 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Recurrent Neural Network Responsiveness to Acute Clinical Events
Jul 28, 2020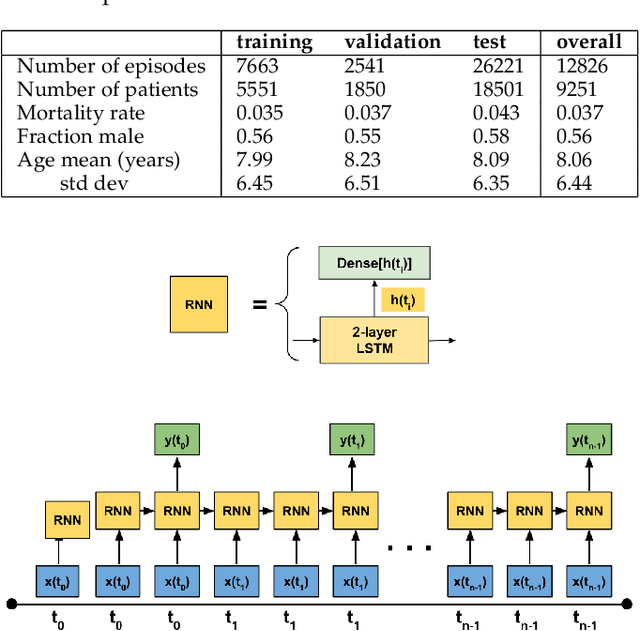
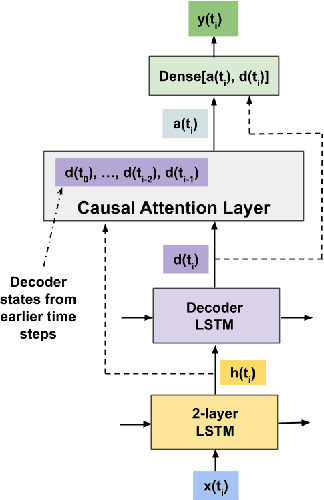

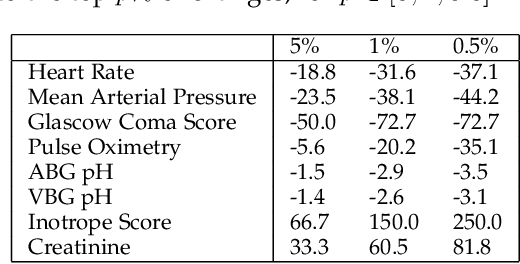
Predictive models in acute care settings must be able to immediately recognize precipitous changes in a patient's status when presented with data reflecting such changes. Recurrent neural networks (RNNs) have become common for training and deploying clinical decision support models. They frequently exhibit a delayed response to acute events. New information must propagate through the RNN's cell state memory before the total impact is reflected in the model's predictions. This work presents input data perseveration as a method of training and deploying an RNN model to make its predictions more responsive to newly acquired information: input data is replicated during training and deployment. Each replication of the data input impacts the cell state and output of the RNN, but only the output at the final replication is maintained and broadcast as the prediction for evaluation and deployment purposes. When presented with data reflecting acute events, a model trained and deployed with input perseveration responds with more pronounced immediate changes in predictions and maintains globally robust performance. Such a characteristic is crucial in predictive models for an intensive care unit.
The Impact of Extraneous Variables on the Performance of Recurrent Neural Network Models in Clinical Tasks
Apr 01, 2019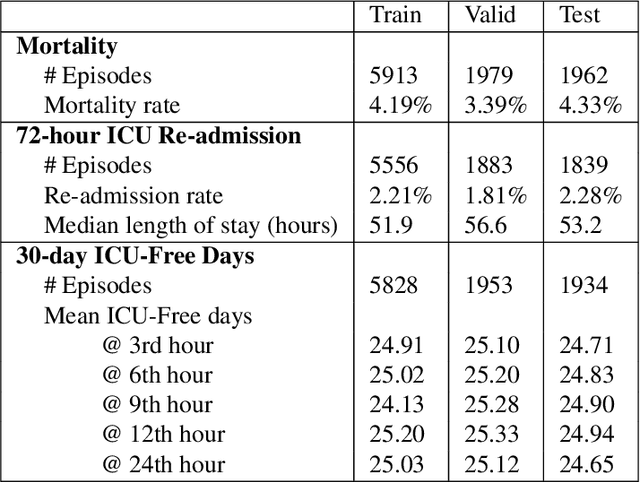
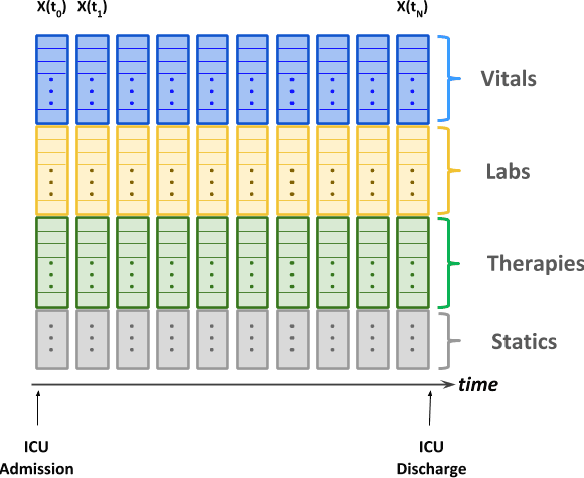
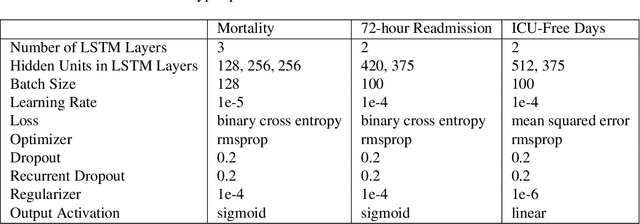
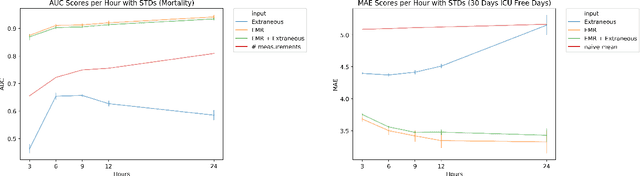
Electronic Medical Records (EMR) are a rich source of patient information, including measurements reflecting physiologic signs and administered therapies. Identifying which variables are useful in predicting clinical outcomes can be challenging. Advanced algorithms such as deep neural networks were designed to process high-dimensional inputs containing variables in their measured form, thus bypass separate feature selection or engineering steps. We investigated the effect of extraneous input variables on the predictive performance of Recurrent Neural Networks (RNN) by including in the input vector extraneous variables randomly drawn from theoretical and empirical distributions. RNN models using different input vectors (EMR variables; EMR and extraneous variables; extraneous variables only) were trained to predict three clinical outcomes: in-ICU mortality, 72-hour ICU re-admission, and 30-day ICU-free days. The measured degradations of the RNN's predictive performance with the addition of extraneous variables to EMR variables were negligible.
Affect-LM: A Neural Language Model for Customizable Affective Text Generation
Apr 22, 2017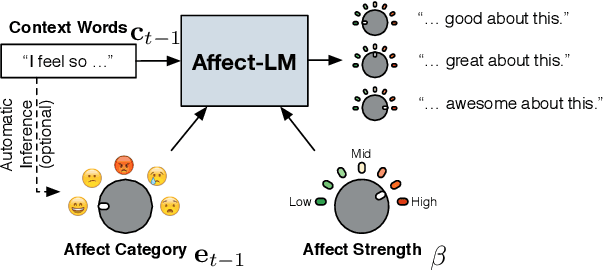
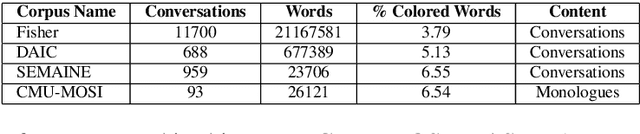

Human verbal communication includes affective messages which are conveyed through use of emotionally colored words. There has been a lot of research in this direction but the problem of integrating state-of-the-art neural language models with affective information remains an area ripe for exploration. In this paper, we propose an extension to an LSTM (Long Short-Term Memory) language model for generating conversational text, conditioned on affect categories. Our proposed model, Affect-LM enables us to customize the degree of emotional content in generated sentences through an additional design parameter. Perception studies conducted using Amazon Mechanical Turk show that Affect-LM generates naturally looking emotional sentences without sacrificing grammatical correctness. Affect-LM also learns affect-discriminative word representations, and perplexity experiments show that additional affective information in conversational text can improve language model prediction.
Learning Representations of Affect from Speech
Feb 14, 2016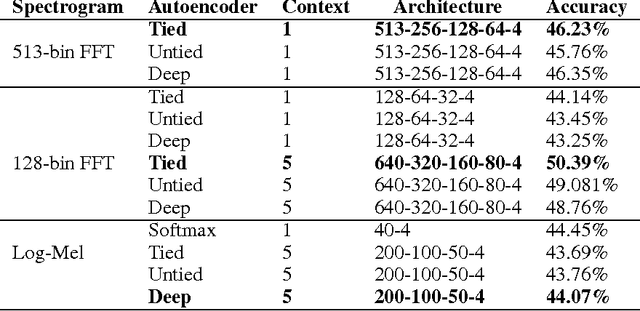

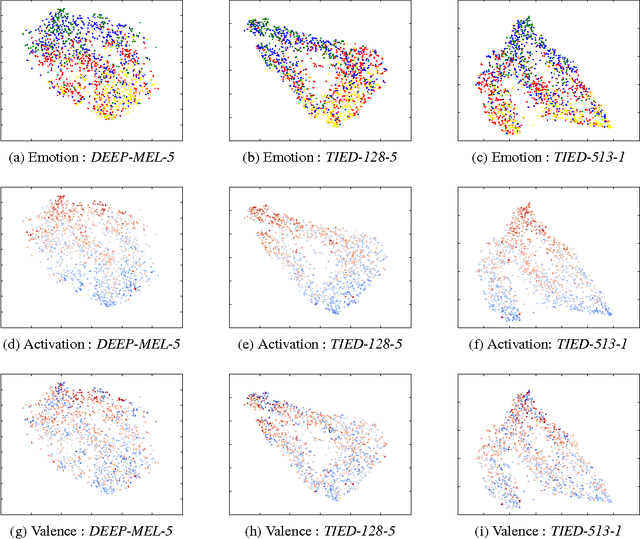
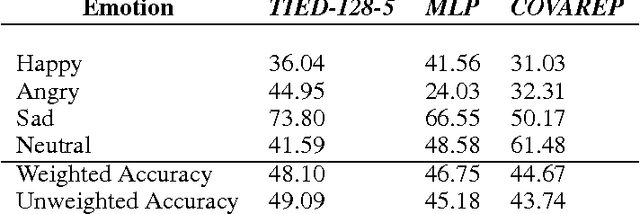
There has been a lot of prior work on representation learning for speech recognition applications, but not much emphasis has been given to an investigation of effective representations of affect from speech, where the paralinguistic elements of speech are separated out from the verbal content. In this paper, we explore denoising autoencoders for learning paralinguistic attributes i.e. categorical and dimensional affective traits from speech. We show that the representations learnt by the bottleneck layer of the autoencoder are highly discriminative of activation intensity and at separating out negative valence (sadness and anger) from positive valence (happiness). We experiment with different input speech features (such as FFT and log-mel spectrograms with temporal context windows), and different autoencoder architectures (such as stacked and deep autoencoders). We also learn utterance specific representations by a combination of denoising autoencoders and BLSTM based recurrent autoencoders. Emotion classification is performed with the learnt temporal/dynamic representations to evaluate the quality of the representations. Experiments on a well-established real-life speech dataset (IEMOCAP) show that the learnt representations are comparable to state of the art feature extractors (such as voice quality features and MFCCs) and are competitive with state-of-the-art approaches at emotion and dimensional affect recognition.