 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Neural Machine Translation Learns Anaphora Resolution
Paper and Code
May 25, 2018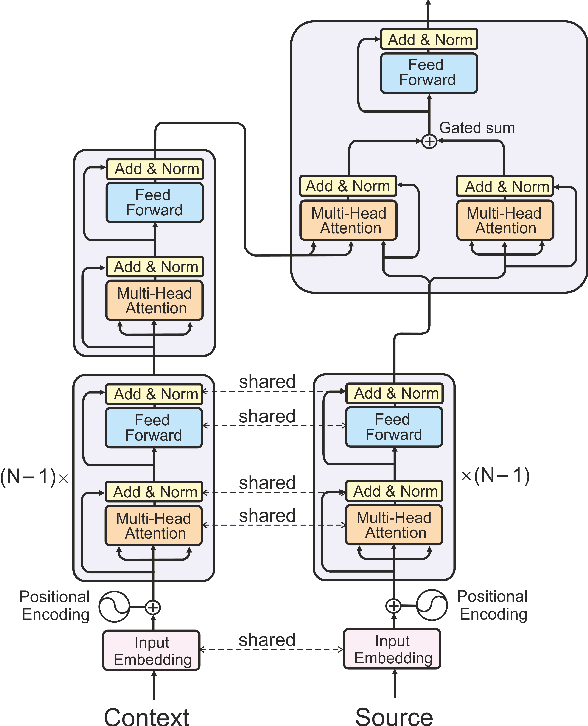

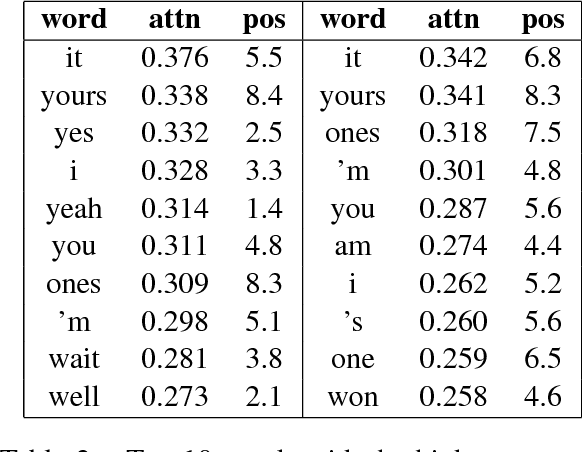
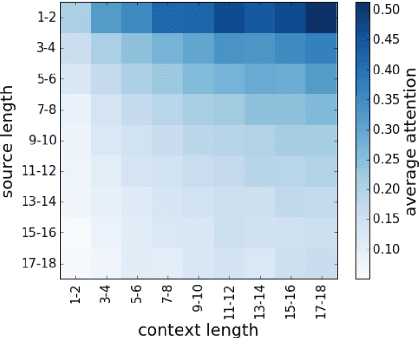
Standard machine translation systems process sentences in isolation and hence ignore extra-sentential information, even though extended context can both prevent mistakes in ambiguous cases and improve translation coherence. We introduce a context-aware neural machine translation model designed in such way that the flow of information from the extended context to the translation model can be controlled and analyzed. We experiment with an English-Russian subtitles dataset, and observe that much of what is captured by our model deals with improving pronoun translation. We measure correspondences between induced attention distributions and coreference relations and observe that the model implicitly captures anaphora. It is consistent with gains for sentences where pronouns need to be gendered in translation. Beside improvements in anaphoric cases, the model also improves in overall BLEU, both over its context-agnostic version (+0.7) and over simple concatenation of the context and source sentences (+0.6).