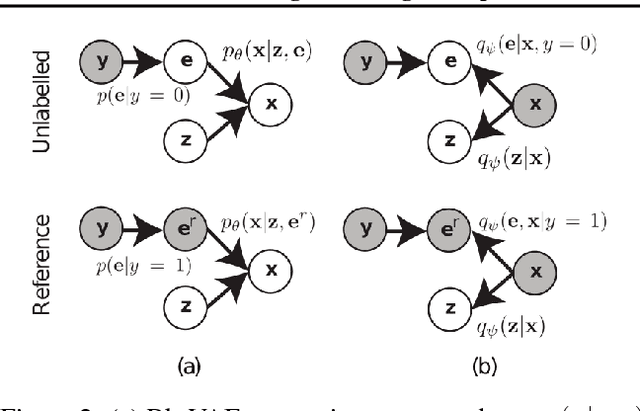
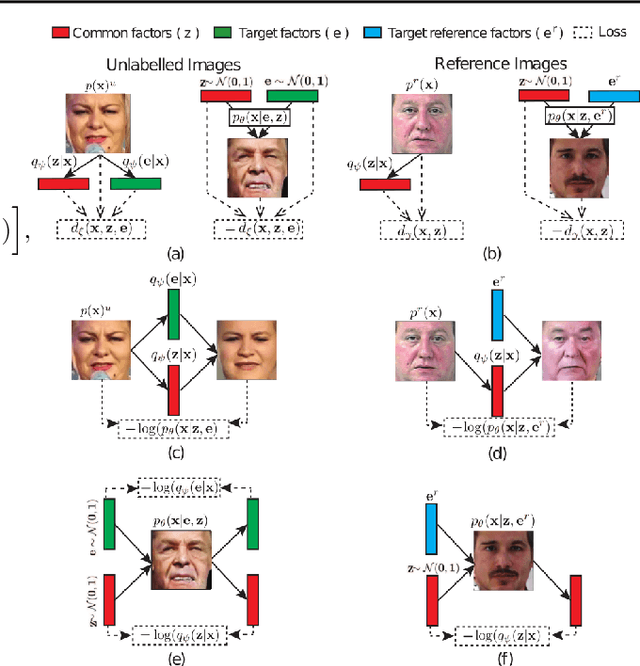
Learning disentangled representations from visual data, where different high-level generative factors are independently encoded, is of importance for many computer vision tasks. Solving this problem, however, typically requires to explicitly label all the factors of interest in training images. To alleviate the annotation cost, we introduce a learning setting which we refer to as "reference-based disentangling". Given a pool of unlabeled images, the goal is to learn a representation where a set of target factors are disentangled from others. The only supervision comes from an auxiliary "reference set" containing images where the factors of interest are constant. In order to address this problem, we propose reference-based variational autoencoders, a novel deep generative model designed to exploit the weak-supervision provided by the reference set. By addressing tasks such as feature learning, conditional image generation or attribute transfer, we validate the ability of the proposed model to learn disentangled representations from this minimal form of supervision.
Multi-Instance Dynamic Ordinal Random Fields for Weakly-supervised Facial Behavior Analysis
Mar 01, 2018
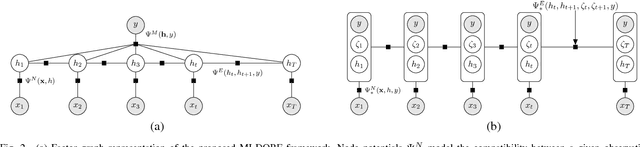
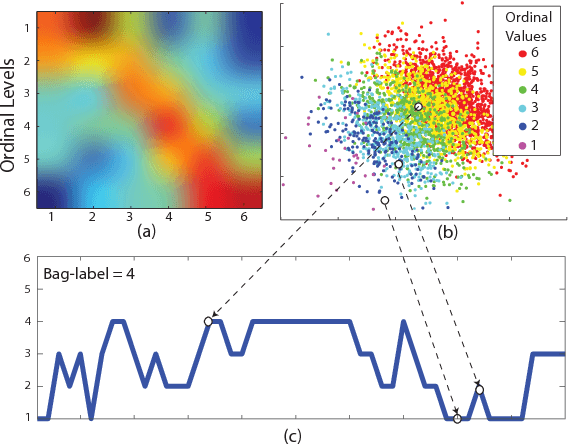
We propose a Multi-Instance-Learning (MIL) approach for weakly-supervised learning problems, where a training set is formed by bags (sets of feature vectors or instances) and only labels at bag-level are provided. Specifically, we consider the Multi-Instance Dynamic-Ordinal-Regression (MI-DOR) setting, where the instance labels are naturally represented as ordinal variables and bags are structured as temporal sequences. To this end, we propose Multi-Instance Dynamic Ordinal Random Fields (MI-DORF). In this framework, we treat instance-labels as temporally-dependent latent variables in an Undirected Graphical Model. Different MIL assumptions are modelled via newly introduced high-order potentials relating bag and instance-labels within the energy function of the model. We also extend our framework to address the Partially-Observed MI-DOR problems, where a subset of instance labels are available during training. We show on the tasks of weakly-supervised facial behavior analysis, Facial Action Unit (DISFA dataset) and Pain (UNBC dataset) Intensity estimation, that the proposed framework outperforms alternative learning approaches. Furthermore, we show that MIDORF can be employed to reduce the data annotation efforts in this context by large-scale.
Multi-instance Dynamic Ordinal Random Fields for Weakly-Supervised Pain Intensity Estimation
Sep 06, 2016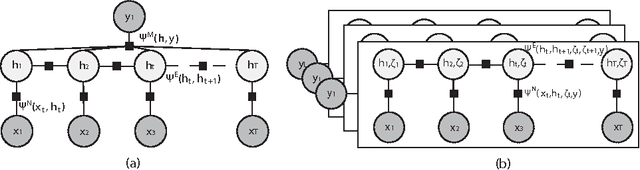
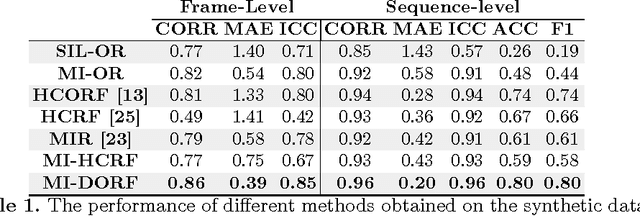
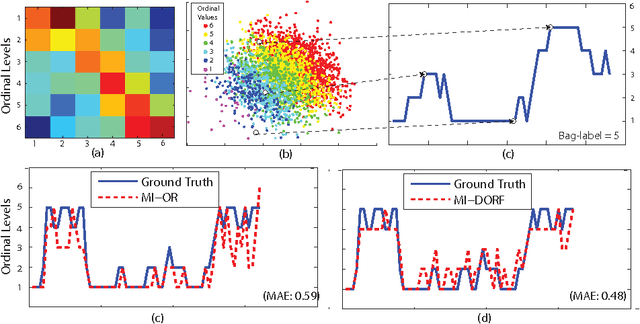
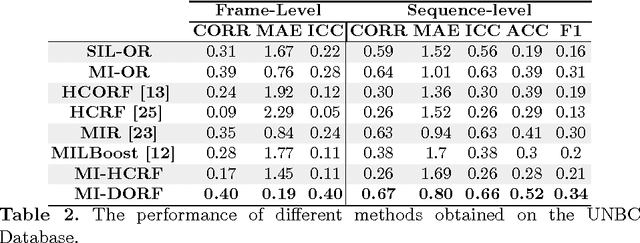
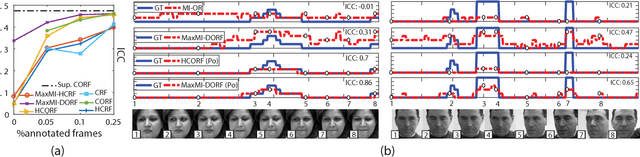
In this paper, we address the Multi-Instance-Learning (MIL) problem when bag labels are naturally represented as ordinal variables (Multi--Instance--Ordinal Regression). Moreover, we consider the case where bags are temporal sequences of ordinal instances. To model this, we propose the novel Multi-Instance Dynamic Ordinal Random Fields (MI-DORF). In this model, we treat instance-labels inside the bag as latent ordinal states. The MIL assumption is modelled by incorporating a high-order cardinality potential relating bag and instance-labels,into the energy function. We show the benefits of the proposed approach on the task of weakly-supervised pain intensity estimation from the UNBC Shoulder-Pain Database. In our experiments, the proposed approach significantly outperforms alternative non-ordinal methods that either ignore the MIL assumption, or do not model dynamic information in target data.