 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Superword Tokenization
Apr 06, 2026Byte Pair Encoding (BPE) is a widely used tokenization algorithm, whose tokens cannot extend across pre-tokenization boundaries, functionally limiting it to representing at most full words. The BoundlessBPE and SuperBPE algorithms extend and improve BPE by relaxing this limitation and allowing the formation of superwords, which are combinations of pretokens that form phrases. However, previous implementations were impractical to train: for example, BoundlessBPE took 4.7 CPU days to train on 1GB of data. We show that supermerge candidates, two or more consecutive pretokens eligible to form a supermerge, can be aggregated by frequency much like regular pretokens. This avoids keeping full documents in memory, as the original implementations of BoundlessBPE and SuperBPE required, leading to a significant training speedup. We present a two-phase formulation of BoundlessBPE that separates first-phase learning of regular merges from second-phase learning of supermerges, producing identical results to the original implementation. We also show a near-equivalence between two-phase BoundlessBPE and SuperBPE, with the difference being that a manually selected hyperparameter used in SuperBPE can be automatically determined in the second phase of BoundlessBPE. These changes enable a much faster implementation, allowing training on that same 1GB of data in 603 and 593 seconds for BoundlessBPE and SuperBPE, respectively, a more than 600x increase in speed. For each of BoundlessBPE, SuperBPE, and BPE, we open-source both a reference Python implementation and a fast Rust implementation.
The Effect of Scripts and Formats on LLM Numeracy
Jan 21, 2026Large language models (LLMs) have achieved impressive proficiency in basic arithmetic, rivaling human-level performance on standard numerical tasks. However, little attention has been given to how these models perform when numerical expressions deviate from the prevailing conventions present in their training corpora. In this work, we investigate numerical reasoning across a wide range of numeral scripts and formats. We show that LLM accuracy drops substantially when numerical inputs are rendered in underrepresented scripts or formats, despite the underlying mathematical reasoning being identical. We further demonstrate that targeted prompting strategies, such as few-shot prompting and explicit numeral mapping, can greatly narrow this gap. Our findings highlight an overlooked challenge in multilingual numerical reasoning and provide actionable insights for working with LLMs to reliably interpret, manipulate, and generate numbers across diverse numeral scripts and formatting styles.
Boundless Byte Pair Encoding: Breaking the Pre-tokenization Barrier
Mar 31, 2025Pre-tokenization, the initial step in many modern tokenization pipelines, segments text into smaller units called pretokens, typically splitting on whitespace and punctuation. While this process encourages having full, individual words as tokens, it introduces a fundamental limitation in most tokenization algorithms such as Byte Pair Encoding (BPE). Specifically, pre-tokenization causes the distribution of tokens in a corpus to heavily skew towards common, full-length words. This skewed distribution limits the benefits of expanding to larger vocabularies, since the additional tokens appear with progressively lower counts. To overcome this barrier, we propose BoundlessBPE, a modified BPE algorithm that relaxes the pretoken boundary constraint. Our approach selectively merges two complete pretokens into a larger unit we term a superword. Superwords are not necessarily semantically cohesive. For example, the pretokens " of" and " the" might be combined to form the superword " of the". This merging strategy results in a substantially more uniform distribution of tokens across a corpus than standard BPE, and compresses text more effectively, with an approximate 20% increase in bytes per token.
How Much is Enough? The Diminishing Returns of Tokenization Training Data
Feb 27, 2025Tokenization, a crucial initial step in natural language processing, is often assumed to benefit from larger training datasets. This paper investigates the impact of tokenizer training data sizes ranging from 1GB to 900GB. Our findings reveal diminishing returns as the data size increases, highlighting a practical limit on how much further scaling the training data can improve tokenization quality. We analyze this phenomenon and attribute the saturation effect to the constraints imposed by the pre-tokenization stage of tokenization. These results offer valuable insights for optimizing the tokenization process and highlight potential avenues for future research in tokenization algorithms.
Greed is All You Need: An Evaluation of Tokenizer Inference Methods
Mar 02, 2024While subword tokenizers such as BPE and WordPiece are typically used to build vocabularies for NLP models, the method of decoding text into a sequence of tokens from these vocabularies is often left unspecified, or ill-suited to the method in which they were constructed. We provide a controlled analysis of seven tokenizer inference methods across four different algorithms and three vocabulary sizes, performed on a novel intrinsic evaluation suite we curated for English, combining measures rooted in morphology, cognition, and information theory. We show that for the most commonly used tokenizers, greedy inference performs surprisingly well; and that SaGe, a recently-introduced contextually-informed tokenizer, outperforms all others on morphological alignment.
Tokenization Is More Than Compression
Feb 28, 2024



Tokenization is a foundational step in Natural Language Processing (NLP) tasks, bridging raw text and language models. Existing tokenization approaches like Byte-Pair Encoding (BPE) originate from the field of data compression, and it has been suggested that the effectiveness of BPE stems from its ability to condense text into a relatively small number of tokens. We test the hypothesis that fewer tokens lead to better downstream performance by introducing PathPiece, a new tokenizer that segments a document's text into the minimum number of tokens for a given vocabulary. Through extensive experimentation we find this hypothesis not to be the case, casting doubt on the understanding of the reasons for effective tokenization. To examine which other factors play a role, we evaluate design decisions across all three phases of tokenization: pre-tokenization, vocabulary construction, and segmentation, offering new insights into the design of effective tokenizers. Specifically, we illustrate the importance of pre-tokenization and the benefits of using BPE to initialize vocabulary construction. We train 64 language models with varying tokenization, ranging in size from 350M to 2.4B parameters, all of which are made publicly available.
Improving a tf-idf weighted document vector embedding
Feb 26, 2019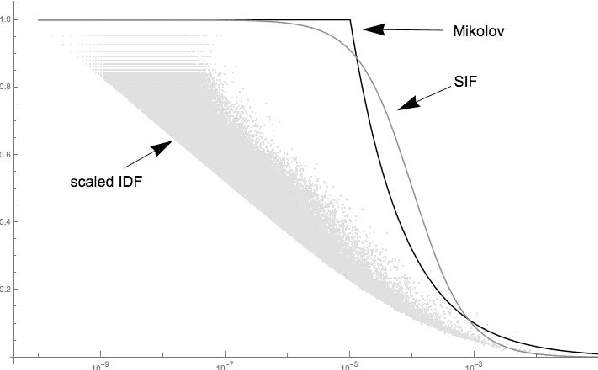
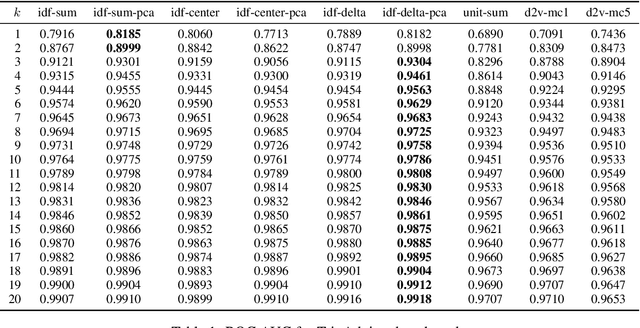
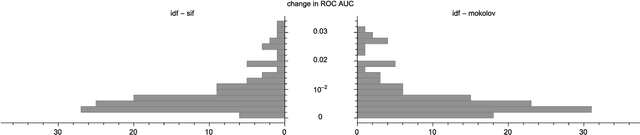
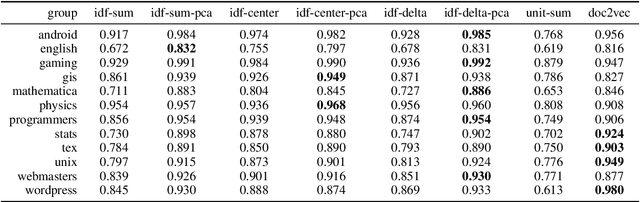
We examine a number of methods to compute a dense vector embedding for a document in a corpus, given a set of word vectors such as those from word2vec or GloVe. We describe two methods that can improve upon a simple weighted sum, that are optimal in the sense that they maximizes a particular weighted cosine similarity measure. We consider several weighting functions, including inverse document frequency (idf), smooth inverse frequency (SIF), and the sub-sampling function used in word2vec. We find that idf works best for our applications. We also use common component removal proposed by Arora et al. as a post-process and find it is helpful in most cases. We compare these embeddings variations to the doc2vec embedding on a new evaluation task using TripAdvisor reviews, and also on the CQADupStack benchmark from the literature.