 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaBOT: Bringing Customer Personas to Life with LLMs and RAG
May 22, 2025The introduction of Large Language Models (LLMs) has significantly transformed Natural Language Processing (NLP) applications by enabling more advanced analysis of customer personas. At Volvo Construction Equipment (VCE), customer personas have traditionally been developed through qualitative methods, which are time-consuming and lack scalability. The main objective of this paper is to generate synthetic customer personas and integrate them into a Retrieval-Augmented Generation (RAG) chatbot to support decision-making in business processes. To this end, we first focus on developing a persona-based RAG chatbot integrated with verified personas. Next, synthetic personas are generated using Few-Shot and Chain-of-Thought (CoT) prompting techniques and evaluated based on completeness, relevance, and consistency using McNemar's test. In the final step, the chatbot's knowledge base is augmented with synthetic personas and additional segment information to assess improvements in response accuracy and practical utility. Key findings indicate that Few-Shot prompting outperformed CoT in generating more complete personas, while CoT demonstrated greater efficiency in terms of response time and token usage. After augmenting the knowledge base, the average accuracy rating of the chatbot increased from 5.88 to 6.42 on a 10-point scale, and 81.82% of participants found the updated system useful in business contexts.
High-dimensional near-optimal experiment design for drug discovery via Bayesian sparse sampling
Apr 23, 2021

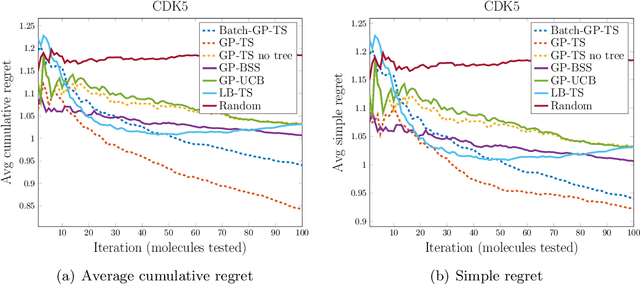
We study the problem of performing automated experiment design for drug screening through Bayesian inference and optimisation. In particular, we compare and contrast the behaviour of linear-Gaussian models and Gaussian processes, when used in conjunction with upper confidence bound algorithms, Thompson sampling, or bounded horizon tree search. We show that non-myopic sophisticated exploration techniques using sparse tree search have a distinct advantage over methods such as Thompson sampling or upper confidence bounds in this setting. We demonstrate the significant superiority of the approach over existing and synthetic datasets of drug toxicity.
Retrain or not retrain: Conformal test martingales for change-point detection
Feb 20, 2021
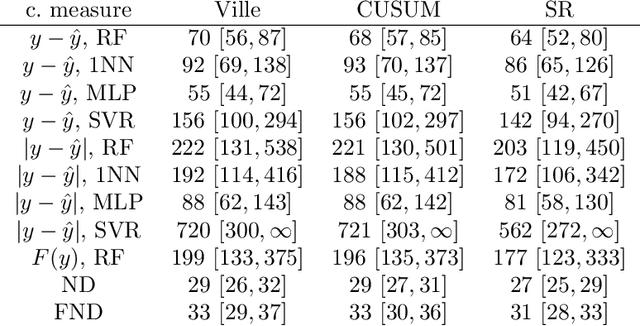
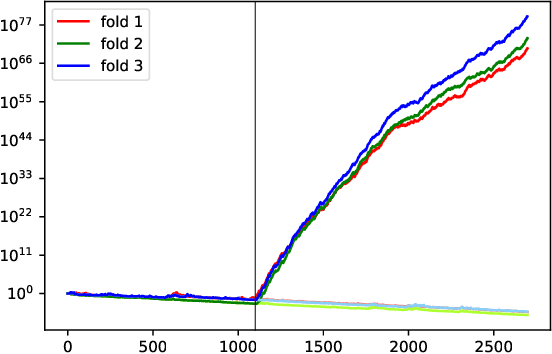
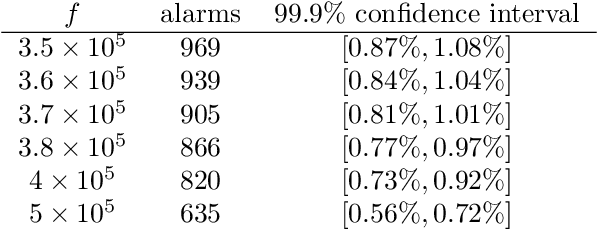
We argue for supplementing the process of training a prediction algorithm by setting up a scheme for detecting the moment when the distribution of the data changes and the algorithm needs to be retrained. Our proposed schemes are based on exchangeability martingales, i.e., processes that are martingales under any exchangeable distribution for the data. Our method, based on conformal prediction, is general and can be applied on top of any modern prediction algorithm. Its validity is guaranteed, and in this paper we make first steps in exploring its efficiency.
Combining Prediction Intervals on Multi-Source Non-Disclosed Regression Datasets
Aug 15, 2019

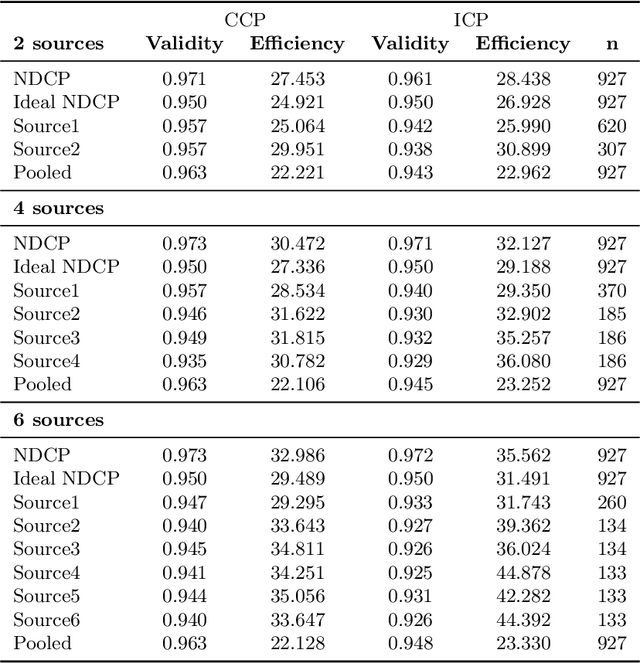
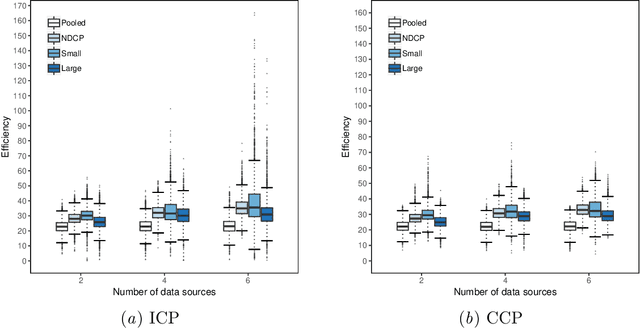
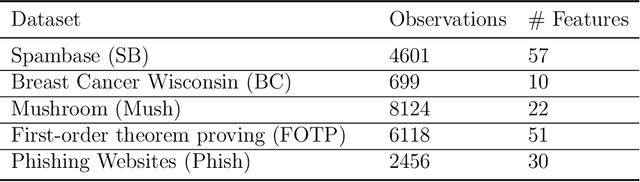
Conformal Prediction is a framework that produces prediction intervals based on the output from a machine learning algorithm. In this paper we explore the case when training data is made up of multiple parts available in different sources that cannot be pooled. We here consider the regression case and propose a method where a conformal predictor is trained on each data source independently, and where the prediction intervals are then combined into a single interval. We call the approach Non-Disclosed Conformal Prediction (NDCP), and we evaluate it on a regression dataset from the UCI machine learning repository using support vector regression as the underlying machine learning algorithm, with varying number of data sources and sizes. The results show that the proposed method produces conservatively valid prediction intervals, and while we cannot retain the same efficiency as when all data is used, efficiency is improved through the proposed approach as compared to predicting using a single arbitrarily chosen source.
Aggregating Predictions on Multiple Non-disclosed Datasets using Conformal Prediction
Jun 14, 2018
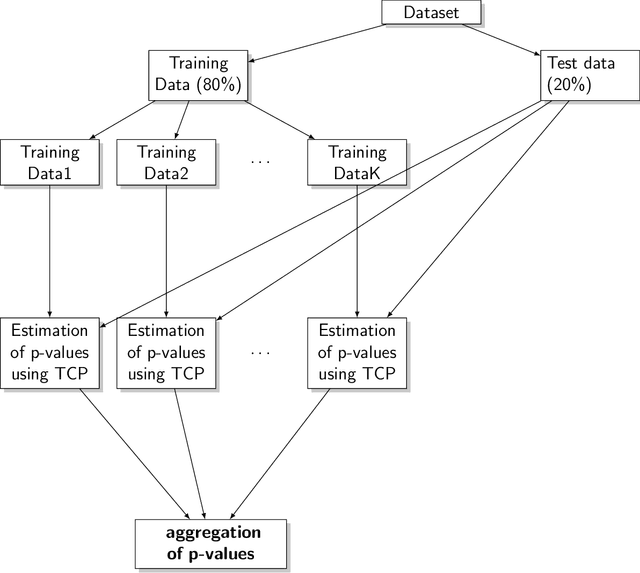
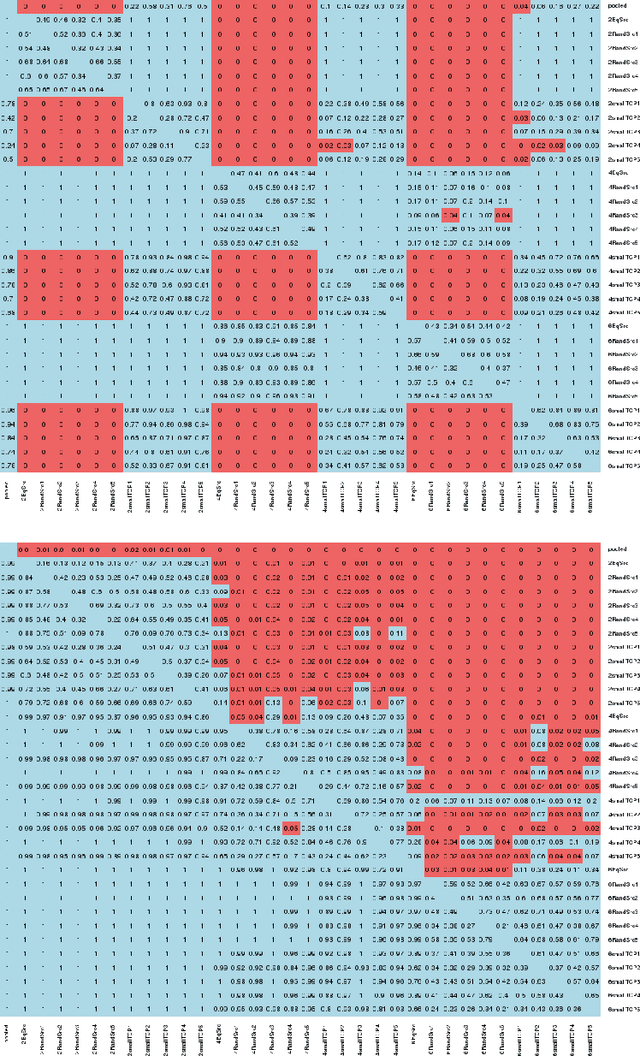
Conformal Prediction is a machine learning methodology that produces valid prediction regions under mild conditions. In this paper, we explore the application of making predictions over multiple data sources of different sizes without disclosing data between the sources. We propose that each data source applies a transductive conformal predictor independently using the local data, and that the individual predictions are then aggregated to form a combined prediction region. We demonstrate the method on several data sets, and show that the proposed method produces conservatively valid predictions and reduces the variance in the aggregated predictions. We also study the effect that the number of data sources and size of each source has on aggregated predictions, as compared with equally sized sources and pooled data.
Conformal Prediction in Learning Under Privileged Information Paradigm with Applications in Drug Discovery
Apr 04, 2018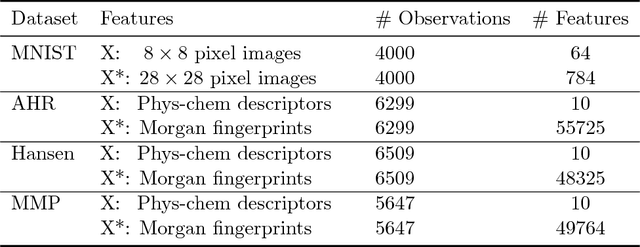
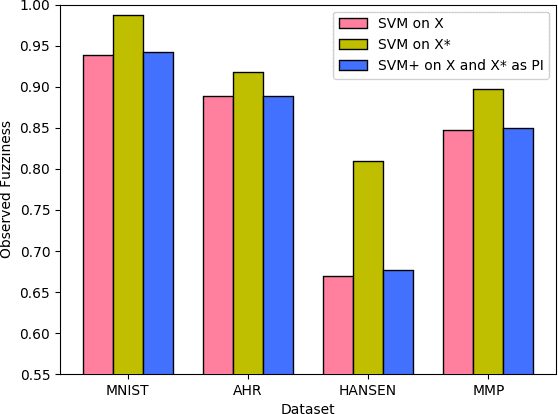

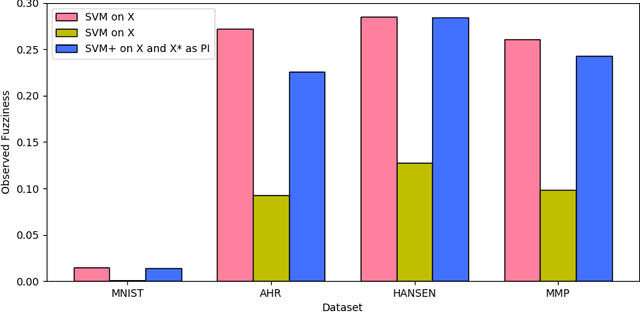
This paper explores conformal prediction in the learning under privileged information (LUPI) paradigm. We use the SVM+ realization of LUPI in an inductive conformal predictor, and apply it to the MNIST benchmark dataset and three datasets in drug discovery. The results show that using privileged information produces valid models and improves efficiency compared to standard SVM, however the improvement varies between the tested datasets and is not substantial in the drug discovery applications. More importantly, using SVM+ in a conformal prediction framework enables valid prediction intervals at specified significance levels.