 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Sentence Interactions Matter? Leveraging Sentence Level Representations for Fake News Classification
Oct 27, 2019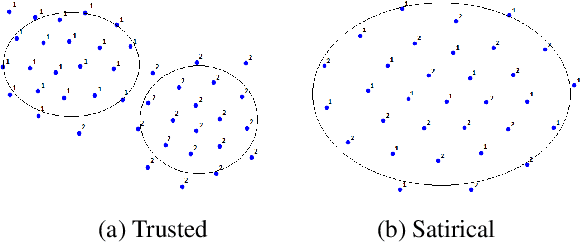


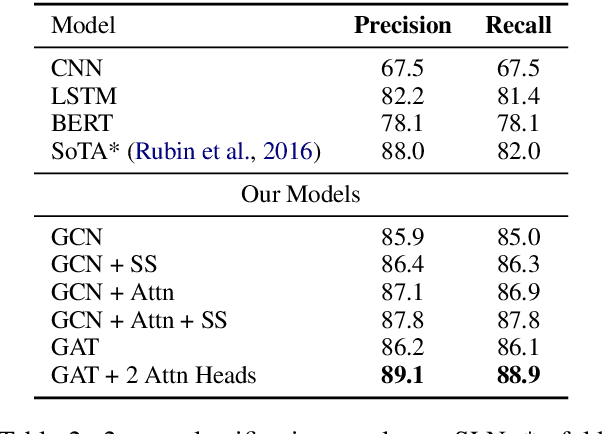
The rising growth of fake news and misleading information through online media outlets demands an automatic method for detecting such news articles. Of the few limited works which differentiate between trusted vs other types of news article (satire, propaganda, hoax), none of them model sentence interactions within a document. We observe an interesting pattern in the way sentences interact with each other across different kind of news articles. To capture this kind of information for long news articles, we propose a graph neural network-based model which does away with the need of feature engineering for fine grained fake news classification. Through experiments, we show that our proposed method beats strong neural baselines and achieves state-of-the-art accuracy on existing datasets. Moreover, we establish the generalizability of our model by evaluating its performance in out-of-domain scenarios. Code is available at https://github.com/MysteryVaibhav/fake_news_semantics
Improving Robustness of Machine Translation with Synthetic Noise
Apr 10, 2019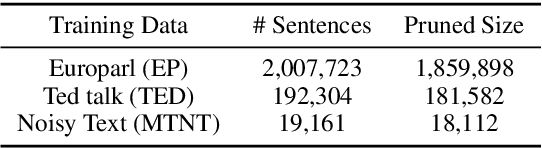

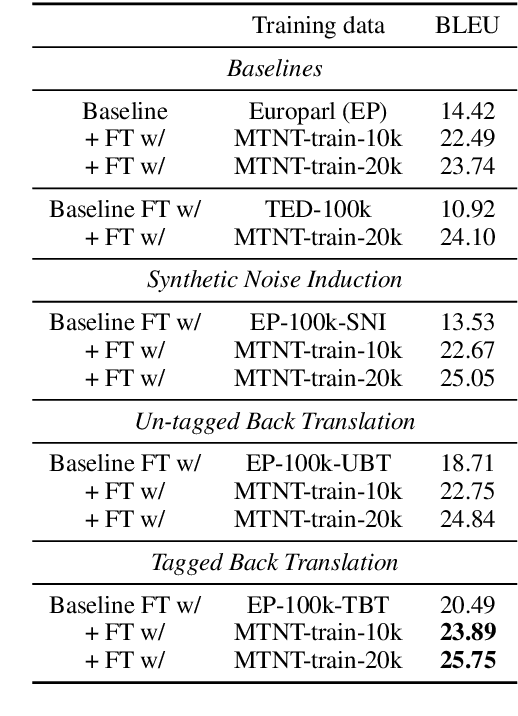
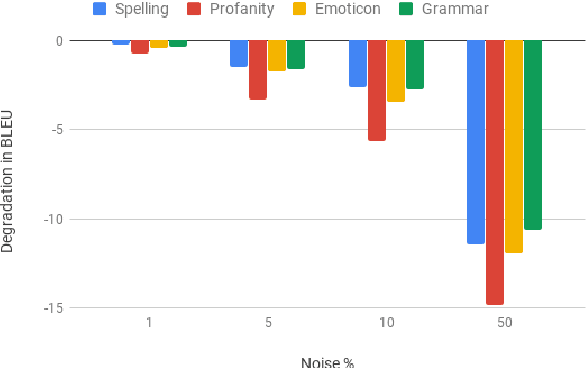
Modern Machine Translation (MT) systems perform consistently well on clean, in-domain text. However most human generated text, particularly in the realm of social media, is full of typos, slang, dialect, idiolect and other noise which can have a disastrous impact on the accuracy of output translation. In this paper we leverage the Machine Translation of Noisy Text (MTNT) dataset to enhance the robustness of MT systems by emulating naturally occurring noise in otherwise clean data. Synthesizing noise in this manner we are ultimately able to make a vanilla MT system resilient to naturally occurring noise and partially mitigate loss in accuracy resulting therefrom.