 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Sentence Interactions Matter? Leveraging Sentence Level Representations for Fake News Classification
Oct 27, 2019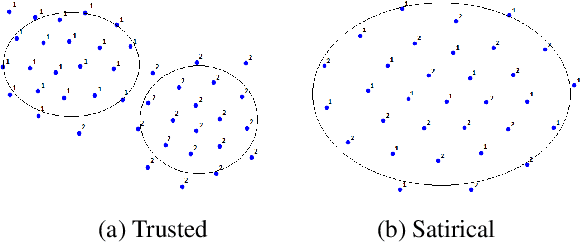


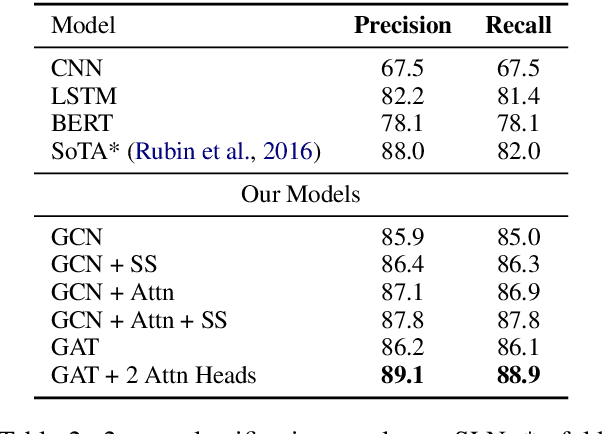
The rising growth of fake news and misleading information through online media outlets demands an automatic method for detecting such news articles. Of the few limited works which differentiate between trusted vs other types of news article (satire, propaganda, hoax), none of them model sentence interactions within a document. We observe an interesting pattern in the way sentences interact with each other across different kind of news articles. To capture this kind of information for long news articles, we propose a graph neural network-based model which does away with the need of feature engineering for fine grained fake news classification. Through experiments, we show that our proposed method beats strong neural baselines and achieves state-of-the-art accuracy on existing datasets. Moreover, we establish the generalizability of our model by evaluating its performance in out-of-domain scenarios. Code is available at https://github.com/MysteryVaibhav/fake_news_semantics
Towards Better Interpretability in Deep Q-Networks
Sep 15, 2018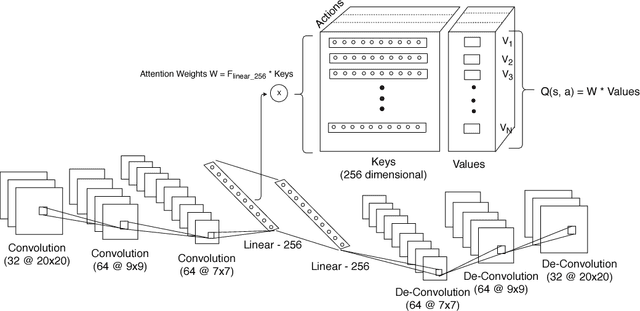
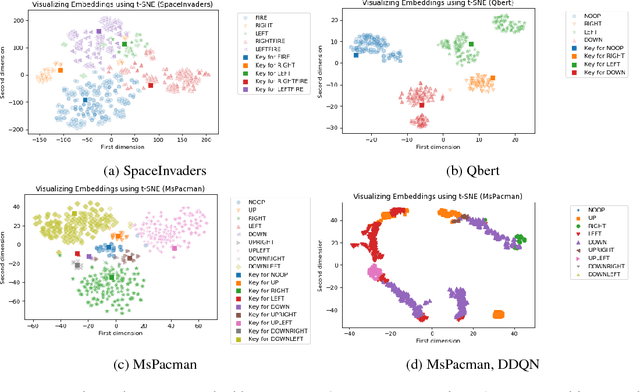
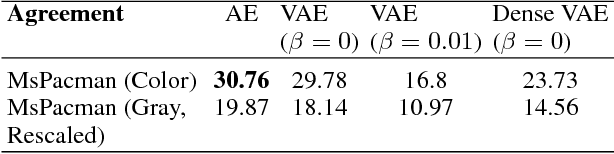
Deep reinforcement learning techniques have demonstrated superior performance in a wide variety of environments. As improvements in training algorithms continue at a brisk pace, theoretical or empirical studies on understanding what these networks seem to learn, are far behind. In this paper we propose an interpretable neural network architecture for Q-learning which provides a global explanation of the model's behavior using key-value memories, attention and reconstructible embeddings. With a directed exploration strategy, our model can reach training rewards comparable to the state-of-the-art deep Q-learning models. However, results suggest that the features extracted by the neural network are extremely shallow and subsequent testing using out-of-sample examples shows that the agent can easily overfit to trajectories seen during training.
Combining Model-Free Q-Ensembles and Model-Based Approaches for Informed Exploration
Jun 12, 2018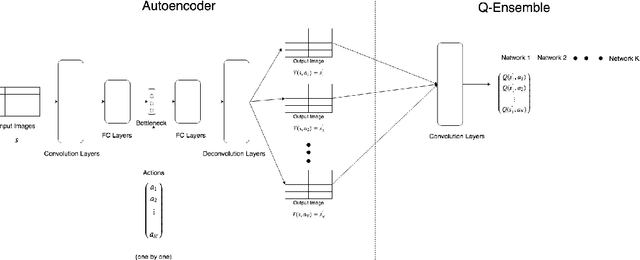
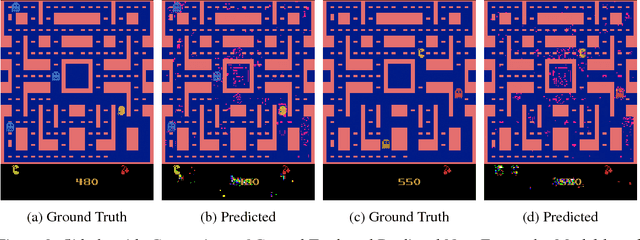
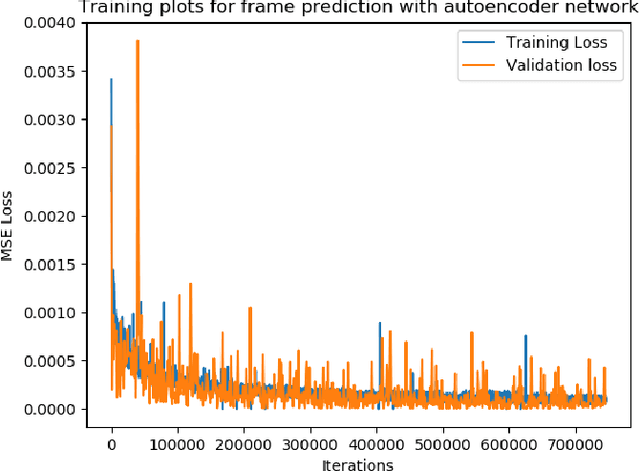
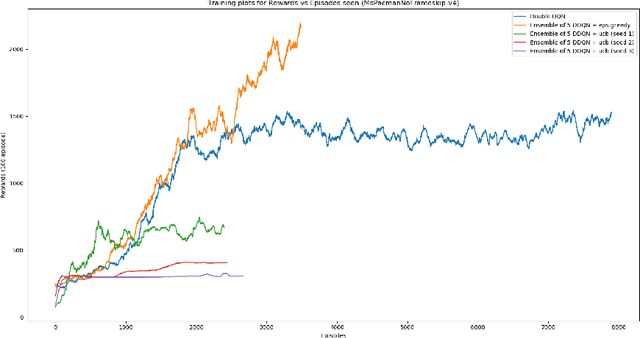
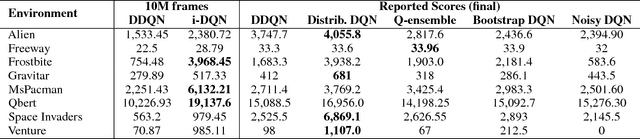
Q-Ensembles are a model-free approach where input images are fed into different Q-networks and exploration is driven by the assumption that uncertainty is proportional to the variance of the output Q-values obtained. They have been shown to perform relatively well compared to other exploration strategies. Further, model-based approaches, such as encoder-decoder models have been used successfully for next frame prediction given previous frames. This paper proposes to integrate the model-free Q-ensembles and model-based approaches with the hope of compounding the benefits of both and achieving superior exploration as a result. Results show that a model-based trajectory memory approach when combined with Q-ensembles produces superior performance when compared to only using Q-ensembles.