Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale probabilistic predictors with and without guarantees of validity
Paper and Code
Nov 13, 2015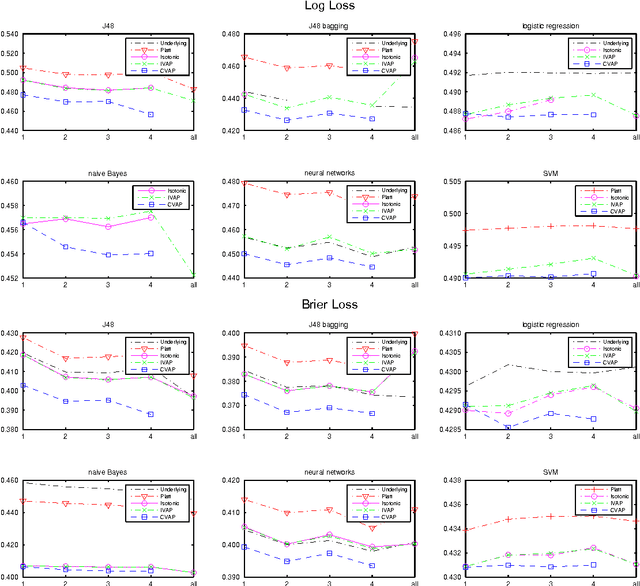
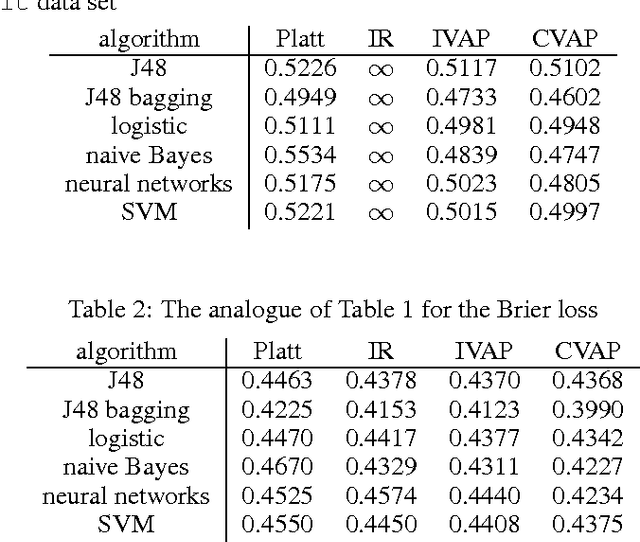
This paper studies theoretically and empirically a method of turning machine-learning algorithms into probabilistic predictors that automatically enjoys a property of validity (perfect calibration) and is computationally efficient. The price to pay for perfect calibration is that these probabilistic predictors produce imprecise (in practice, almost precise for large data sets) probabilities. When these imprecise probabilities are merged into precise probabilities, the resulting predictors, while losing the theoretical property of perfect calibration, are consistently more accurate than the existing methods in empirical studies.
* 38 pages, 14 figures, to appear in Advances in Neural Information
Processing Systems 28 (NIPS 2015). As compared with the previous version
(v1), the MATLAB code (the 5 files with extension .m) and results of new
empirical studies have been added
View paper on