 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyFlow: 3D modeling of realistic and expressive infant faces
Dec 22, 2025Early detection of developmental disorders can be aided by analyzing infant craniofacial morphology, but modeling infant faces is challenging due to limited data and frequent spontaneous expressions. We introduce BabyFlow, a generative AI model that disentangles facial identity and expression, enabling independent control over both. Using normalizing flows, BabyFlow learns flexible, probabilistic representations that capture the complex, non-linear variability of expressive infant faces without restrictive linear assumptions. To address scarce and uncontrolled expressive data, we perform cross-age expression transfer, adapting expressions from adult 3D scans to enrich infant datasets with realistic and systematic expressive variants. As a result, BabyFlow improves 3D reconstruction accuracy, particularly in highly expressive regions such as the mouth, eyes, and nose, and supports synthesis and modification of infant expressions while preserving identity. Additionally, by integrating with diffusion models, BabyFlow generates high-fidelity 2D infant images with consistent 3D geometry, providing powerful tools for data augmentation and early facial analysis.
BabyNet: Reconstructing 3D faces of babies from uncalibrated photographs
Mar 11, 2022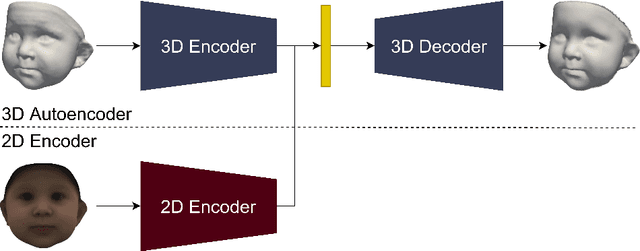
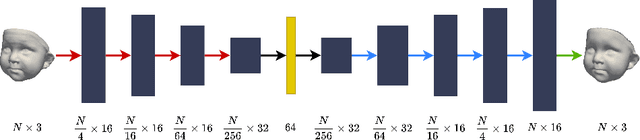
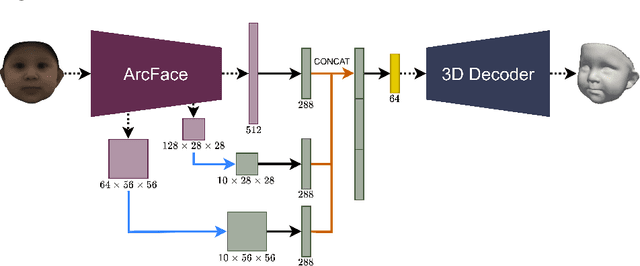
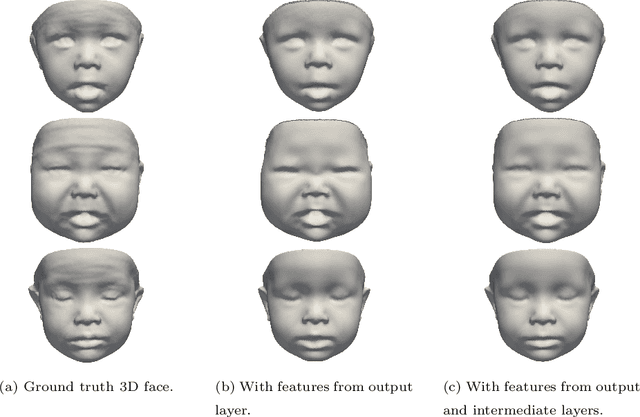
We present a 3D face reconstruction system that aims at recovering the 3D facial geometry of babies from uncalibrated photographs, BabyNet. Since the 3D facial geometry of babies differs substantially from that of adults, baby-specific facial reconstruction systems are needed. BabyNet consists of two stages: 1) a 3D graph convolutional autoencoder learns a latent space of the baby 3D facial shape; and 2) a 2D encoder that maps photographs to the 3D latent space based on representative features extracted using transfer learning. In this way, using the pre-trained 3D decoder, we can recover a 3D face from 2D images. We evaluate BabyNet and show that 1) methods based on adult datasets cannot model the 3D facial geometry of babies, which proves the need for a baby-specific method, and 2) BabyNet outperforms classical model-fitting methods even when a baby-specific 3D morphable model, such as BabyFM, is used.
Survey on 3D face reconstruction from uncalibrated images
Nov 11, 2020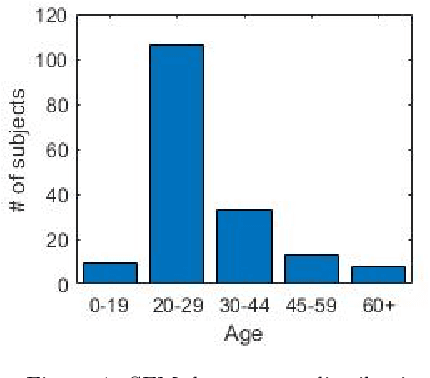
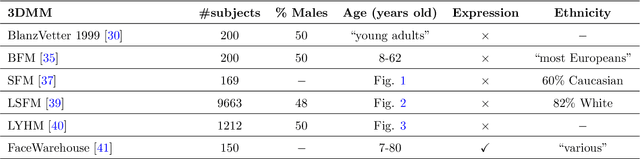

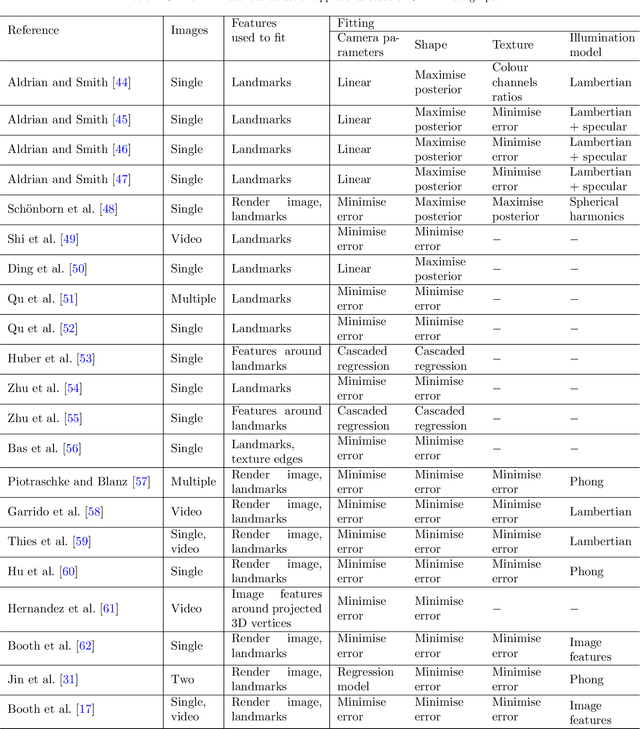
Recently, a lot of attention has been focused on the incorporation of 3D data into face analysis and its applications. Despite providing a more accurate representation of the face, 3D face images are more complex to acquire than 2D pictures. As a consequence, great effort has been invested in developing systems that reconstruct 3D faces from an uncalibrated 2D image. However, the 3D-from-2D face reconstruction problem is ill-posed, thus prior knowledge is needed to restrict the solutions space. In this work, we review 3D face reconstruction methods in the last decade, focusing on those that only use 2D pictures captured under uncontrolled conditions. We present a classification of the proposed methods based on the technique used to add prior knowledge, considering three main strategies, namely, statistical model fitting, photometry, and deep learning, and reviewing each of them separately. In addition, given the relevance of statistical 3D facial models as prior knowledge, we explain the construction procedure and provide a comprehensive list of the publicly available 3D facial models. After the exhaustive study of 3D-from-2D face reconstruction approaches, we observe that the deep learning strategy is rapidly growing since the last few years, matching its extension to that of the widespread statistical model fitting. Unlike the other two strategies, photometry-based methods have decreased in number since the required strong assumptions cause the reconstructions to be of more limited quality than those resulting from model fitting and deep learning methods. The review also identifies current gaps and suggests avenues for future research.
Local Shape Spectrum Analysis for 3D Facial Expression Recognition
May 19, 2017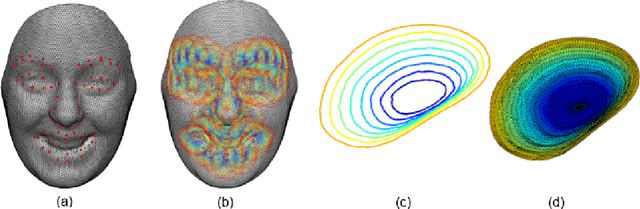
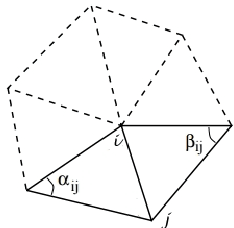
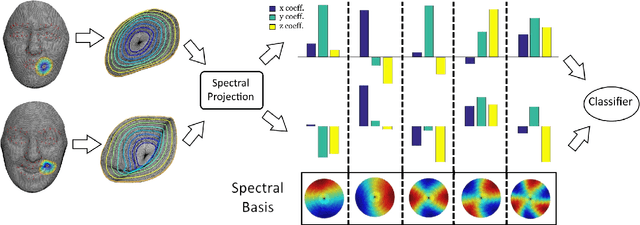

We investigate the problem of facial expression recognition using 3D data. Building from one of the most successful frameworks for facial analysis using exclusively 3D geometry, we extend the analysis from a curve-based representation into a spectral representation, which allows a complete description of the underlying surface that can be further tuned to the desired level of detail. Spectral representations are based on the decomposition of the geometry in its spatial frequency components, much like a Fourier transform, which are related to intrinsic characteristics of the surface. In this work, we propose the use of Graph Laplacian Features (GLF), which results from the projection of local surface patches into a common basis obtained from the Graph Laplacian eigenspace. We test the proposed approach in the BU-3DFE database in terms of expressions and Action Units recognition. Our results confirm that the proposed GLF produces consistently higher recognition rates than the curves-based approach, thanks to a more complete description of the surface, while requiring a lower computational complexity. We also show that the GLF outperform the most popular alternative approach for spectral representation, Shape- DNA, which is based on the Laplace Beltrami Operator and cannot provide a stable basis that guarantee that the extracted signatures for the different patches are directly comparable.
Automatic Viseme Vocabulary Construction to Enhance Continuous Lip-reading
Apr 26, 2017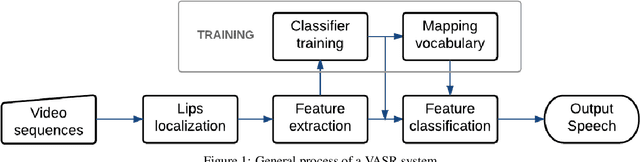



Speech is the most common communication method between humans and involves the perception of both auditory and visual channels. Automatic speech recognition focuses on interpreting the audio signals, but it has been demonstrated that video can provide information that is complementary to the audio. Thus, the study of automatic lip-reading is important and is still an open problem. One of the key challenges is the definition of the visual elementary units (the visemes) and their vocabulary. Many researchers have analyzed the importance of the phoneme to viseme mapping and have proposed viseme vocabularies with lengths between 11 and 15 visemes. These viseme vocabularies have usually been manually defined by their linguistic properties and in some cases using decision trees or clustering techniques. In this work, we focus on the automatic construction of an optimal viseme vocabulary based on the association of phonemes with similar appearance. To this end, we construct an automatic system that uses local appearance descriptors to extract the main characteristics of the mouth region and HMMs to model the statistic relations of both viseme and phoneme sequences. To compare the performance of the system different descriptors (PCA, DCT and SIFT) are analyzed. We test our system in a Spanish corpus of continuous speech. Our results indicate that we are able to recognize approximately 58% of the visemes, 47% of the phonemes and 23% of the words in a continuous speech scenario and that the optimal viseme vocabulary for Spanish is composed by 20 visemes.
Towards Estimating the Upper Bound of Visual-Speech Recognition: The Visual Lip-Reading Feasibility Database
Apr 26, 2017
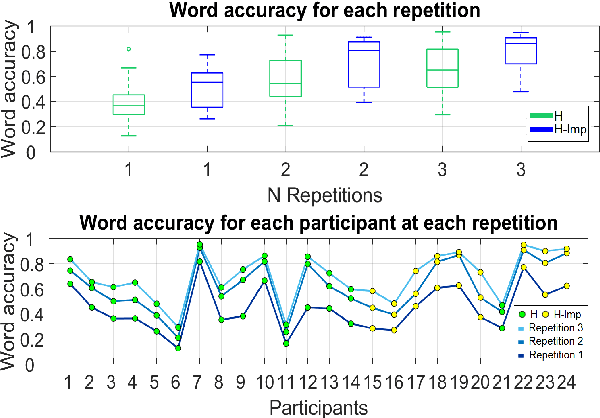
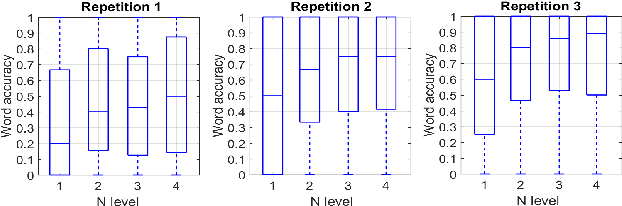
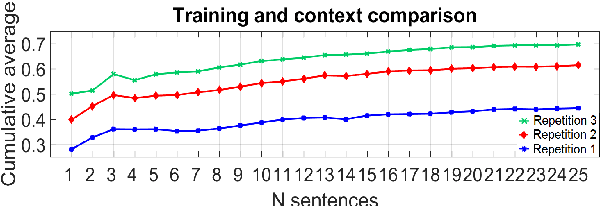
Speech is the most used communication method between humans and it involves the perception of auditory and visual channels. Automatic speech recognition focuses on interpreting the audio signals, although the video can provide information that is complementary to the audio. Exploiting the visual information, however, has proven challenging. On one hand, researchers have reported that the mapping between phonemes and visemes (visual units) is one-to-many because there are phonemes which are visually similar and indistinguishable between them. On the other hand, it is known that some people are very good lip-readers (e.g: deaf people). We study the limit of visual only speech recognition in controlled conditions. With this goal, we designed a new database in which the speakers are aware of being read and aim to facilitate lip-reading. In the literature, there are discrepancies on whether hearing-impaired people are better lip-readers than normal-hearing people. Then, we analyze if there are differences between the lip-reading abilities of 9 hearing-impaired and 15 normal-hearing people. Finally, human abilities are compared with the performance of a visual automatic speech recognition system. In our tests, hearing-impaired participants outperformed the normal-hearing participants but without reaching statistical significance. Human observers were able to decode 44% of the spoken message. In contrast, the visual only automatic system achieved 20% of word recognition rate. However, if we repeat the comparison in terms of phonemes both obtained very similar recognition rates, just above 50%. This suggests that the gap between human lip-reading and automatic speech-reading might be more related to the use of context than to the ability to interpret mouth appearance.