 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Fuzzy Alignment Network for Text-Aerial Person Retrieval and A Large-scale Benchmark
Mar 21, 2026Text-aerial person retrieval aims to identify targets in UAV-captured images from eyewitness descriptions, supporting intelligent transportation and public security applications. Compared to ground-view text--image person retrieval, UAV-captured images often suffer from degraded visual information due to drastic variations in viewing angles and flight altitudes, making semantic alignment with textual descriptions very challenging. To address this issue, we propose a novel Cross-modal Fuzzy Alignment Network, which quantifies the token-level reliability by fuzzy logic to achieve accurate fine-grained alignment and incorporates ground-view images as a bridge agent to further mitigate the gap between aerial images and text descriptions, for text--aerial person retrieval. In particular, we design the Fuzzy Token Alignment module that employs the fuzzy membership function to dynamically model token-level association strength and suppress the influence of unobservable or noisy tokens. It can alleviate the semantic inconsistencies caused by missing visual cues and significantly enhance the robustness of token-level semantic alignment. Moreover, to further mitigate the gap between aerial images and text descriptions, we design a Context-Aware Dynamic Alignment module to incorporate the ground-view agent as a bridge in text--aerial alignment and adaptively combine direct alignment and agent-assisted alignment to improve the robustness. In addition, we construct a large-scale benchmark dataset called AERI-PEDES by using a chain-of-thought to decompose text generation into attribute parsing, initial captioning, and refinement, thus boosting textual accuracy and semantic consistency. Experiments on AERI-PEDES and TBAPR demonstrate the superiority of our method.
Structure and Progress Aware Diffusion for Medical Image Segmentation
Mar 09, 2026Medical image segmentation is crucial for computer-aided diagnosis, which necessitates understanding both coarse morphological and semantic structures, as well as carving fine boundaries. The morphological and semantic structures in medical images are beneficial and stable clues for target understanding. While the fine boundaries of medical targets (like tumors and lesions) are usually ambiguous and noisy since lesion overlap, annotation uncertainty, and so on, making it not reliable to serve as early supervision. However, existing methods simultaneously learn coarse structures and fine boundaries throughout the training process. In this paper, we propose a structure and progress-aware diffusion (SPAD) for medical image segmentation, which consists of a semantic-concentrated diffusion (ScD) and a boundary-centralized diffusion (BcD) modulated by a progress-aware scheduler (PaS). Specifically, the semantic-concentrated diffusion introduces anchor-preserved target perturbation, which perturbs pixels within a medical target but preserves unaltered areas as semantic anchors, encouraging the model to infer noisy target areas from the surrounding semantic context. The boundary-centralized diffusion introduces progress-aware boundary noise, which blurs unreliable and ambiguous boundaries, thus compelling the model to focus on coarse but stable anatomical morphology and global semantics. Furthermore, the progress-aware scheduler gradually modulates noise intensity of the ScD and BcD forming a coarse-to-fine diffusion paradigm, which encourage focusing on coarse morphological and semantic structures during early target understanding stages and gradually shifting to fine target boundaries during later contour adjusting stages.
Federated Client-tailored Adapter for Medical Image Segmentation
Apr 25, 2025Medical image segmentation in X-ray images is beneficial for computer-aided diagnosis and lesion localization. Existing methods mainly fall into a centralized learning paradigm, which is inapplicable in the practical medical scenario that only has access to distributed data islands. Federated Learning has the potential to offer a distributed solution but struggles with heavy training instability due to client-wise domain heterogeneity (including distribution diversity and class imbalance). In this paper, we propose a novel Federated Client-tailored Adapter (FCA) framework for medical image segmentation, which achieves stable and client-tailored adaptive segmentation without sharing sensitive local data. Specifically, the federated adapter stirs universal knowledge in off-the-shelf medical foundation models to stabilize the federated training process. In addition, we develop two client-tailored federated updating strategies that adaptively decompose the adapter into common and individual components, then globally and independently update the parameter groups associated with common client-invariant and individual client-specific units, respectively. They further stabilize the heterogeneous federated learning process and realize optimal client-tailored instead of sub-optimal global-compromised segmentation models. Extensive experiments on three large-scale datasets demonstrate the effectiveness and superiority of the proposed FCA framework for federated medical segmentation.
Progressive Relation Learning for Group Activity Recognition
Aug 08, 2019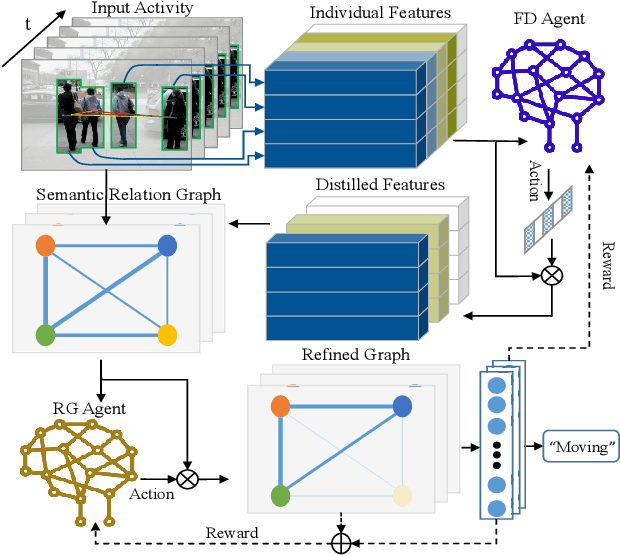
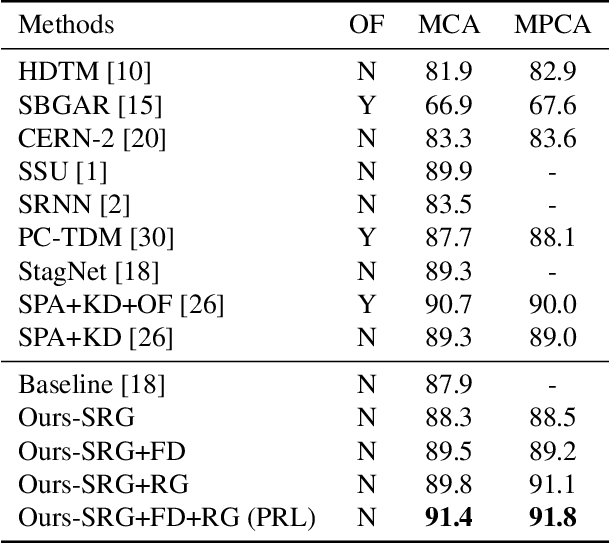
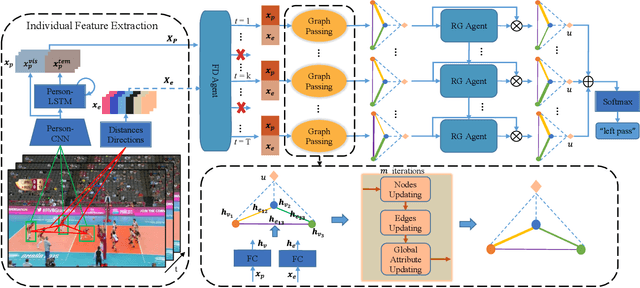
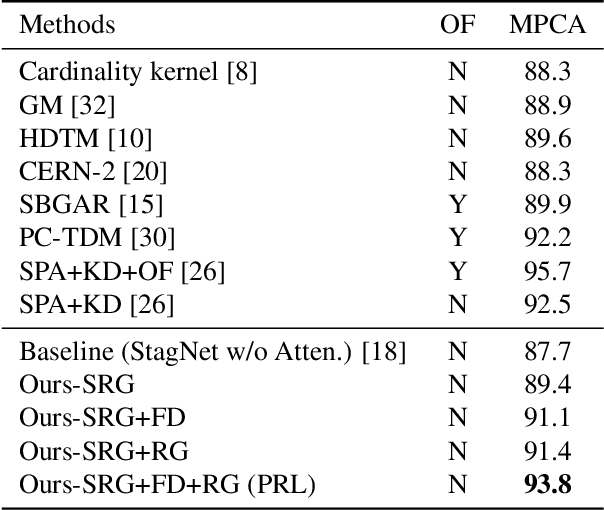
Group activities usually involve spatio-temporal dynamics among many interactive individuals, while only a few participants at several key frames essentially define the activity. Therefore, effectively modeling the group-relevant and suppressing the irrelevant actions (and interactions) are vital for group activity recognition. In this paper, we propose a novel method based on deep reinforcement learning to progressively refine the low-level features and high-level relations of group activities. Firstly, we construct a semantic relation graph (SRG) to explicitly model the relations among persons. Then, two agents adopting policy according to two Markov decision processes are applied to progressively refine the SRG. Specifically, one feature-distilling (FD) agent in the discrete action space refines the low-level spatio-temporal features by distilling the most informative frames. Another relation-gating (RG) agent in continuous action space adjusts the high-level semantic graph to pay more attention to group-relevant relations. The SRG, FD agent, and RG agent are optimized alternately to mutually boost the performance of each other. Extensive experiments on two widely used benchmarks demonstrate the effectiveness and superiority of the proposed approach.
Skeleton-Based Action Recognition with Synchronous Local and Non-local Spatio-temporal Learning and Frequency Attention
Nov 10, 2018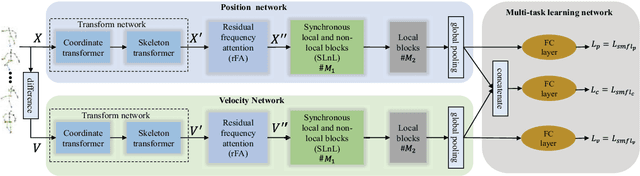
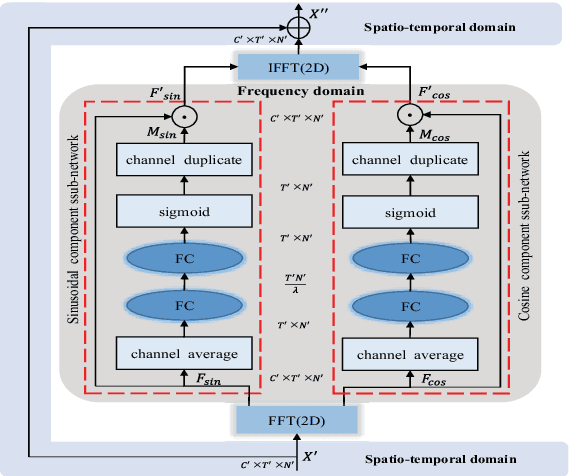
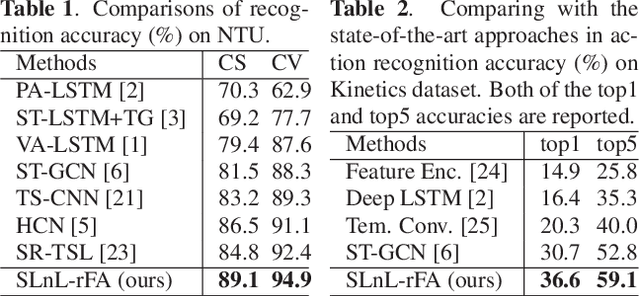
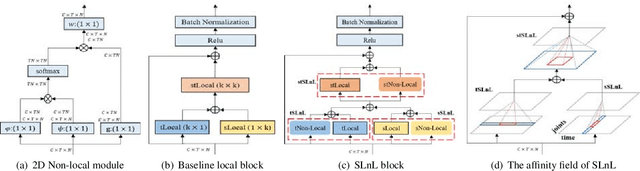
Benefiting from its succinctness and robustness, skeleton-based human action recognition has recently attracted much attention. Most existing methods utilize local networks, such as recurrent networks, convolutional neural networks, and graph convolutional networks, to extract spatio-temporal dynamics hierarchically. As a consequence, the local and non-local dependencies, which respectively contain more details and semantics, are asynchronously captured in different level of layers. Moreover, limited to the spatio-temporal domain, these methods ignored patterns in the frequency domain. To better extract information from multi-domains, we propose a residual frequency attention (rFA) to focus on discriminative patterns in the frequency domain, and a synchronous local and non-local (SLnL) block to simultaneously capture the details and semantics in the spatio-temporal domain. To optimize the whole process, we also propose a soft-margin focal loss (SMFL), which can automatically conducts adaptive data selection and encourages intrinsic margins in classifiers. Extensive experiments are performed on several large-scale action recognition datasets and our approach significantly outperforms other state-of-the-art methods.