 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Interpretability in Deep Q-Networks
Paper and Code
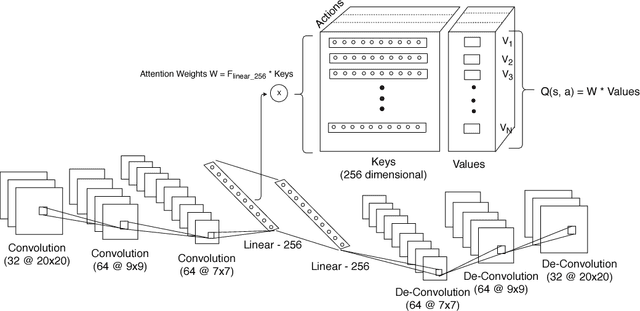
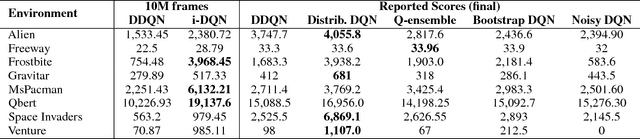
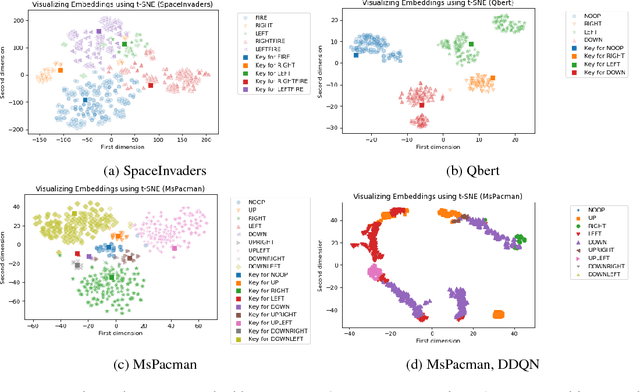
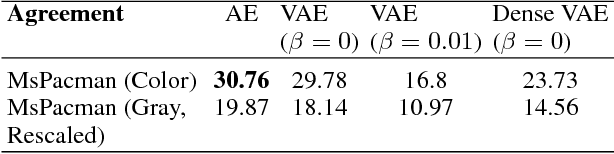
Deep reinforcement learning techniques have demonstrated superior performance in a wide variety of environments. As improvements in training algorithms continue at a brisk pace, theoretical or empirical studies on understanding what these networks seem to learn, are far behind. In this paper we propose an interpretable neural network architecture for Q-learning which provides a global explanation of the model's behavior using key-value memories, attention and reconstructible embeddings. With a directed exploration strategy, our model can reach training rewards comparable to the state-of-the-art deep Q-learning models. However, results suggest that the features extracted by the neural network are extremely shallow and subsequent testing using out-of-sample examples shows that the agent can easily overfit to trajectories seen during training.