Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional near-optimal experiment design for drug discovery via Bayesian sparse sampling
Paper and Code
Apr 23, 2021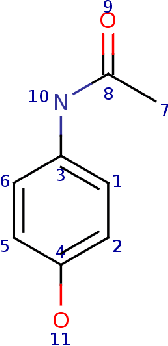

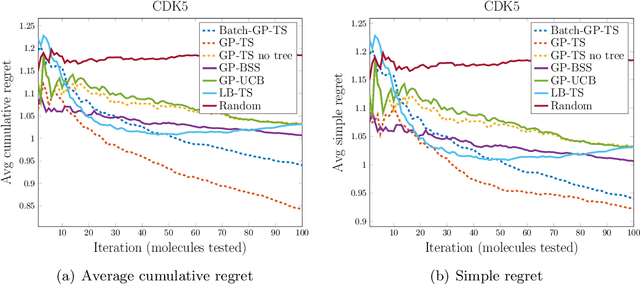
We study the problem of performing automated experiment design for drug screening through Bayesian inference and optimisation. In particular, we compare and contrast the behaviour of linear-Gaussian models and Gaussian processes, when used in conjunction with upper confidence bound algorithms, Thompson sampling, or bounded horizon tree search. We show that non-myopic sophisticated exploration techniques using sparse tree search have a distinct advantage over methods such as Thompson sampling or upper confidence bounds in this setting. We demonstrate the significant superiority of the approach over existing and synthetic datasets of drug toxicity.
* 14 pages, 6 figures
View paper on