 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST-Phys: Contactless Affective States Through Physiological signals Database
Jul 08, 2025In recent years, affective computing and its applications have become a fast-growing research topic. Despite significant advancements, the lack of affective multi-modal datasets remains a major bottleneck in developing accurate emotion recognition systems. Furthermore, the use of contact-based devices during emotion elicitation often unintentionally influences the emotional experience, reducing or altering the genuine spontaneous emotional response. This limitation highlights the need for methods capable of extracting affective cues from multiple modalities without physical contact, such as remote physiological emotion recognition. To address this, we present the Contactless Affective States Through Physiological Signals Database (CAST-Phys), a novel high-quality dataset explicitly designed for multi-modal remote physiological emotion recognition using facial and physiological cues. The dataset includes diverse physiological signals, such as photoplethysmography (PPG), electrodermal activity (EDA), and respiration rate (RR), alongside high-resolution uncompressed facial video recordings, enabling the potential for remote signal recovery. Our analysis highlights the crucial role of physiological signals in realistic scenarios where facial expressions alone may not provide sufficient emotional information. Furthermore, we demonstrate the potential of remote multi-modal emotion recognition by evaluating the impact of individual and fused modalities, showcasing its effectiveness in advancing contactless emotion recognition technologies.
Automatic facial axes standardization of 3D fetal ultrasound images
Sep 04, 2024Craniofacial anomalies indicate early developmental disturbances and are usually linked to many genetic syndromes. Early diagnosis is critical, yet ultrasound (US) examinations often fail to identify these features. This study presents an AI-driven tool to assist clinicians in standardizing fetal facial axes/planes in 3D US, reducing sonographer workload and facilitating the facial evaluation. Our network, structured into three blocks-feature extractor, rotation and translation regression, and spatial transformer-processes three orthogonal 2D slices to estimate the necessary transformations for standardizing the facial planes in the 3D US. These transformations are applied to the original 3D US using a differentiable module (the spatial transformer block), yielding a standardized 3D US and the corresponding 2D facial standard planes. The dataset used consists of 1180 fetal facial 3D US images acquired between weeks 20 and 35 of gestation. Results show that our network considerably reduces inter-observer rotation variability in the test set, with a mean geodesic angle difference of 14.12$^{\circ}$ $\pm$ 18.27$^{\circ}$ and an Euclidean angle error of 7.45$^{\circ}$ $\pm$ 14.88$^{\circ}$. These findings demonstrate the network's ability to effectively standardize facial axes, crucial for consistent fetal facial assessments. In conclusion, the proposed network demonstrates potential for improving the consistency and accuracy of fetal facial assessments in clinical settings, facilitating early evaluation of craniofacial anomalies.
PhysFlow: Skin tone transfer for remote heart rate estimation through conditional normalizing flows
Jul 31, 2024In recent years, deep learning methods have shown impressive results for camera-based remote physiological signal estimation, clearly surpassing traditional methods. However, the performance and generalization ability of Deep Neural Networks heavily depends on rich training data truly representing different factors of variation encountered in real applications. Unfortunately, many current remote photoplethysmography (rPPG) datasets lack diversity, particularly in darker skin tones, leading to biased performance of existing rPPG approaches. To mitigate this bias, we introduce PhysFlow, a novel method for augmenting skin diversity in remote heart rate estimation using conditional normalizing flows. PhysFlow adopts end-to-end training optimization, enabling simultaneous training of supervised rPPG approaches on both original and generated data. Additionally, we condition our model using CIELAB color space skin features directly extracted from the facial videos without the need for skin-tone labels. We validate PhysFlow on publicly available datasets, UCLA-rPPG and MMPD, demonstrating reduced heart rate error, particularly in dark skin tones. Furthermore, we demonstrate its versatility and adaptability across different data-driven rPPG methods.
Deep Pulse-Signal Magnification for remote Heart Rate Estimation in Compressed Videos
May 04, 2024



Recent advancements in remote heart rate measurement (rPPG), motivated by data-driven approaches, have significantly improved accuracy. However, certain challenges, such as video compression, still remain: recovering the rPPG signal from highly compressed videos is particularly complex. Although several studies have highlighted the difficulties and impact of video compression for this, effective solutions remain limited. In this paper, we present a novel approach to address the impact of video compression on rPPG estimation, which leverages a pulse-signal magnification transformation to adapt compressed videos to an uncompressed data domain in which the rPPG signal is magnified. We validate the effectiveness of our model by exhaustive evaluations on two publicly available datasets, UCLA-rPPG and UBFC-rPPG, employing both intra- and cross-database performance at several compression rates. Additionally, we assess the robustness of our approach on two additional highly compressed and widely-used datasets, MAHNOB-HCI and COHFACE, which reveal outstanding heart rate estimation results.
Deep adaptative spectral zoom for improved remote heart rate estimation
Mar 11, 2024
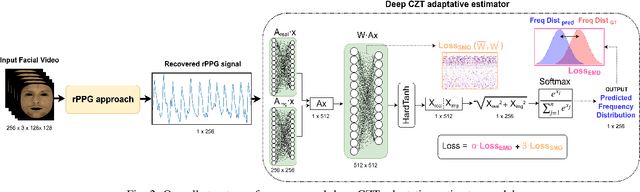

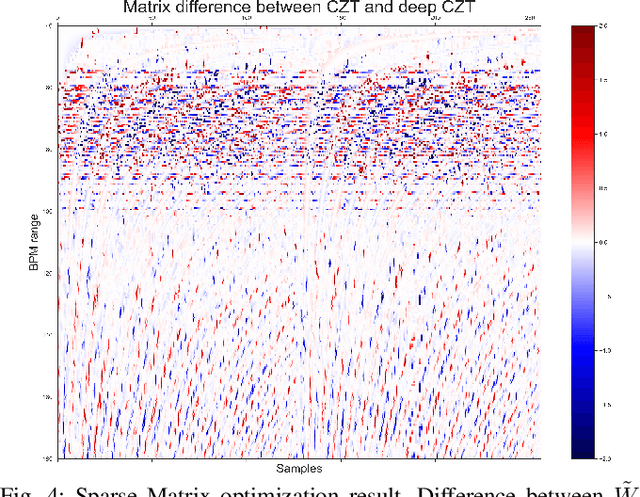
Recent advances in remote heart rate measurement, motivated by data-driven approaches, have notably enhanced accuracy. However, these improvements primarily focus on recovering the rPPG signal, overlooking the implicit challenges of estimating the heart rate (HR) from the derived signal. While many methods employ the Fast Fourier Transform (FFT) for HR estimation, the performance of the FFT is inherently affected by a limited frequency resolution. In contrast, the Chirp-Z Transform (CZT), a generalization form of FFT, can refine the spectrum to the narrow-band range of interest for heart rate, providing improved frequential resolution and, consequently, more accurate estimation. This paper presents the advantages of employing the CZT for remote HR estimation and introduces a novel data-driven adaptive CZT estimator. The objective of our proposed model is to tailor the CZT to match the characteristics of each specific dataset sensor, facilitating a more optimal and accurate estimation of HR from the rPPG signal without compromising generalization across diverse datasets. This is achieved through a Sparse Matrix Optimization (SMO). We validate the effectiveness of our model through exhaustive evaluations on three publicly available datasets UCLA-rPPG, PURE, and UBFC-rPPG employing both intra- and cross-database performance metrics. The results reveal outstanding heart rate estimation capabilities, establishing the proposed approach as a robust and versatile estimator for any rPPG method.
Efficient Remote Photoplethysmography with Temporal Derivative Modules and Time-Shift Invariant Loss
Mar 21, 2022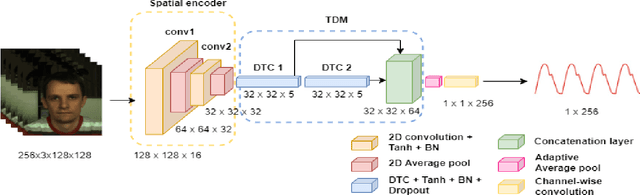
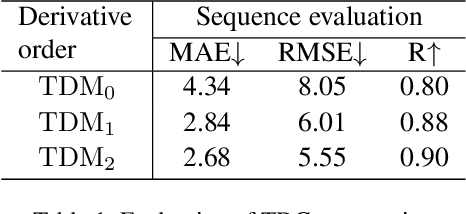
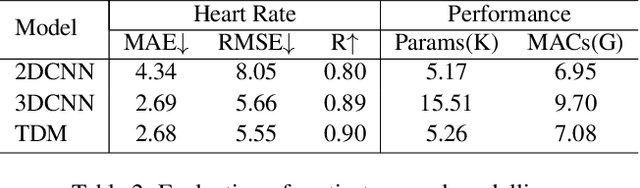
We present a lightweight neural model for remote heart rate estimation focused on the efficient spatio-temporal learning of facial photoplethysmography (PPG) based on i) modelling of PPG dynamics by combinations of multiple convolutional derivatives, and ii) increased flexibility of the model to learn possible offsets between the video facial PPG and the ground truth. PPG dynamics are modelled by a Temporal Derivative Module (TDM) constructed by the incremental aggregation of multiple convolutional derivatives, emulating a Taylor series expansion up to the desired order. Robustness to ground truth offsets is handled by the introduction of TALOS (Temporal Adaptive LOcation Shift), a new temporal loss to train learning-based models. We verify the effectiveness of our model by reporting accuracy and efficiency metrics on the public PURE and UBFC-rPPG datasets. Compared to existing models, our approach shows competitive heart rate estimation accuracy with a much lower number of parameters and lower computational cost.
Machine Learning based Lie Detector applied to a Collected and Annotated Dataset
Apr 26, 2021



Lie detection is considered a concern for everyone in their day to day life given its impact on human interactions. Hence, people are normally not only pay attention to what their interlocutors are saying but also try to inspect their visual appearances, including faces, to find any signs that indicate whether the person is telling the truth or not. Unfortunately to date, the automatic lie detection, which may help us to understand this lying characteristics are still fairly limited. Mainly due to lack of a lie dataset and corresponding evaluations. In this work, we have collected a dataset that contains annotated images and 3D information of different participants faces during a card game that incentivise the lying. Using our collected dataset, we evaluated several types of machine learning based lie detector through generalize, personal and cross lie lie experiments. In these experiments, we showed the superiority of deep learning based model in recognizing the lie with best accuracy of 57\% for generalized task and 63\% when dealing with a single participant. Finally, we also highlight the limitation of the deep learning based lie detector when dealing with different types of lie tasks.
An Enhanced Adversarial Network with Combined Latent Features for Spatio-Temporal Facial Affect Estimation in the Wild
Feb 18, 2021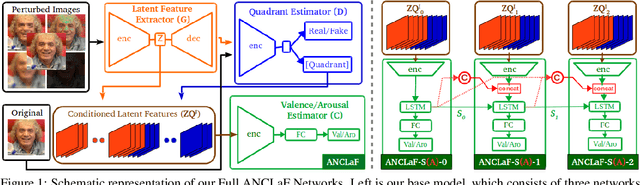
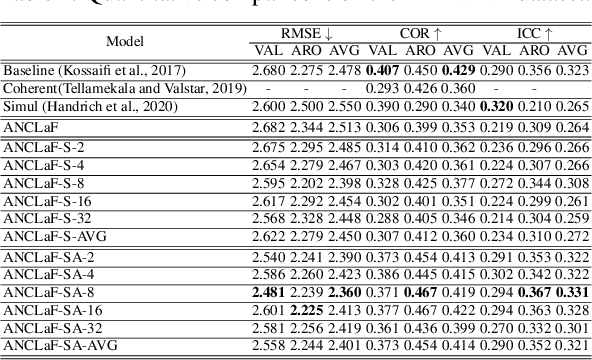
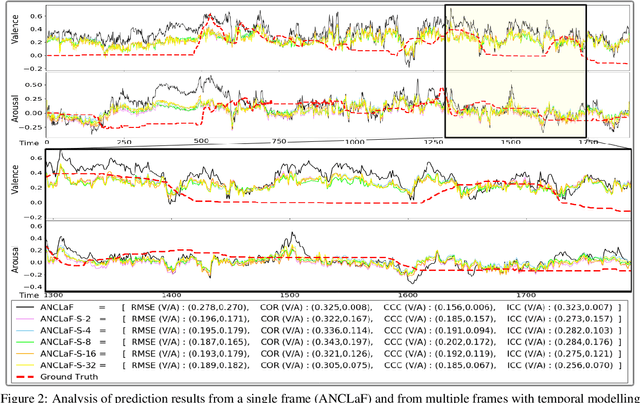
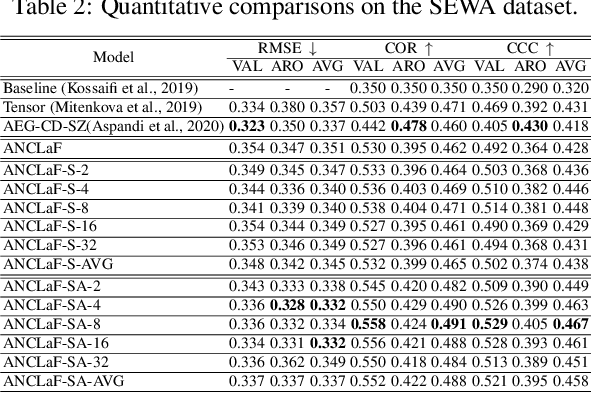
Affective Computing has recently attracted the attention of the research community, due to its numerous applications in diverse areas. In this context, the emergence of video-based data allows to enrich the widely used spatial features with the inclusion of temporal information. However, such spatio-temporal modelling often results in very high-dimensional feature spaces and large volumes of data, making training difficult and time consuming. This paper addresses these shortcomings by proposing a novel model that efficiently extracts both spatial and temporal features of the data by means of its enhanced temporal modelling based on latent features. Our proposed model consists of three major networks, coined Generator, Discriminator, and Combiner, which are trained in an adversarial setting combined with curriculum learning to enable our adaptive attention modules. In our experiments, we show the effectiveness of our approach by reporting our competitive results on both the AFEW-VA and SEWA datasets, suggesting that temporal modelling improves the affect estimates both in qualitative and quantitative terms. Furthermore, we find that the inclusion of attention mechanisms leads to the highest accuracy improvements, as its weights seem to correlate well with the appearance of facial movements, both in terms of temporal localisation and intensity. Finally, we observe the sequence length of around 160\,ms to be the optimum one for temporal modelling, which is consistent with other relevant findings utilising similar lengths.