 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Industrial Anomaly Detection via Pattern Generative and Contrastive Networks
Jul 20, 2022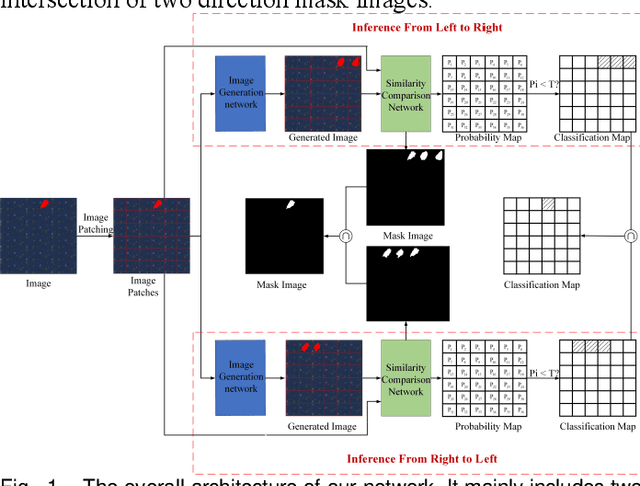
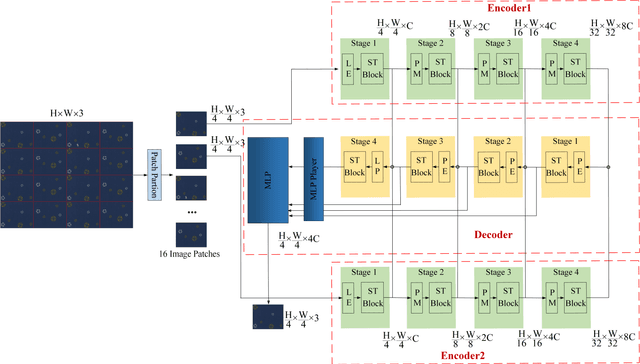

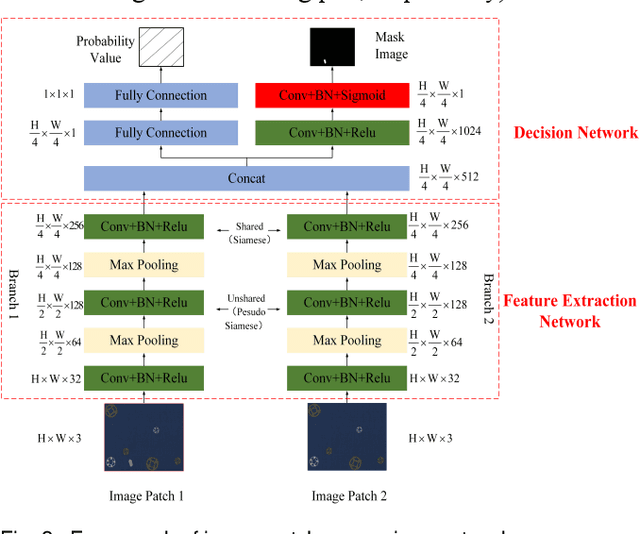
It is hard to collect enough flaw images for training deep learning network in industrial production. Therefore, existing industrial anomaly detection methods prefer to use CNN-based unsupervised detection and localization network to achieve this task. However, these methods always fail when there are varieties happened in new signals since traditional end-to-end networks suffer barriers of fitting nonlinear model in high-dimensional space. Moreover, they have a memory library by clustering the feature of normal images essentially, which cause it is not robust to texture change. To this end, we propose the Vision Transformer based (VIT-based) unsupervised anomaly detection network. It utilizes a hierarchical task learning and human experience to enhance its interpretability. Our network consists of pattern generation and comparison networks. Pattern generation network uses two VIT-based encoder modules to extract the feature of two consecutive image patches, then uses VIT-based decoder module to learn the human designed style of these features and predict the third image patch. After this, we use the Siamese-based network to compute the similarity of the generation image patch and original image patch. Finally, we refine the anomaly localization by the bi-directional inference strategy. Comparison experiments on public dataset MVTec dataset show our method achieves 99.8% AUC, which surpasses previous state-of-the-art methods. In addition, we give a qualitative illustration on our own leather and cloth datasets. The accurate segment results strongly prove the accuracy of our method in anomaly detection.
Appearance-Invariant 6-DoF Visual Localization using Generative Adversarial Networks
Dec 24, 2020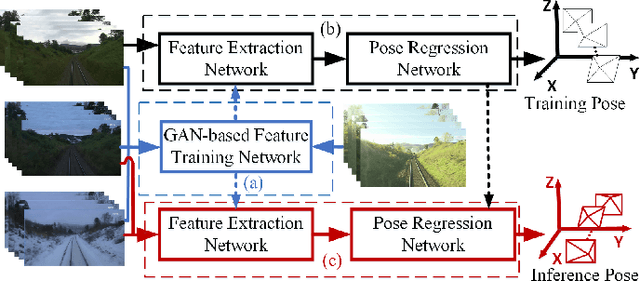
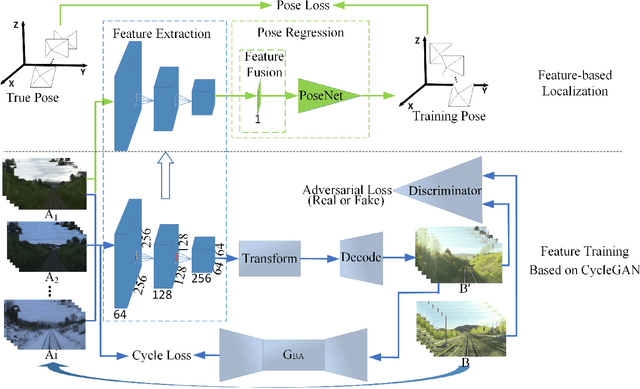
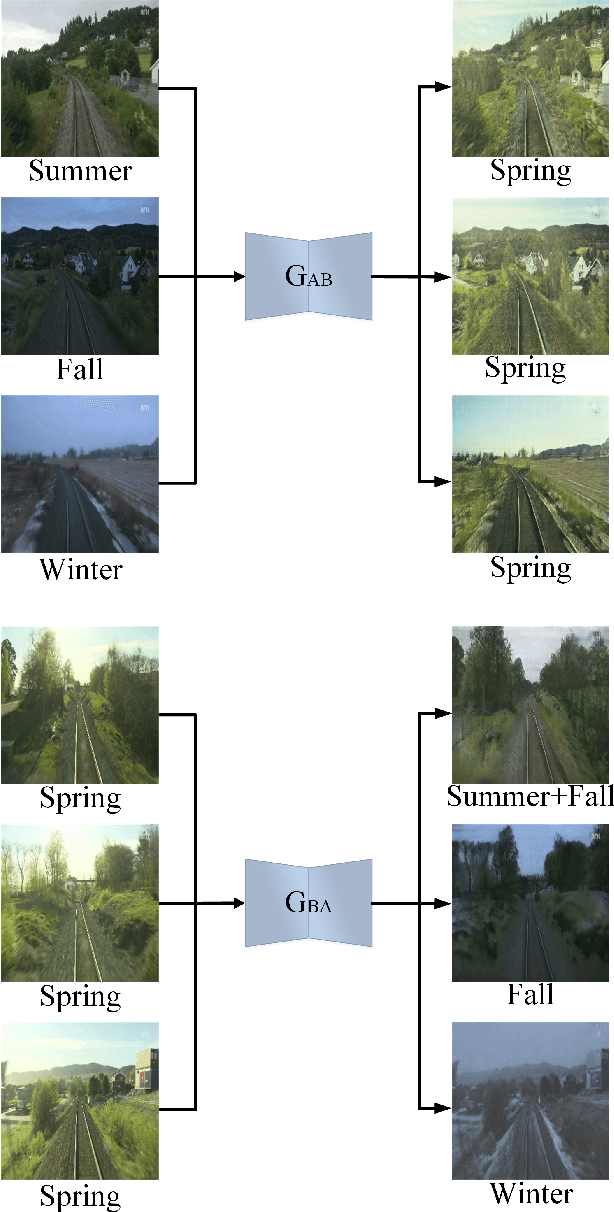
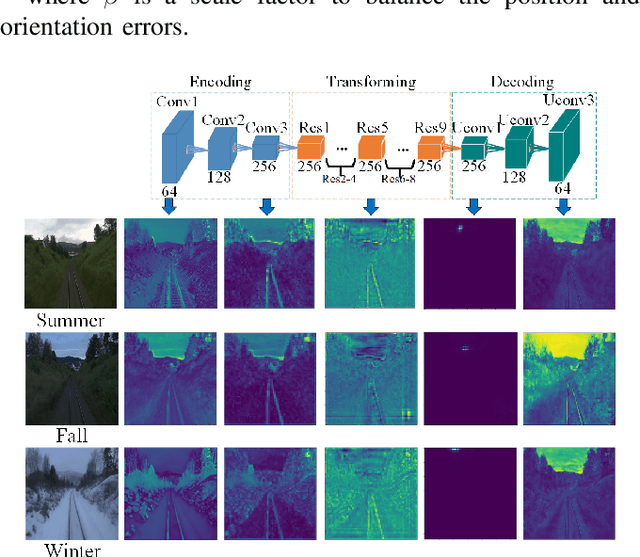
We propose a novel visual localization network when outside environment has changed such as different illumination, weather and season. The visual localization network is composed of a feature extraction network and pose regression network. The feature extraction network is made up of an encoder network based on the Generative Adversarial Network CycleGAN, which can capture intrinsic appearance-invariant feature maps from unpaired samples of different weathers and seasons. With such an invariant feature, we use a 6-DoF pose regression network to tackle long-term visual localization in the presence of outdoor illumination, weather and season changes. A variety of challenging datasets for place recognition and localization are used to prove our visual localization network, and the results show that our method outperforms state-of-the-art methods in the scenarios with various environment changes.
How Old Are You? Face Age Translation with Identity Preservation Using GANs
Sep 11, 2019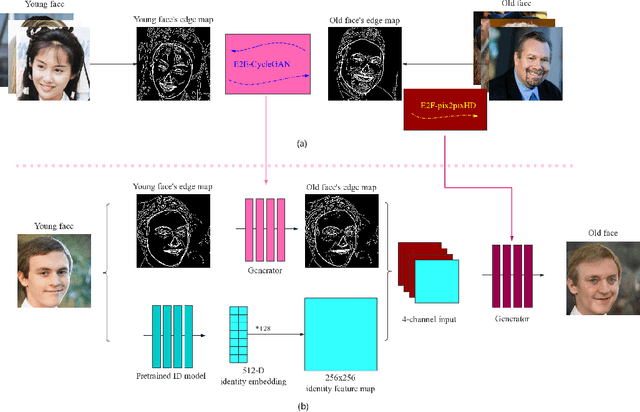

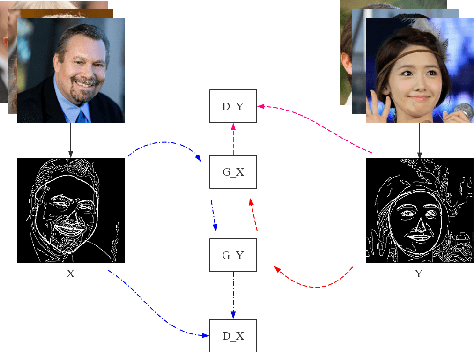
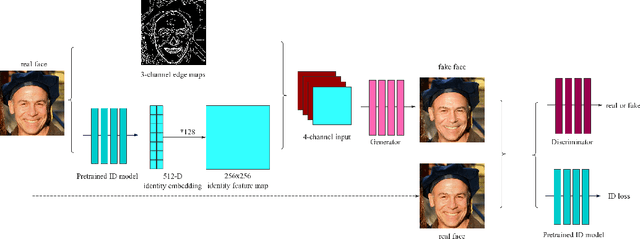
We present a novel framework to generate images of different age while preserving identity information, which is known as face aging. Different from most recent popular face aging networks utilizing Generative Adversarial Networks(GANs) application, our approach do not simply transfer a young face to an old one. Instead, we employ the edge map as intermediate representations, firstly edge maps of young faces are extracted, a CycleGAN-based network is adopted to transfer them into edge maps of old faces, then another pix2pixHD-based network is adopted to transfer the synthesized edge maps, concatenated with identity information, into old faces. In this way, our method can generate more realistic transfered images, simultaneously ensuring that face identity information be preserved well, and the apparent age of the generated image be accurately appropriate. Experimental results demonstrate that our method is feasible for face age translation.
Deep Learning based Wearable Assistive System for Visually Impaired People
Aug 09, 2019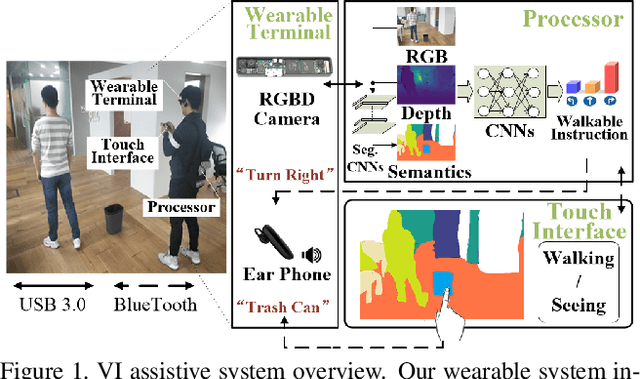
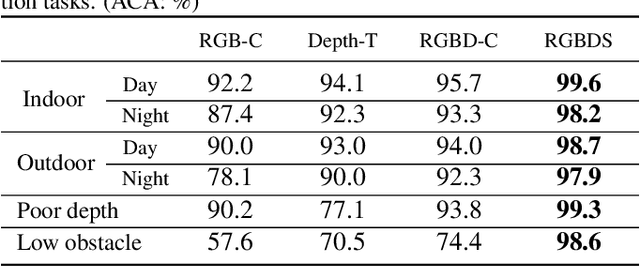
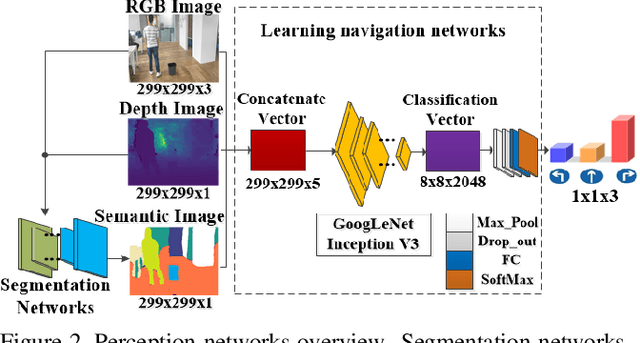
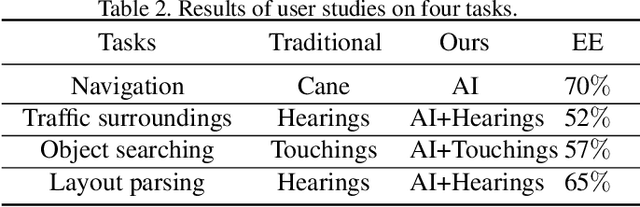
In this paper, we propose a deep learning based assistive system to improve the environment perception experience of visually impaired (VI). The system is composed of a wearable terminal equipped with an RGBD camera and an earphone, a powerful processor mainly for deep learning inferences and a smart phone for touch-based interaction. A data-driven learning approach is proposed to predict safe and reliable walkable instructions using RGBD data and the established semantic map. This map is also used to help VI understand their 3D surrounding objects and layout through well-designed touchscreen interactions. The quantitative and qualitative experimental results show that our learning based obstacle avoidance approach achieves excellent results in both indoor and outdoor datasets with low-lying obstacles. Meanwhile, user studies have also been carried out in various scenarios and showed the improvement of VI's environment perception experience with our system.
DeepVIO: Self-supervised Deep Learning of Monocular Visual Inertial Odometry using 3D Geometric Constraints
Jun 28, 2019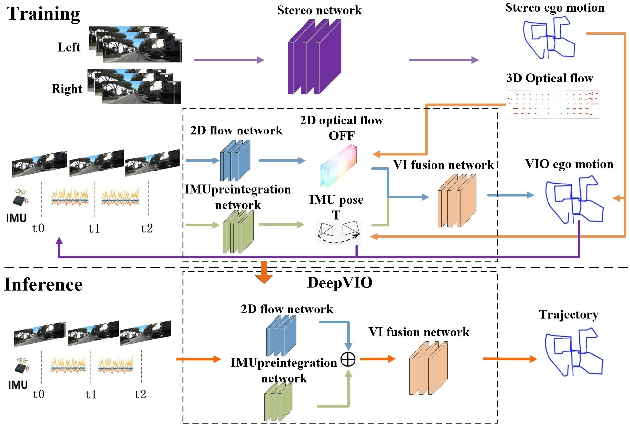
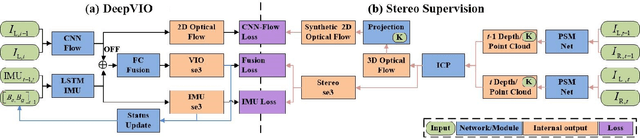


This paper presents an self-supervised deep learning network for monocular visual inertial odometry (named DeepVIO). DeepVIO provides absolute trajectory estimation by directly merging 2D optical flow feature (OFF) and Inertial Measurement Unit (IMU) data. Specifically, it firstly estimates the depth and dense 3D point cloud of each scene by using stereo sequences, and then obtains 3D geometric constraints including 3D optical flow and 6-DoF pose as supervisory signals. Note that such 3D optical flow shows robustness and accuracy to dynamic objects and textureless environments. In DeepVIO training, 2D optical flow network is constrained by the projection of its corresponding 3D optical flow, and LSTM-style IMU preintegration network and the fusion network are learned by minimizing the loss functions from ego-motion constraints. Furthermore, we employ an IMU status update scheme to improve IMU pose estimation through updating the additional gyroscope and accelerometer bias. The experimental results on KITTI and EuRoC datasets show that DeepVIO outperforms state-of-the-art learning based methods in terms of accuracy and data adaptability. Compared to the traditional methods, DeepVIO reduces the impacts of inaccurate Camera-IMU calibrations, unsynchronized and missing data.
Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People
Apr 30, 2019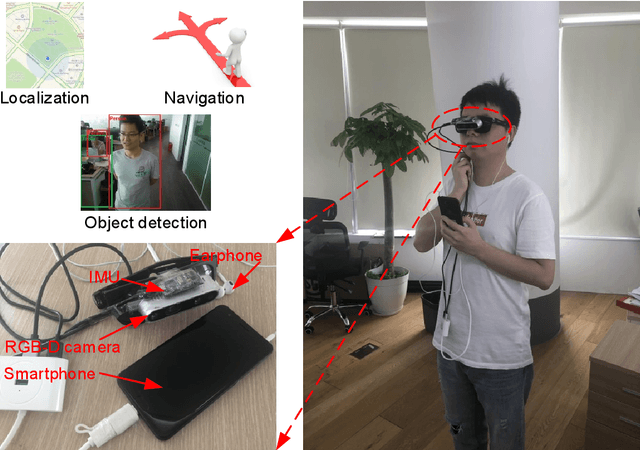
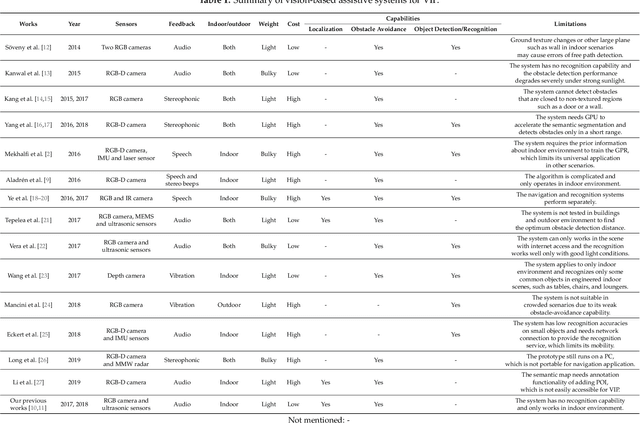
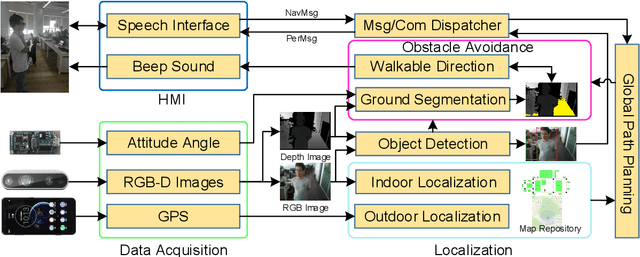
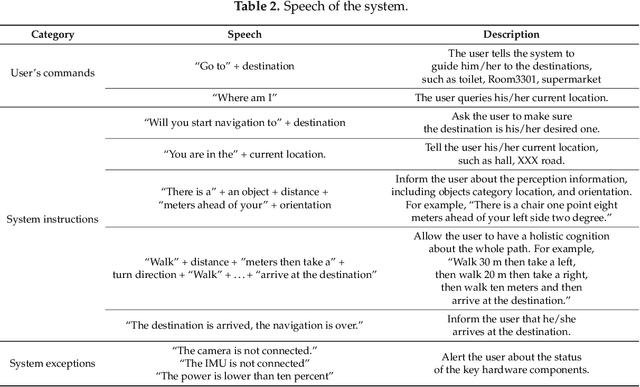
This paper presents a wearable assistive device with the shape of a pair of eyeglasses that allows visually impaired people to navigate safely and quickly in unfamiliar environment, as well as perceive the complicated environment to automatically make decisions on the direction to move. The device uses a consumer Red, Green, Blue and Depth (RGB-D) camera and an Inertial Measurement Unit (IMU) to detect obstacles. As the device leverages the ground height continuity among adjacent image frames, it is able to segment the ground from obstacles accurately and rapidly. Based on the detected ground, the optimal walkable direction is computed and the user is then informed via converted beep sound. Moreover, by utilizing deep learning techniques, the device can semantically categorize the detected obstacles to improve the users' perception of surroundings. It combines a Convolutional Neural Network (CNN) deployed on a smartphone with a depth-image-based object detection to decide what the object type is and where the object is located, and then notifies the user of such information via speech. We evaluated the device's performance with different experiments in which 20 visually impaired people were asked to wear the device and move in an office, and found that they were able to avoid obstacle collisions and find the way in complicated scenarios.
A Unified Framework for Mutual Improvement of SLAM and Semantic Segmentation
Dec 25, 2018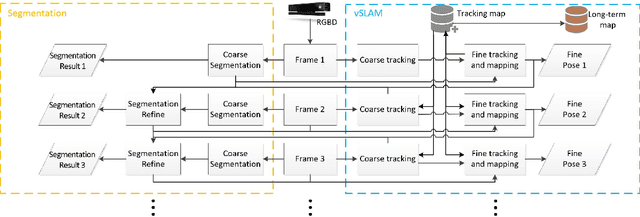
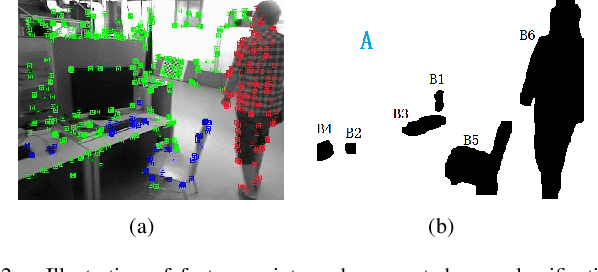
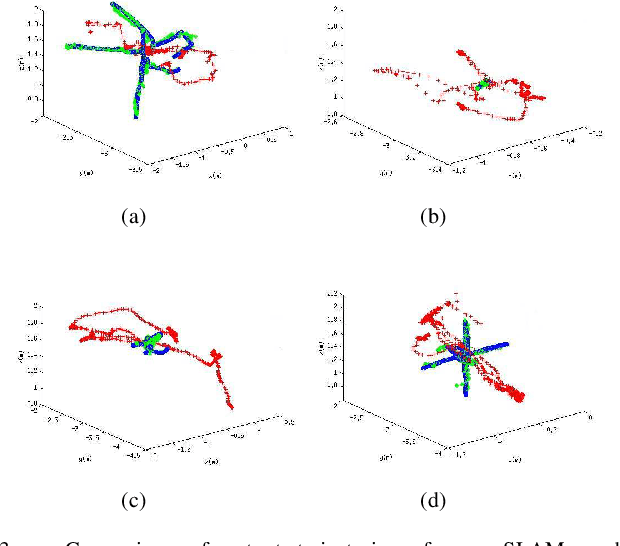

This paper presents a novel framework for simultaneously implementing localization and segmentation, which are two of the most important vision-based tasks for robotics. While the goals and techniques used for them were considered to be different previously, we show that by making use of the intermediate results of the two modules, their performance can be enhanced at the same time. Our framework is able to handle both the instantaneous motion and long-term changes of instances in localization with the help of the segmentation result, which also benefits from the refined 3D pose information. We conduct experiments on various datasets, and prove that our framework works effectively on improving the precision and robustness of the two tasks and outperforms existing localization and segmentation algorithms.
Deep Global-Relative Networks for End-to-End 6-DoF Visual Localization and Odometry
Dec 19, 2018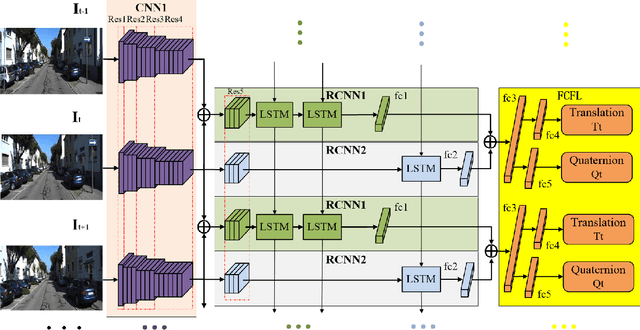

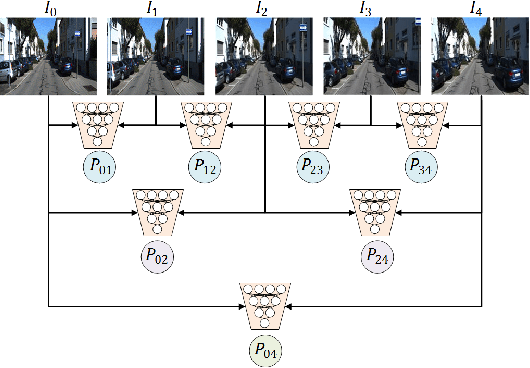

For the autonomous navigation of mobile robots, robust and fast visual localization is a challenging task. Although some end-to-end deep neural networks for 6-DoF Visual Odometry (VO) have been reported with promising results, they are still unable to solve the drift problem in long-range navigation. In this paper, we propose the deep global-relative networks (DGRNets), which is a novel global and relative fusion framework based on Recurrent Convolutional Neural Networks (RCNNs). It is designed to jointly estimate global pose and relative localization from consecutive monocular images. DGRNets include feature extraction sub-networks for discriminative feature selection, RCNNs-type relative pose estimation subnetworks for smoothing the VO trajectory and RCNNs-type global pose regression sub-networks for avoiding the accumulation of pose errors. We also propose two loss functions: the first one consists of Cross Transformation Constraints (CTC) that utilize geometric consistency of the adjacent frames to train a more accurate relative sub-networks, and the second one is composed of CTC and Mean Square Error (MSE) between the predicted pose and ground truth used to train the end-to-end DGRNets. The competitive experiments on indoor Microsoft 7-Scenes and outdoor KITTI dataset show that our DGRNets outperform other learning-based monocular VO methods in terms of pose accuracy.