 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Optimization for Black-Box Retrieval via Reinforcement Learning
Apr 06, 2026Document expansion is a classical technique for improving retrieval quality, and is attractive since it shifts computation offline, avoiding additional query-time processing. However, when applied to modern retrievers, it has been shown to degrade performance, often introducing noise that obfuscates the discriminative signal. We recast document expansion as a document optimization problem: a language model or a vision language model is fine-tuned to transform documents into representations that better align with the expected query distribution under a target retriever, using GRPO with the retriever's ranking improvements as rewards. This approach requires only black-box access to retrieval ranks, and is applicable across single-vector, multi-vector and lexical retrievers. We evaluate our approach on code retrieval and visual document retrieval (VDR) tasks. We find that learned document transformations yield retrieval gains and in many settings enable smaller, more efficient retrievers to outperform larger ones. For example, applying document optimization to OpenAI text-embedding-3-small model improves nDCG5 on code (58.7 to 66.8) and VDR (53.3 to 57.6), even slightly surpassing the 6.5X more expensive OpenAI text-embedding-3-large model (66.3 on code; 57.0 on VDR). When retriever weights are accessible, document optimization is often competitive with fine-tuning, and in most settings their combination performs best, improving Jina-ColBERT-V2 from 55.8 to 63.3 on VDR and from 48.6 to 61.8 on code retrieval.
Guided Query Refinement: Multimodal Hybrid Retrieval with Test-Time Optimization
Oct 06, 2025

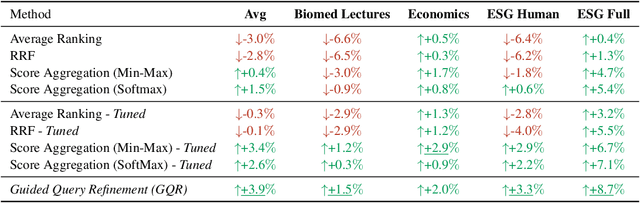

Multimodal encoders have pushed the boundaries of visual document retrieval, matching textual query tokens directly to image patches and achieving state-of-the-art performance on public benchmarks. Recent models relying on this paradigm have massively scaled the sizes of their query and document representations, presenting obstacles to deployment and scalability in real-world pipelines. Furthermore, purely vision-centric approaches may be constrained by the inherent modality gap still exhibited by modern vision-language models. In this work, we connect these challenges to the paradigm of hybrid retrieval, investigating whether a lightweight dense text retriever can enhance a stronger vision-centric model. Existing hybrid methods, which rely on coarse-grained fusion of ranks or scores, fail to exploit the rich interactions within each model's representation space. To address this, we introduce Guided Query Refinement (GQR), a novel test-time optimization method that refines a primary retriever's query embedding using guidance from a complementary retriever's scores. Through extensive experiments on visual document retrieval benchmarks, we demonstrate that GQR allows vision-centric models to match the performance of models with significantly larger representations, while being up to 14x faster and requiring 54x less memory. Our findings show that GQR effectively pushes the Pareto frontier for performance and efficiency in multimodal retrieval. We release our code at https://github.com/IBM/test-time-hybrid-retrieval
Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge
Apr 20, 2024



The popular subword tokenizers of current language models, such as Byte-Pair Encoding (BPE), are known not to respect morpheme boundaries, which affects the downstream performance of the models. While many improved tokenization algorithms have been proposed, their evaluation and cross-comparison is still an open problem. As a solution, we propose a combined intrinsic-extrinsic evaluation framework for subword tokenization. Intrinsic evaluation is based on our new UniMorph Labeller tool that classifies subword tokenization as either morphological or alien. Extrinsic evaluation, in turn, is performed via the Out-of-Vocabulary Generalization Challenge 1.0 benchmark, which consists of three newly specified downstream text classification tasks. Our empirical findings show that the accuracy of UniMorph Labeller is 98%, and that, in all language models studied (including ALBERT, BERT, RoBERTa, and DeBERTa), alien tokenization leads to poorer generalizations compared to morphological tokenization for semantic compositionality of word meanings.
Greed is All You Need: An Evaluation of Tokenizer Inference Methods
Mar 02, 2024While subword tokenizers such as BPE and WordPiece are typically used to build vocabularies for NLP models, the method of decoding text into a sequence of tokens from these vocabularies is often left unspecified, or ill-suited to the method in which they were constructed. We provide a controlled analysis of seven tokenizer inference methods across four different algorithms and three vocabulary sizes, performed on a novel intrinsic evaluation suite we curated for English, combining measures rooted in morphology, cognition, and information theory. We show that for the most commonly used tokenizers, greedy inference performs surprisingly well; and that SaGe, a recently-introduced contextually-informed tokenizer, outperforms all others on morphological alignment.
Tokenization Is More Than Compression
Feb 28, 2024



Tokenization is a foundational step in Natural Language Processing (NLP) tasks, bridging raw text and language models. Existing tokenization approaches like Byte-Pair Encoding (BPE) originate from the field of data compression, and it has been suggested that the effectiveness of BPE stems from its ability to condense text into a relatively small number of tokens. We test the hypothesis that fewer tokens lead to better downstream performance by introducing PathPiece, a new tokenizer that segments a document's text into the minimum number of tokens for a given vocabulary. Through extensive experimentation we find this hypothesis not to be the case, casting doubt on the understanding of the reasons for effective tokenization. To examine which other factors play a role, we evaluate design decisions across all three phases of tokenization: pre-tokenization, vocabulary construction, and segmentation, offering new insights into the design of effective tokenizers. Specifically, we illustrate the importance of pre-tokenization and the benefits of using BPE to initialize vocabulary construction. We train 64 language models with varying tokenization, ranging in size from 350M to 2.4B parameters, all of which are made publicly available.