 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multi-modal Feature Alignment for Time Series Representation Learning
Dec 09, 2023



In recent times, the field of unsupervised representation learning (URL) for time series data has garnered significant interest due to its remarkable adaptability across diverse downstream applications. Unsupervised learning goals differ from downstream tasks, making it tricky to ensure downstream task utility by focusing only on temporal feature characterization. Researchers have proposed multiple transformations to extract discriminative patterns implied in informative time series, trying to fill the gap. Despite the introduction of a variety of feature engineering techniques, e.g. spectral domain, wavelet transformed features, features in image form and symbolic features etc. the utilization of intricate feature fusion methods and dependence on heterogeneous features during inference hampers the scalability of the solutions. To address this, our study introduces an innovative approach that focuses on aligning and binding time series representations encoded from different modalities, inspired by spectral graph theory, thereby guiding the neural encoder to uncover latent pattern associations among these multi-modal features. In contrast to conventional methods that fuse features from multiple modalities, our proposed approach simplifies the neural architecture by retaining a single time series encoder, consequently leading to preserved scalability. We further demonstrate and prove mechanisms for the encoder to maintain better inductive bias. In our experimental evaluation, we validated the proposed method on a diverse set of time series datasets from various domains. Our approach outperforms existing state-of-the-art URL methods across diverse downstream tasks.
Unsupervised Industrial Anomaly Detection via Pattern Generative and Contrastive Networks
Jul 20, 2022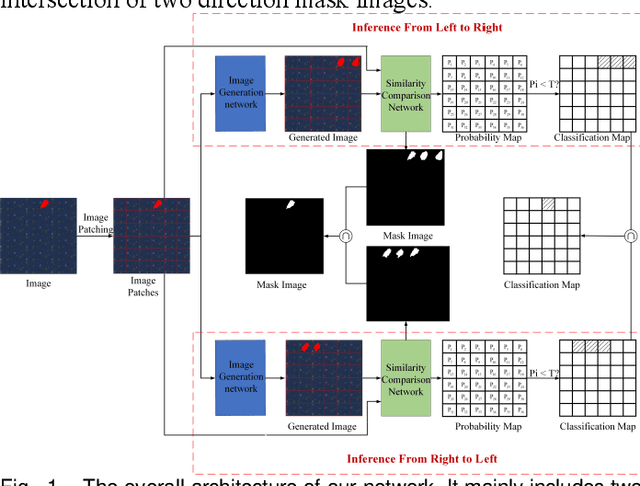
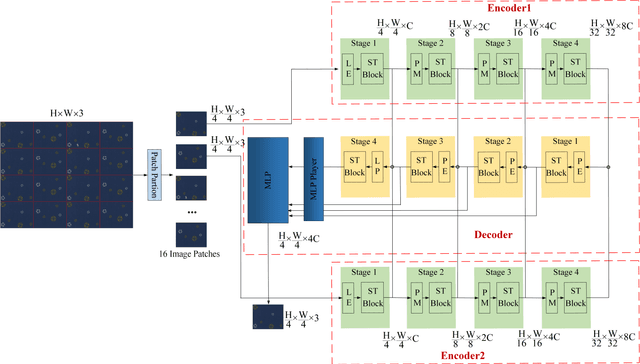

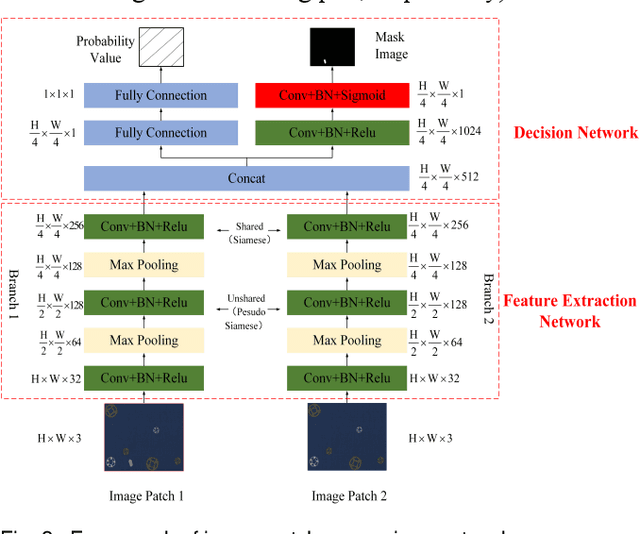
It is hard to collect enough flaw images for training deep learning network in industrial production. Therefore, existing industrial anomaly detection methods prefer to use CNN-based unsupervised detection and localization network to achieve this task. However, these methods always fail when there are varieties happened in new signals since traditional end-to-end networks suffer barriers of fitting nonlinear model in high-dimensional space. Moreover, they have a memory library by clustering the feature of normal images essentially, which cause it is not robust to texture change. To this end, we propose the Vision Transformer based (VIT-based) unsupervised anomaly detection network. It utilizes a hierarchical task learning and human experience to enhance its interpretability. Our network consists of pattern generation and comparison networks. Pattern generation network uses two VIT-based encoder modules to extract the feature of two consecutive image patches, then uses VIT-based decoder module to learn the human designed style of these features and predict the third image patch. After this, we use the Siamese-based network to compute the similarity of the generation image patch and original image patch. Finally, we refine the anomaly localization by the bi-directional inference strategy. Comparison experiments on public dataset MVTec dataset show our method achieves 99.8% AUC, which surpasses previous state-of-the-art methods. In addition, we give a qualitative illustration on our own leather and cloth datasets. The accurate segment results strongly prove the accuracy of our method in anomaly detection.
An unsupervised approach for semantic place annotation of trajectories based on the prior probability
Apr 20, 2022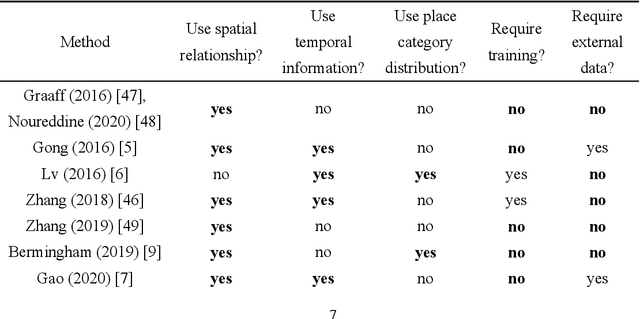
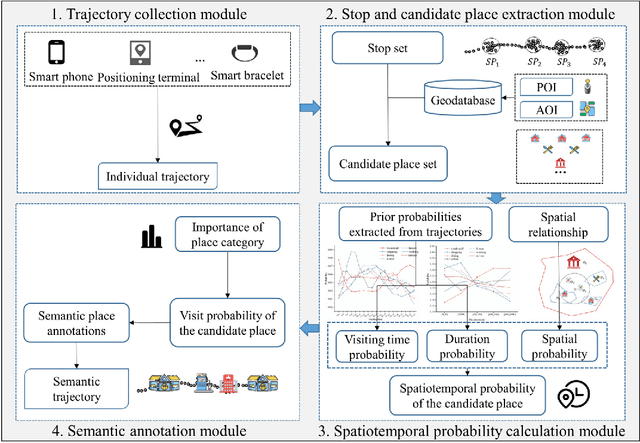
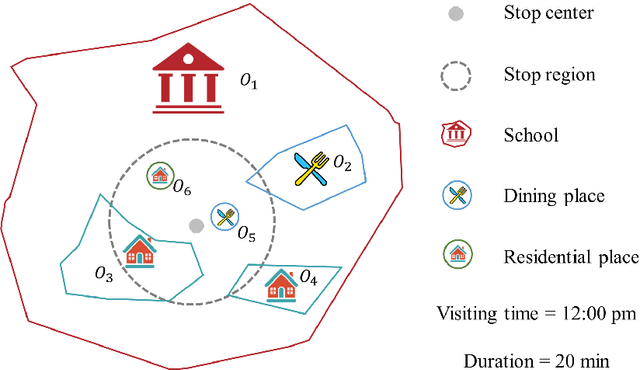
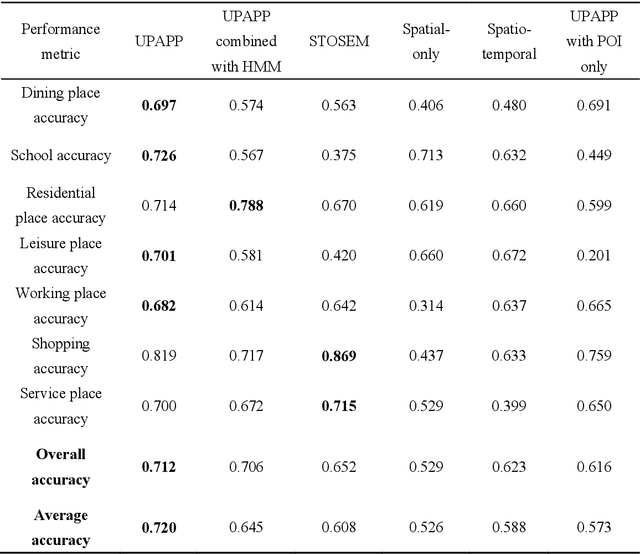
Semantic place annotation can provide individual semantics, which can be of great help in the field of trajectory data mining. Most existing methods rely on annotated or external data and require retraining following a change of region, thus preventing their large-scale applications. Herein, we propose an unsupervised method denoted as UPAPP for the semantic place annotation of trajectories using spatiotemporal information. The Bayesian Criterion is specifically employed to decompose the spatiotemporal probability of the candidate place into spatial probability, duration probability, and visiting time probability. Spatial information in ROI and POI data is subsequently adopted to calculate the spatial probability. In terms of the temporal probabilities, the Term Frequency Inverse Document Frequency weighting algorithm is used to count the potential visits to different place types in the trajectories, and generates the prior probabilities of the visiting time and duration. The spatiotemporal probability of the candidate place is then combined with the importance of the place category to annotate the visited places. Validation with a trajectory dataset collected by 709 volunteers in Beijing showed that our method achieved an overall and average accuracy of 0.712 and 0.720, respectively, indicating that the visited places can be annotated accurately without any external data.
Appearance-Invariant 6-DoF Visual Localization using Generative Adversarial Networks
Dec 24, 2020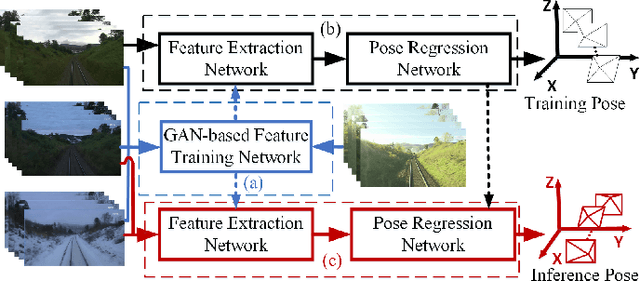
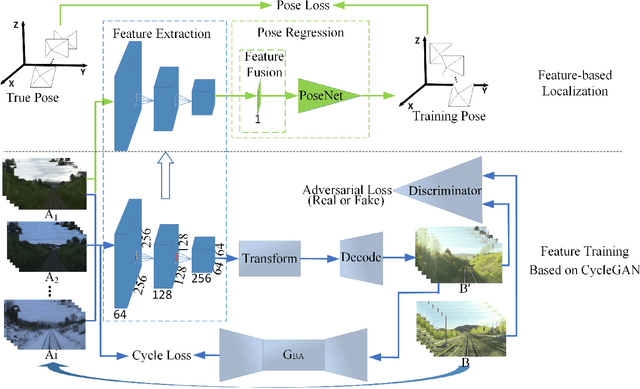
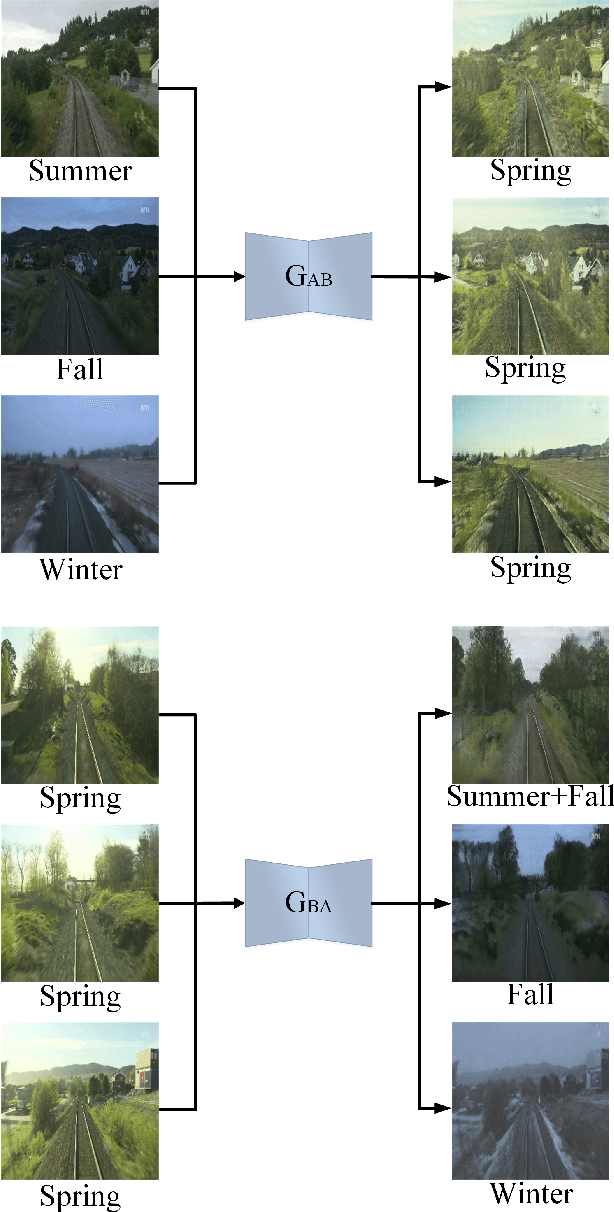
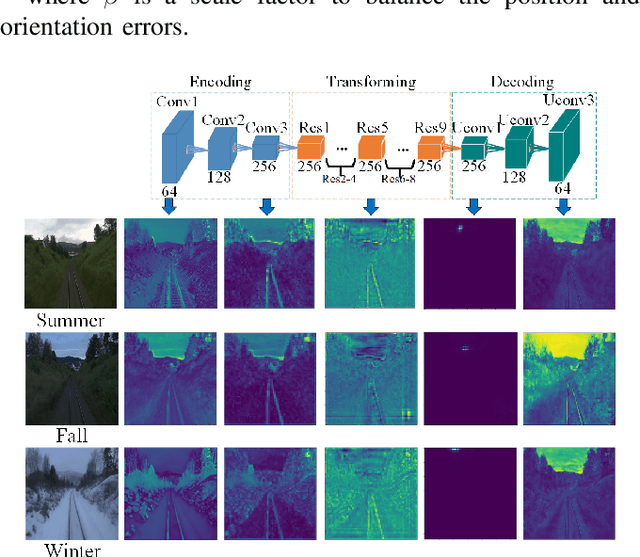
We propose a novel visual localization network when outside environment has changed such as different illumination, weather and season. The visual localization network is composed of a feature extraction network and pose regression network. The feature extraction network is made up of an encoder network based on the Generative Adversarial Network CycleGAN, which can capture intrinsic appearance-invariant feature maps from unpaired samples of different weathers and seasons. With such an invariant feature, we use a 6-DoF pose regression network to tackle long-term visual localization in the presence of outdoor illumination, weather and season changes. A variety of challenging datasets for place recognition and localization are used to prove our visual localization network, and the results show that our method outperforms state-of-the-art methods in the scenarios with various environment changes.
How Old Are You? Face Age Translation with Identity Preservation Using GANs
Sep 11, 2019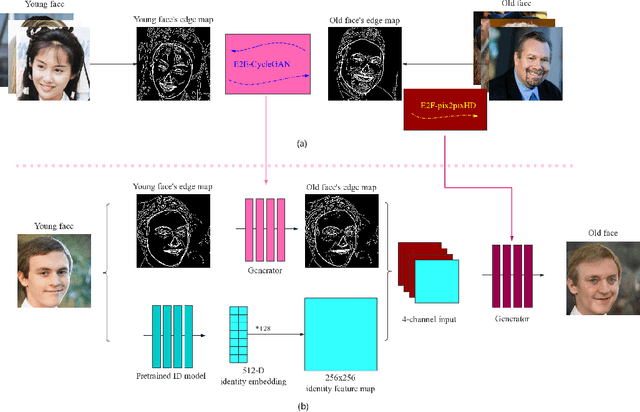

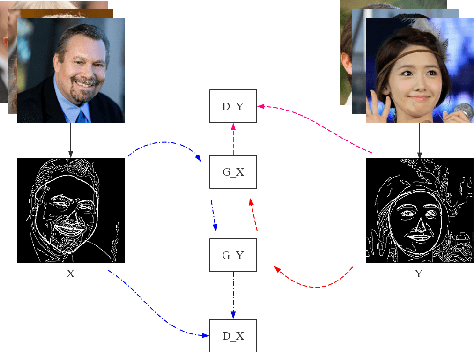
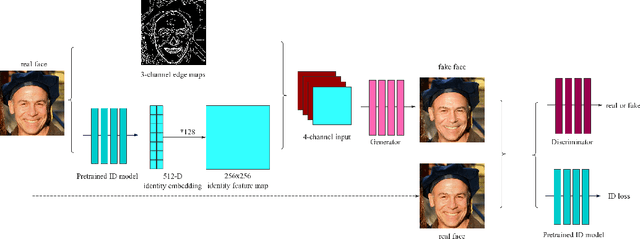
We present a novel framework to generate images of different age while preserving identity information, which is known as face aging. Different from most recent popular face aging networks utilizing Generative Adversarial Networks(GANs) application, our approach do not simply transfer a young face to an old one. Instead, we employ the edge map as intermediate representations, firstly edge maps of young faces are extracted, a CycleGAN-based network is adopted to transfer them into edge maps of old faces, then another pix2pixHD-based network is adopted to transfer the synthesized edge maps, concatenated with identity information, into old faces. In this way, our method can generate more realistic transfered images, simultaneously ensuring that face identity information be preserved well, and the apparent age of the generated image be accurately appropriate. Experimental results demonstrate that our method is feasible for face age translation.
Deep Global-Relative Networks for End-to-End 6-DoF Visual Localization and Odometry
Dec 19, 2018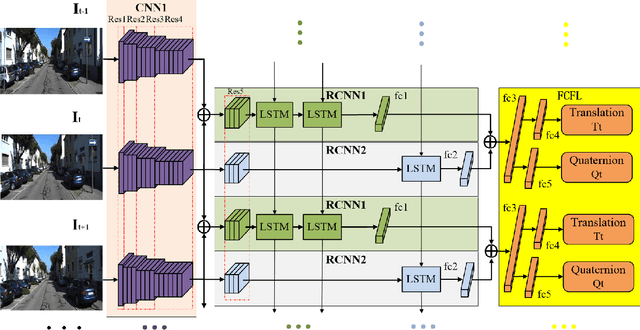

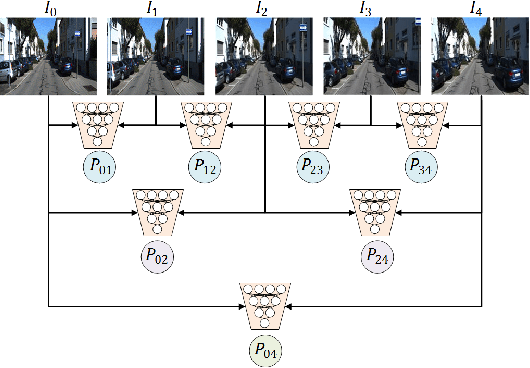

For the autonomous navigation of mobile robots, robust and fast visual localization is a challenging task. Although some end-to-end deep neural networks for 6-DoF Visual Odometry (VO) have been reported with promising results, they are still unable to solve the drift problem in long-range navigation. In this paper, we propose the deep global-relative networks (DGRNets), which is a novel global and relative fusion framework based on Recurrent Convolutional Neural Networks (RCNNs). It is designed to jointly estimate global pose and relative localization from consecutive monocular images. DGRNets include feature extraction sub-networks for discriminative feature selection, RCNNs-type relative pose estimation subnetworks for smoothing the VO trajectory and RCNNs-type global pose regression sub-networks for avoiding the accumulation of pose errors. We also propose two loss functions: the first one consists of Cross Transformation Constraints (CTC) that utilize geometric consistency of the adjacent frames to train a more accurate relative sub-networks, and the second one is composed of CTC and Mean Square Error (MSE) between the predicted pose and ground truth used to train the end-to-end DGRNets. The competitive experiments on indoor Microsoft 7-Scenes and outdoor KITTI dataset show that our DGRNets outperform other learning-based monocular VO methods in terms of pose accuracy.