 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Industrial Anomaly Detection via Pattern Generative and Contrastive Networks
Paper and Code
Jul 20, 2022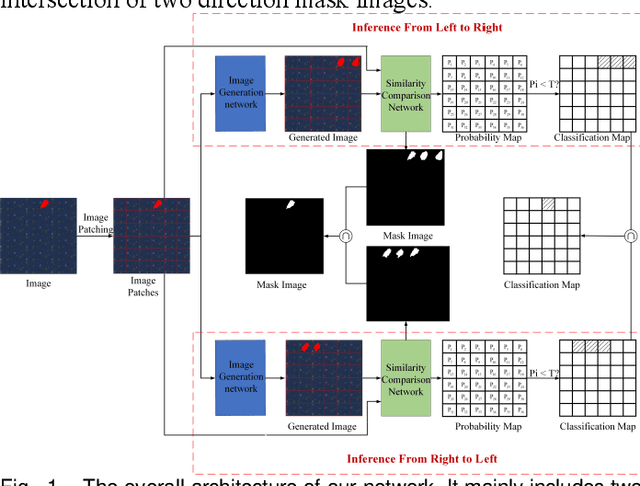
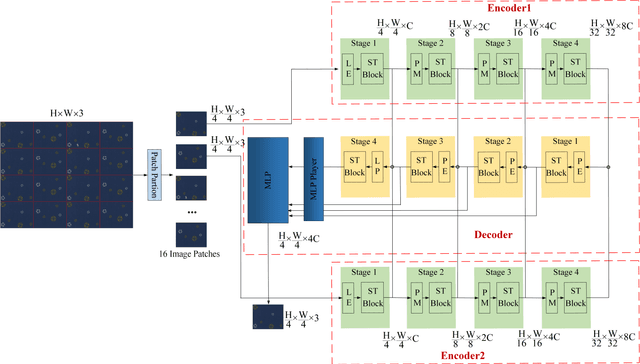

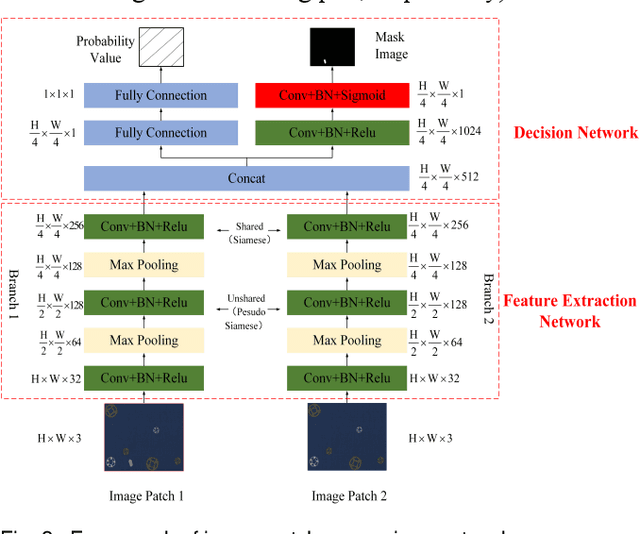
It is hard to collect enough flaw images for training deep learning network in industrial production. Therefore, existing industrial anomaly detection methods prefer to use CNN-based unsupervised detection and localization network to achieve this task. However, these methods always fail when there are varieties happened in new signals since traditional end-to-end networks suffer barriers of fitting nonlinear model in high-dimensional space. Moreover, they have a memory library by clustering the feature of normal images essentially, which cause it is not robust to texture change. To this end, we propose the Vision Transformer based (VIT-based) unsupervised anomaly detection network. It utilizes a hierarchical task learning and human experience to enhance its interpretability. Our network consists of pattern generation and comparison networks. Pattern generation network uses two VIT-based encoder modules to extract the feature of two consecutive image patches, then uses VIT-based decoder module to learn the human designed style of these features and predict the third image patch. After this, we use the Siamese-based network to compute the similarity of the generation image patch and original image patch. Finally, we refine the anomaly localization by the bi-directional inference strategy. Comparison experiments on public dataset MVTec dataset show our method achieves 99.8% AUC, which surpasses previous state-of-the-art methods. In addition, we give a qualitative illustration on our own leather and cloth datasets. The accurate segment results strongly prove the accuracy of our method in anomaly detection.