 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations of Emotional Speech with Deep Convolutional Generative Adversarial Networks
Paper and Code
Apr 22, 2017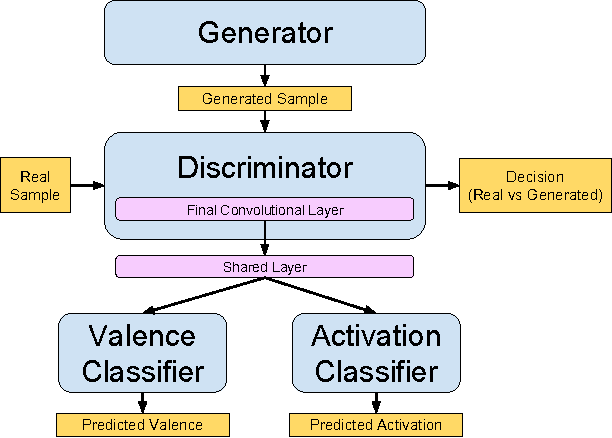
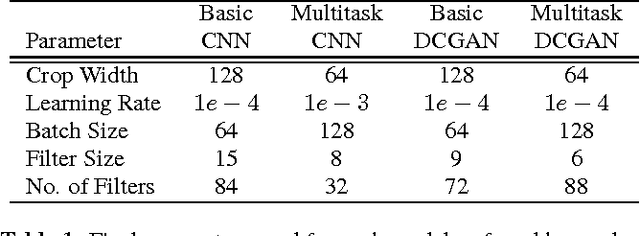
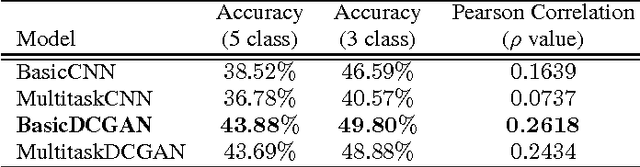
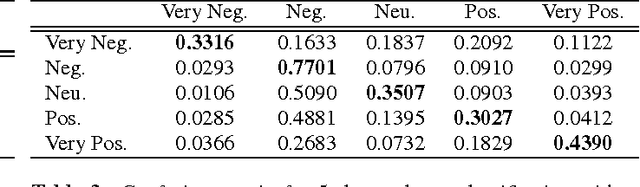
Automatically assessing emotional valence in human speech has historically been a difficult task for machine learning algorithms. The subtle changes in the voice of the speaker that are indicative of positive or negative emotional states are often "overshadowed" by voice characteristics relating to emotional intensity or emotional activation. In this work we explore a representation learning approach that automatically derives discriminative representations of emotional speech. In particular, we investigate two machine learning strategies to improve classifier performance: (1) utilization of unlabeled data using a deep convolutional generative adversarial network (DCGAN), and (2) multitask learning. Within our extensive experiments we leverage a multitask annotated emotional corpus as well as a large unlabeled meeting corpus (around 100 hours). Our speaker-independent classification experiments show that in particular the use of unlabeled data in our investigations improves performance of the classifiers and both fully supervised baseline approaches are outperformed considerably. We improve the classification of emotional valence on a discrete 5-point scale to 43.88% and on a 3-point scale to 49.80%, which is competitive to state-of-the-art performance.