 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Prior Learning for Bayesian Optimisation
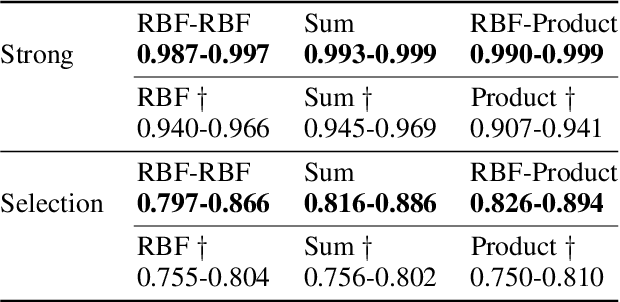
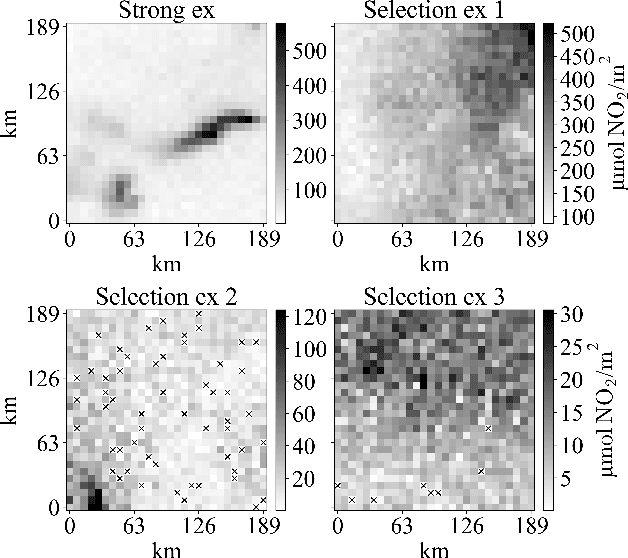
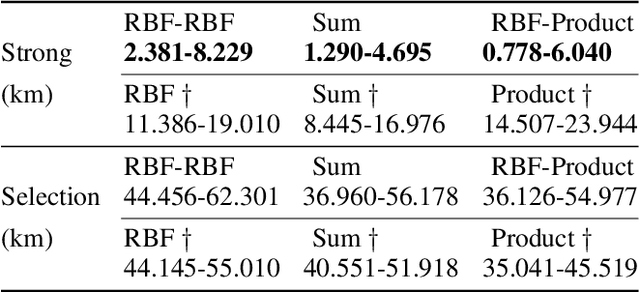
Nov 24, 2023Transfer learning for Bayesian optimisation has generally assumed a strong similarity between optimisation tasks, with at least a subset having similar optimal inputs. This assumption can reduce computational costs, but it is violated in a wide range of optimisation problems where transfer learning may nonetheless be useful. We replace this assumption with a weaker one only requiring the shape of the optimisation landscape to be similar, and analyse the recent method Prior Learning for Bayesian Optimisation - PLeBO - in this setting. By learning priors for the hyperparameters of the Gaussian process surrogate model we can better approximate the underlying function, especially for few function evaluations. We validate the learned priors and compare to a breadth of transfer learning approaches, using synthetic data and a recent air pollution optimisation problem as benchmarks. We show that PLeBO and prior transfer find good inputs in fewer evaluations.
Bayesian Optimisation Against Climate Change: Applications and Benchmarks
Jun 07, 2023Bayesian optimisation is a powerful method for optimising black-box functions, popular in settings where the true function is expensive to evaluate and no gradient information is available. Bayesian optimisation can improve responses to many optimisation problems within climate change for which simulator models are unavailable or expensive to sample from. While there have been several feasibility demonstrations of Bayesian optimisation in climate-related applications, there has been no unifying review of applications and benchmarks. We provide such a review here, to encourage the use of Bayesian optimisation in important and well-suited application domains. We identify four main application domains: material discovery, wind farm layout, optimal renewable control and environmental monitoring. For each domain we identify a public benchmark or data set that is easy to use and evaluate systems against, while being representative of real-world problems. Due to the lack of a suitable benchmark for environmental monitoring, we propose LAQN-BO, based on air pollution data. Our contributions are: a) identifying a representative range of benchmarks, providing example code where necessary; b) introducing a new benchmark, LAQN-BO; and c) promoting a wider use of climate change applications among Bayesian optimisation practitioners.
Bayesian Optimisation for Active Monitoring of Air Pollution
Feb 15, 2022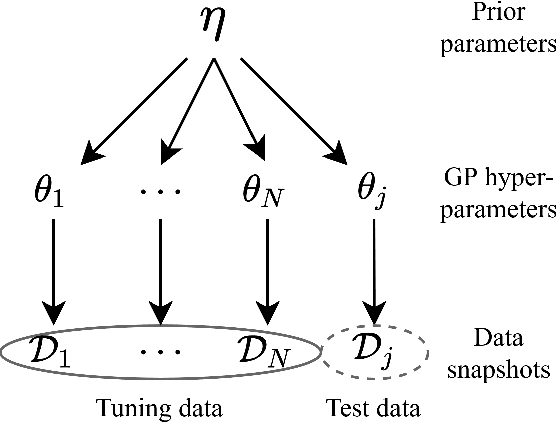
Air pollution is one of the leading causes of mortality globally, resulting in millions of deaths each year. Efficient monitoring is important to measure exposure and enforce legal limits. New low-cost sensors can be deployed in greater numbers and in more varied locations, motivating the problem of efficient automated placement. Previous work suggests Bayesian optimisation is an appropriate method, but only considered a satellite data set, with data aggregated over all altitudes. It is ground-level pollution, that humans breathe, which matters most. We improve on those results using hierarchical models and evaluate our models on urban pollution data in London to show that Bayesian optimisation can be successfully applied to the problem.
Optimising Placement of Pollution Sensors in Windy Environments
Dec 19, 2020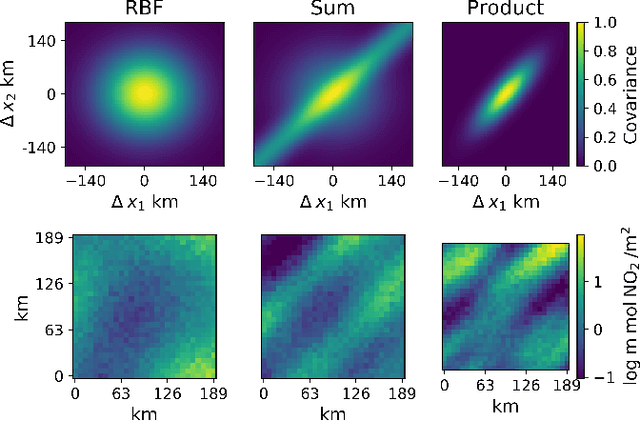
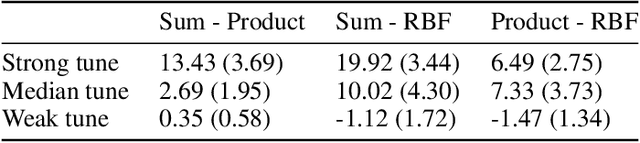
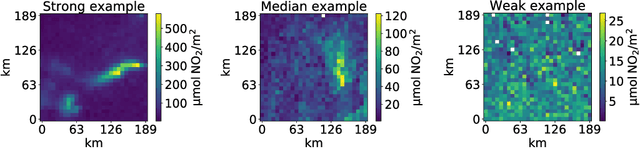
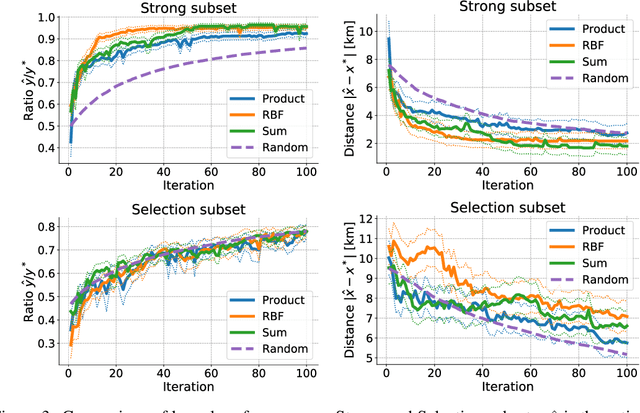
Air pollution is one of the most important causes of mortality in the world. Monitoring air pollution is useful to learn more about the link between health and pollutants, and to identify areas for intervention. Such monitoring is expensive, so it is important to place sensors as efficiently as possible. Bayesian optimisation has proven useful in choosing sensor locations, but typically relies on kernel functions that neglect the statistical structure of air pollution, such as the tendency of pollution to propagate in the prevailing wind direction. We describe two new wind-informed kernels and investigate their advantage for the task of actively learning locations of maximum pollution using Bayesian optimisation.