 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Representations with Reference-Based Variational Autoencoders
Jan 24, 2019
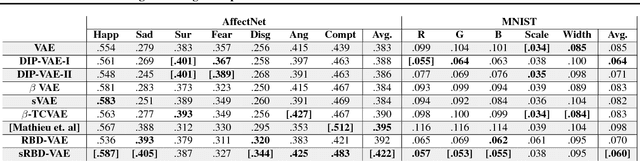
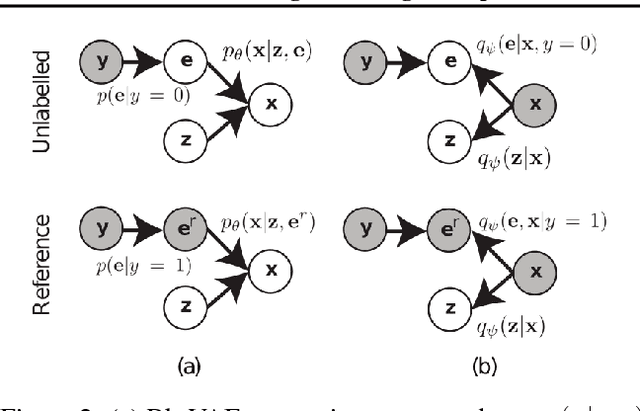
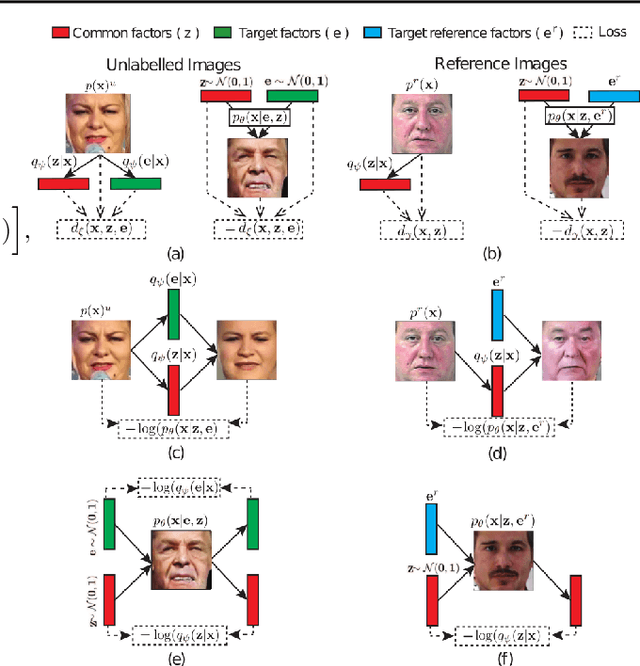
Learning disentangled representations from visual data, where different high-level generative factors are independently encoded, is of importance for many computer vision tasks. Solving this problem, however, typically requires to explicitly label all the factors of interest in training images. To alleviate the annotation cost, we introduce a learning setting which we refer to as "reference-based disentangling". Given a pool of unlabeled images, the goal is to learn a representation where a set of target factors are disentangled from others. The only supervision comes from an auxiliary "reference set" containing images where the factors of interest are constant. In order to address this problem, we propose reference-based variational autoencoders, a novel deep generative model designed to exploit the weak-supervision provided by the reference set. By addressing tasks such as feature learning, conditional image generation or attribute transfer, we validate the ability of the proposed model to learn disentangled representations from this minimal form of supervision.
Towards Estimating the Upper Bound of Visual-Speech Recognition: The Visual Lip-Reading Feasibility Database
Apr 26, 2017
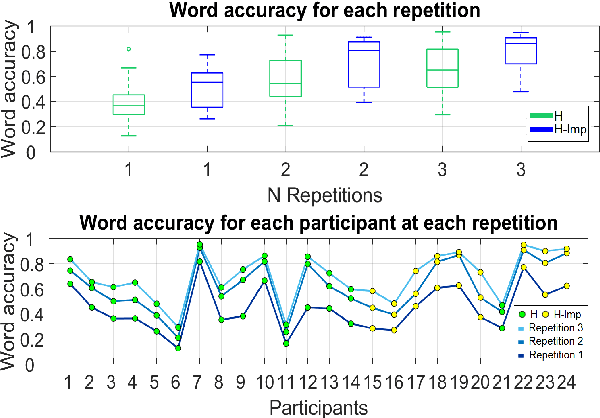
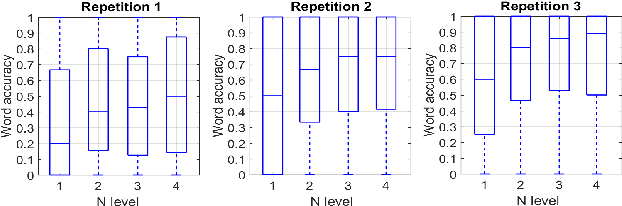
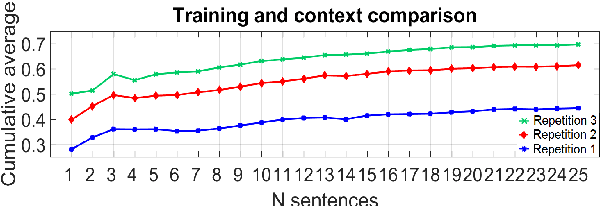
Speech is the most used communication method between humans and it involves the perception of auditory and visual channels. Automatic speech recognition focuses on interpreting the audio signals, although the video can provide information that is complementary to the audio. Exploiting the visual information, however, has proven challenging. On one hand, researchers have reported that the mapping between phonemes and visemes (visual units) is one-to-many because there are phonemes which are visually similar and indistinguishable between them. On the other hand, it is known that some people are very good lip-readers (e.g: deaf people). We study the limit of visual only speech recognition in controlled conditions. With this goal, we designed a new database in which the speakers are aware of being read and aim to facilitate lip-reading. In the literature, there are discrepancies on whether hearing-impaired people are better lip-readers than normal-hearing people. Then, we analyze if there are differences between the lip-reading abilities of 9 hearing-impaired and 15 normal-hearing people. Finally, human abilities are compared with the performance of a visual automatic speech recognition system. In our tests, hearing-impaired participants outperformed the normal-hearing participants but without reaching statistical significance. Human observers were able to decode 44% of the spoken message. In contrast, the visual only automatic system achieved 20% of word recognition rate. However, if we repeat the comparison in terms of phonemes both obtained very similar recognition rates, just above 50%. This suggests that the gap between human lip-reading and automatic speech-reading might be more related to the use of context than to the ability to interpret mouth appearance.