 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Oriented Framework for Optical Flow-based Multi-User Multi-Task Video Transmission
Mar 20, 2026Efficient multi-user multi-task video transmission is an important research topic within the realm of current wireless communication systems. To reduce the transmission burden and save communication resources, we propose a goal-oriented semantic communication framework for optical flow-based multi-user multi-task video transmission (OF-GSC). At the transmitter, we design a semantic encoder that consists of a motion extractor and a patch-level optical flow-based semantic representation extractor to effectively identify and select important semantic representations. At the receiver, we design a transformer-based semantic decoder for high-quality video reconstruction and video classification tasks. To minimize the communication time, we develop a deep deterministic policy gradient (DDPG)-based bandwidth allocation algorithm for multi-user transmission. For video reconstruction tasks, our OF-GSC framework achieves a significant improvement in the received video quality, as evidenced by a 13.47% increase in the structural similarity index measure (SSIM) score in comparison to DeepJSCC. For video classification tasks, OF-GSC achieves a Top-1 accuracy slightly surpassing the performance of VideoMAE with only 25% required data under the same mask ratio of 0.3. For bandwidth allocation optimization, our DDPG-based algorithm reduces the maximum transmission time by 25.97% compared with the baseline equal-bandwidth allocation scheme.
Parameter-Efficient MoE LoRA for Few-Shot Multi-Style Editing
Nov 14, 2025
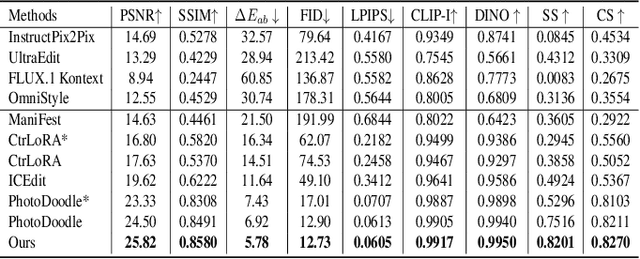

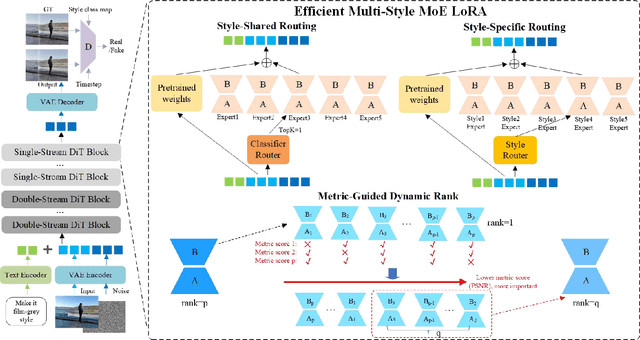
In recent years, image editing has garnered growing attention. However, general image editing models often fail to produce satisfactory results when confronted with new styles. The challenge lies in how to effectively fine-tune general image editing models to new styles using only a limited amount of paired data. To address this issue, this paper proposes a novel few-shot style editing framework. For this task, we construct a benchmark dataset that encompasses five distinct styles. Correspondingly, we propose a parameter-efficient multi-style Mixture-of-Experts Low-Rank Adaptation (MoE LoRA) with style-specific and style-shared routing mechanisms for jointly fine-tuning multiple styles. The style-specific routing ensures that different styles do not interfere with one another, while the style-shared routing adaptively allocates shared MoE LoRAs to learn common patterns. Our MoE LoRA can automatically determine the optimal ranks for each layer through a novel metric-guided approach that estimates the importance score of each single-rank component. Additionally, we explore the optimal location to insert LoRA within the Diffusion in Transformer (DiT) model and integrate adversarial learning and flow matching to guide the diffusion training process. Experimental results demonstrate that our proposed method outperforms existing state-of-the-art approaches with significantly fewer LoRA parameters.
Threshold Attention Network for Semantic Segmentation of Remote Sensing Images
Jan 14, 2025



Semantic segmentation of remote sensing images is essential for various applications, including vegetation monitoring, disaster management, and urban planning. Previous studies have demonstrated that the self-attention mechanism (SA) is an effective approach for designing segmentation networks that can capture long-range pixel dependencies. SA enables the network to model the global dependencies between the input features, resulting in improved segmentation outcomes. However, the high density of attentional feature maps used in this mechanism causes exponential increases in computational complexity. Additionally, it introduces redundant information that negatively impacts the feature representation. Inspired by traditional threshold segmentation algorithms, we propose a novel threshold attention mechanism (TAM). This mechanism significantly reduces computational effort while also better modeling the correlation between different regions of the feature map. Based on TAM, we present a threshold attention network (TANet) for semantic segmentation. TANet consists of an attentional feature enhancement module (AFEM) for global feature enhancement of shallow features and a threshold attention pyramid pooling module (TAPP) for acquiring feature information at different scales for deep features. We have conducted extensive experiments on the ISPRS Vaihingen and Potsdam datasets. The results demonstrate the validity and superiority of our proposed TANet compared to the most state-of-the-art models.
Task-Oriented Semantics-Aware Communication for Wireless UAV Control and Command Transmission
Jun 25, 2023To guarantee the safety and smooth control of Unmanned Aerial Vehicle (UAV) operation, the new control and command (C&C) data type imposes stringent quality of service (QoS) requirements on the cellular network. However, the existing bit-oriented communication framework is already approaching the Shannon capacity limit, which can hardly guarantee the ultra-reliable low latency communications (URLLC) service for C&C transmission. To solve the problem, task-oriented semantics-aware (TOSA) communication has been proposed recently by jointly exploiting the context of data and its importance to the UAV control task. However, to the best of our knowledge, an explicit and systematic TOSA communication framework for emerging C&C data type remains unknown. Therefore, in this paper, we propose a TOSA communication framework for C&C transmission and define its value of information based on both the similarity and age of information (AoI) of C&C signals. We also propose a deep reinforcement learning (DRL) algorithm to maximize the TOSA information. Last but not least, we present the simulation results to validate the effectiveness of our proposed TOSA communication framework.
An Unsupervised Masking Objective for Abstractive Multi-Document News Summarization
Jan 07, 2022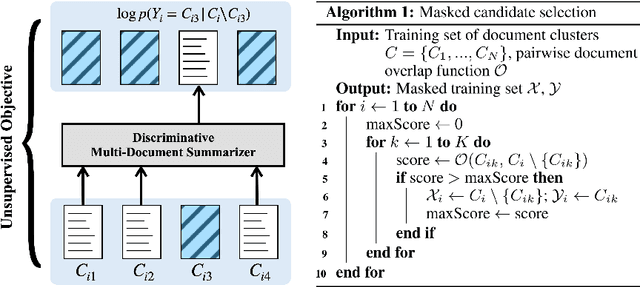

We show that a simple unsupervised masking objective can approach near supervised performance on abstractive multi-document news summarization. Our method trains a state-of-the-art neural summarization model to predict the masked out source document with highest lexical centrality relative to the multi-document group. In experiments on the Multi-News dataset, our masked training objective yields a system that outperforms past unsupervised methods and, in human evaluation, surpasses the best supervised method without requiring access to any ground-truth summaries. Further, we evaluate how different measures of lexical centrality, inspired by past work on extractive summarization, affect final performance.