 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Latent Variable Models for Semi-supervised Paraphrase Generation
Jan 05, 2023



This paper explores deep latent variable models for semi-supervised paraphrase generation, where the missing target pair is modelled as a latent paraphrase sequence. We present a novel unsupervised model named variational sequence auto-encoding reconstruction (VSAR), which performs latent sequence inference given an observed text. To leverage information from text pairs, we introduce a supervised model named dual directional learning (DDL). Combining VSAR with DDL (DDL+VSAR) enables us to conduct semi-supervised learning; however, the combined model suffers from a cold-start problem. To combat this issue, we propose to deal with better weight initialisation, leading to a two-stage training scheme named knowledge reinforced training. Our empirical evaluations suggest that the combined model yields competitive performance against the state-of-the-art supervised baselines on complete data. Furthermore, in scenarios where only a fraction of the labelled pairs are available, our combined model consistently outperforms the strong supervised model baseline (DDL and Transformer) by a significant margin.
Religion and Spirituality on Social Media in the Aftermath of the Global Pandemic
Dec 11, 2022
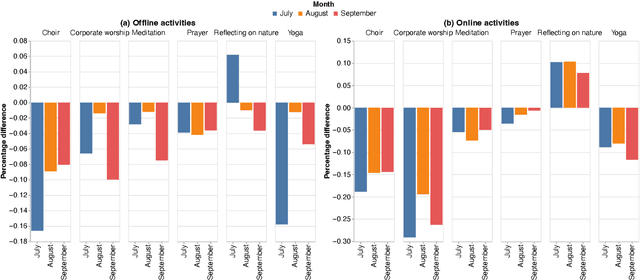
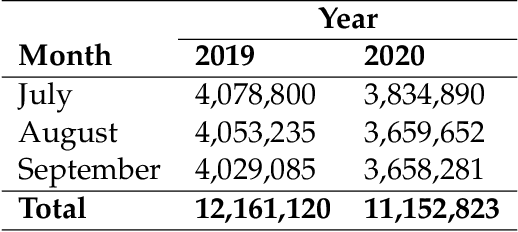
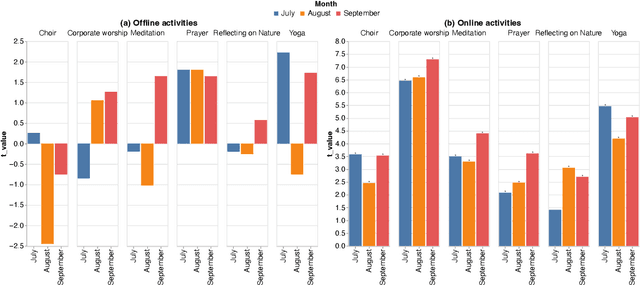
During the COVID-19 pandemic, the Church closed its physical doors for the first time in about 800 years, which is, arguably, a cataclysmic event. Other religions have found themselves in a similar situation, and they were practically forced to move online, which is an unprecedented occasion. In this paper, we analyse this sudden change in religious activities twofold: we create and deliver a questionnaire, as well as analyse Twitter data, to understand people's perceptions and activities related to religious activities online. Importantly, we also analyse the temporal variations in this process by analysing a period of 3 months: July-September 2020. Additionally to the separate analysis of the two data sources, we also discuss the implications from triangulating the results.
Multi-task Learning for Personal Health Mention Detection on Social Media
Dec 09, 2022


Detecting personal health mentions on social media is essential to complement existing health surveillance systems. However, annotating data for detecting health mentions at a large scale is a challenging task. This research employs a multitask learning framework to leverage available annotated data from a related task to improve the performance on the main task to detect personal health experiences mentioned in social media texts. Specifically, we focus on incorporating emotional information into our target task by using emotion detection as an auxiliary task. Our approach significantly improves a wide range of personal health mention detection tasks compared to a strong state-of-the-art baseline.
Incorporating Emotions into Health Mention Classification Task on Social Media
Dec 09, 2022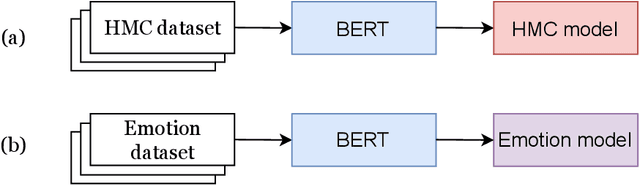



The health mention classification (HMC) task is the process of identifying and classifying mentions of health-related concepts in text. This can be useful for identifying and tracking the spread of diseases through social media posts. However, this is a non-trivial task. Here we build on recent studies suggesting that using emotional information may improve upon this task. Our study results in a framework for health mention classification that incorporates affective features. We present two methods, an intermediate task fine-tuning approach (implicit) and a multi-feature fusion approach (explicit) to incorporate emotions into our target task of HMC. We evaluated our approach on 5 HMC-related datasets from different social media platforms including three from Twitter, one from Reddit and another from a combination of social media sources. Extensive experiments demonstrate that our approach results in statistically significant performance gains on HMC tasks. By using the multi-feature fusion approach, we achieve at least a 3% improvement in F1 score over BERT baselines across all datasets. We also show that considering only negative emotions does not significantly affect performance on the HMC task. Additionally, our results indicate that HMC models infused with emotional knowledge are an effective alternative, especially when other HMC datasets are unavailable for domain-specific fine-tuning. The source code for our models is freely available at https://github.com/tahirlanre/Emotion_PHM.
INTERACTION: A Generative XAI Framework for Natural Language Inference Explanations
Sep 02, 2022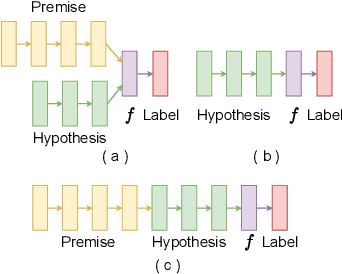
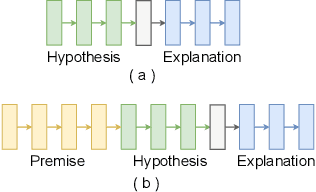
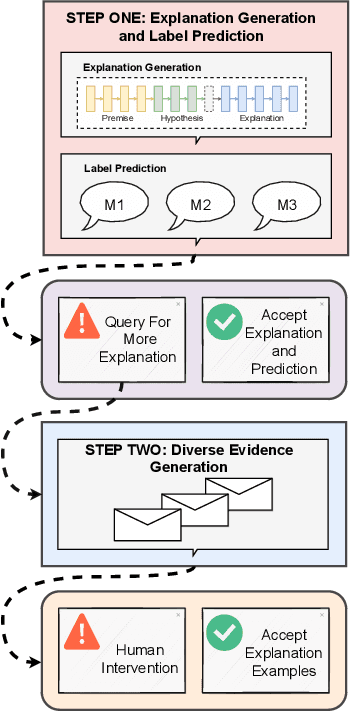

XAI with natural language processing aims to produce human-readable explanations as evidence for AI decision-making, which addresses explainability and transparency. However, from an HCI perspective, the current approaches only focus on delivering a single explanation, which fails to account for the diversity of human thoughts and experiences in language. This paper thus addresses this gap, by proposing a generative XAI framework, INTERACTION (explaIn aNd predicT thEn queRy with contextuAl CondiTional varIational autO-eNcoder). Our novel framework presents explanation in two steps: (step one) Explanation and Label Prediction; and (step two) Diverse Evidence Generation. We conduct intensive experiments with the Transformer architecture on a benchmark dataset, e-SNLI. Our method achieves competitive or better performance against state-of-the-art baseline models on explanation generation (up to 4.7% gain in BLEU) and prediction (up to 4.4% gain in accuracy) in step one; it can also generate multiple diverse explanations in step two.