 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Limitations in Open Source Arabic-Script OCR: A Case Study
Feb 08, 2024



This work presents an accuracy study of the open source OCR engine, Kraken, on the leading Arabic scholarly journal, al-Abhath. In contrast with other commercially available OCR engines, Kraken is shown to be capable of producing highly accurate Arabic-script OCR. The study also assesses the relative accuracy of typeface-specific and generalized models on the al-Abhath data and provides a microanalysis of the ``error instances'' and the contextual features that may have contributed to OCR misrecognition. Building on this analysis, the paper argues that Arabic-script OCR can be significantly improved through (1) a more systematic approach to training data production, and (2) the development of key technological components, especially multi-language models and improved line segmentation and layout analysis. Cet article pr{\'e}sente une {\'e}tude d'exactitude du moteur ROC open source, Krakan, sur la revue acad{\'e}mique arabe de premier rang, al-Abhath. Contrairement {\`a} d'autres moteurs ROC disponibles sur le march{\'e}, Kraken se r{\'e}v{\`e}le {\^e}tre capable de produire de la ROC extr{\^e}mement exacte de l'{\'e}criture arabe. L'{\'e}tude {\'e}value aussi l'exactitude relative des mod{\`e}les sp{\'e}cifiquement configur{\'e}s {\`a} des polices et celle des mod{\`e}les g{\'e}n{\'e}ralis{\'e}s sur les donn{\'e}es d'al-Abhath et fournit une microanalyse des "occurrences d'erreurs", ainsi qu'une microanalyse des {\'e}l{\'e}ments contextuels qui pourraient avoir contribu{\'e} {\`a} la m{\'e}reconnaissance ROC. S'appuyant sur cette analyse, cet article fait valoir que la ROC de l'{\'e}criture arabe peut {\^e}tre consid{\'e}rablement am{\'e}lior{\'e}e gr{\^a}ce {\`a} (1) une approche plus syst{\'e}matique d'entra{\^i}nement de la production de donn{\'e}es et (2) gr{\^a}ce au d{\'e}veloppement de composants technologiques fondamentaux, notammentl'am{\'e}lioration des mod{\`e}les multilingues, de la segmentation de ligne et de l'analyse de la mise en page.
Lacuna Reconstruction: Self-supervised Pre-training for Low-Resource Historical Document Transcription
Dec 16, 2021
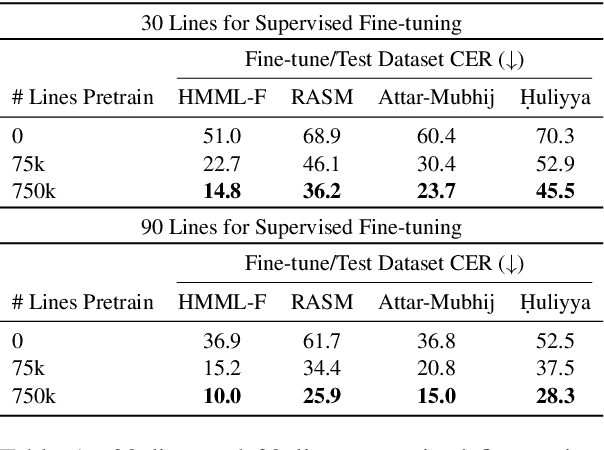
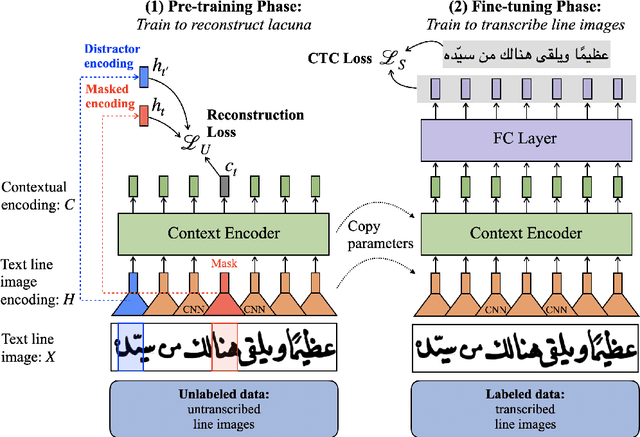

We present a self-supervised pre-training approach for learning rich visual language representations for both handwritten and printed historical document transcription. After supervised fine-tuning of our pre-trained encoder representations for low-resource document transcription on two languages, (1) a heterogeneous set of handwritten Islamicate manuscript images and (2) early modern English printed documents, we show a meaningful improvement in recognition accuracy over the same supervised model trained from scratch with as few as 30 line image transcriptions for training. Our masked language model-style pre-training strategy, where the model is trained to be able to identify the true masked visual representation from distractors sampled from within the same line, encourages learning robust contextualized language representations invariant to scribal writing style and printing noise present across documents.
BADAM: A Public Dataset for Baseline Detection in Arabic-script Manuscripts
Jul 09, 2019



The application of handwritten text recognition to historical works is highly dependant on accurate text line retrieval. A number of systems utilizing a robust baseline detection paradigm have emerged recently but the advancement of layout analysis methods for challenging scripts is held back by the lack of well-established datasets including works in non-Latin scripts. We present a dataset of 400 annotated document images from different domains and time periods. A short elaboration on the particular challenges posed by handwriting in Arabic script for layout analysis and subsequent processing steps is given. Lastly, we propose a method based on a fully convolutional encoder-decoder network to extract arbitrarily shaped text line images from manuscripts.
Important New Developments in Arabographic Optical Character Recognition (OCR)
Mar 28, 2017



The OpenITI team has achieved Optical Character Recognition (OCR) accuracy rates for classical Arabic-script texts in the high nineties. These numbers are based on our tests of seven different Arabic-script texts of varying quality and typefaces, totaling over 7,000 lines. These accuracy rates not only represent a distinct improvement over the actual accuracy rates of the various proprietary OCR options for classical Arabic-script texts, but, equally important, they are produced using an open-source OCR software, thus enabling us to make this Arabic-script OCR technology freely available to the broader Islamic, Persian, and Arabic Studies communities.