 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Student is Better Than Expected: Adaptive Teacher-Student Collaboration for Text-Conditional Diffusion Models
Paper and Code
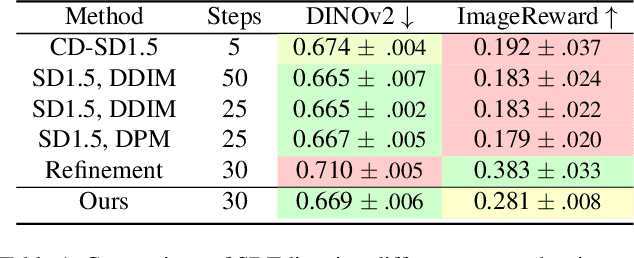

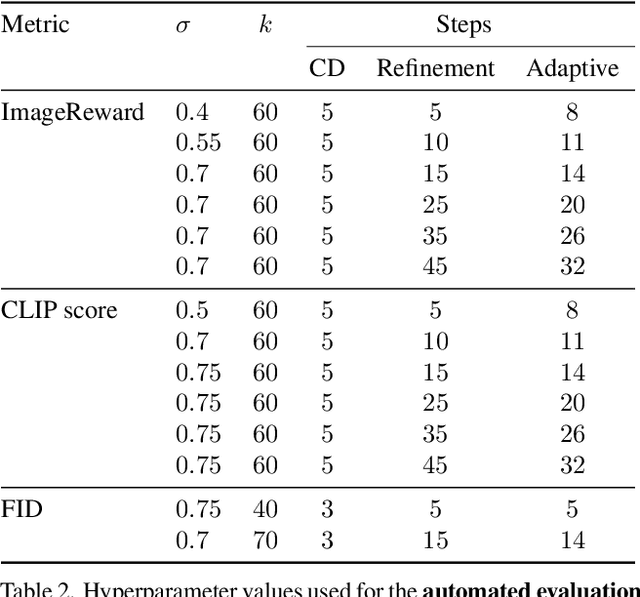

Knowledge distillation methods have recently shown to be a promising direction to speedup the synthesis of large-scale diffusion models by requiring only a few inference steps. While several powerful distillation methods were recently proposed, the overall quality of student samples is typically lower compared to the teacher ones, which hinders their practical usage. In this work, we investigate the relative quality of samples produced by the teacher text-to-image diffusion model and its distilled student version. As our main empirical finding, we discover that a noticeable portion of student samples exhibit superior fidelity compared to the teacher ones, despite the ``approximate'' nature of the student. Based on this finding, we propose an adaptive collaboration between student and teacher diffusion models for effective text-to-image synthesis. Specifically, the distilled model produces the initial sample, and then an oracle decides whether it needs further improvements with a slow teacher model. Extensive experiments demonstrate that the designed pipeline surpasses state-of-the-art text-to-image alternatives for various inference budgets in terms of human preference. Furthermore, the proposed approach can be naturally used in popular applications such as text-guided image editing and controllable generation.