 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Viseme Vocabulary Construction to Enhance Continuous Lip-reading
Paper and Code
Apr 26, 2017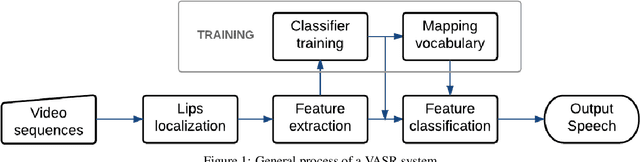



Speech is the most common communication method between humans and involves the perception of both auditory and visual channels. Automatic speech recognition focuses on interpreting the audio signals, but it has been demonstrated that video can provide information that is complementary to the audio. Thus, the study of automatic lip-reading is important and is still an open problem. One of the key challenges is the definition of the visual elementary units (the visemes) and their vocabulary. Many researchers have analyzed the importance of the phoneme to viseme mapping and have proposed viseme vocabularies with lengths between 11 and 15 visemes. These viseme vocabularies have usually been manually defined by their linguistic properties and in some cases using decision trees or clustering techniques. In this work, we focus on the automatic construction of an optimal viseme vocabulary based on the association of phonemes with similar appearance. To this end, we construct an automatic system that uses local appearance descriptors to extract the main characteristics of the mouth region and HMMs to model the statistic relations of both viseme and phoneme sequences. To compare the performance of the system different descriptors (PCA, DCT and SIFT) are analyzed. We test our system in a Spanish corpus of continuous speech. Our results indicate that we are able to recognize approximately 58% of the visemes, 47% of the phonemes and 23% of the words in a continuous speech scenario and that the optimal viseme vocabulary for Spanish is composed by 20 visemes.