 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion LLMs
Dec 23, 2025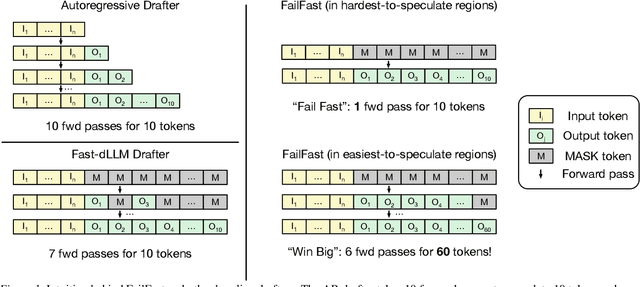
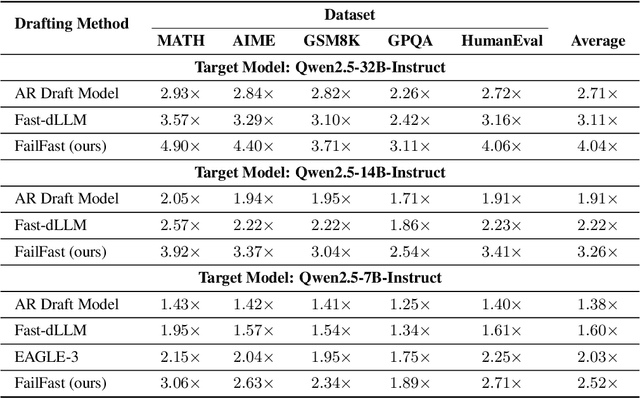
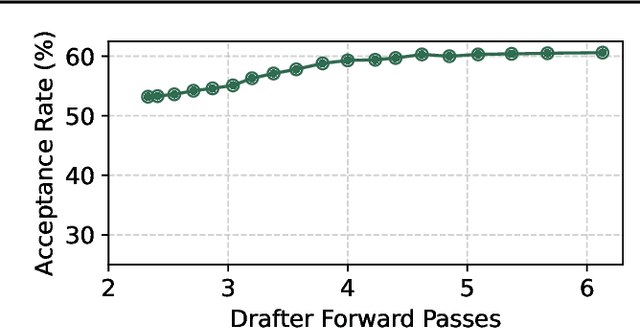

Diffusion Large Language Models (dLLMs) offer fast, parallel token generation, but their standalone use is plagued by an inherent efficiency-quality tradeoff. We show that, if carefully applied, the attributes of dLLMs can actually be a strength for drafters in speculative decoding with autoregressive (AR) verifiers. Our core insight is that dLLM's speed from parallel decoding drastically lowers the risk of costly rejections, providing a practical mechanism to effectively realize the (elusive) lengthy drafts that lead to large speedups with speculative decoding. We present FailFast, a dLLM-based speculative decoding framework that realizes this approach by dynamically adapting its speculation length. It "fails fast" by spending minimal compute in hard-to-speculate regions to shrink speculation latency and "wins big" by aggressively extending draft lengths in easier regions to reduce verification latency (in many cases, speculating and accepting 70 tokens at a time!). Without any fine-tuning, FailFast delivers lossless acceleration of AR LLMs and achieves up to 4.9$\times$ speedup over vanilla decoding, 1.7$\times$ over the best naive dLLM drafter, and 1.4$\times$ over EAGLE-3 across diverse models and workloads. We open-source FailFast at https://github.com/ruipeterpan/failfast.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
AdaServe: SLO-Customized LLM Serving with Fine-Grained Speculative Decoding
Jan 21, 2025This paper introduces AdaServe, the first LLM serving system to support SLO customization through fine-grained speculative decoding. AdaServe leverages the logits of a draft model to predict the speculative accuracy of tokens and employs a theoretically optimal algorithm to construct token trees for verification. To accommodate diverse SLO requirements without compromising throughput, AdaServe employs a speculation-and-selection scheme that first constructs candidate token trees for each request and then dynamically selects tokens to meet individual SLO constraints while optimizing throughput. Comprehensive evaluations demonstrate that AdaServe achieves up to 73% higher SLO attainment and 74% higher goodput compared to state-of-the-art systems. These results underscore AdaServe's potential to enhance the efficiency and adaptability of LLM deployments across varied application scenarios.
TidalDecode: Fast and Accurate LLM Decoding with Position Persistent Sparse Attention
Oct 07, 2024Large language models (LLMs) have driven significant advancements across diverse NLP tasks, with long-context models gaining prominence for handling extended inputs. However, the expanding key-value (KV) cache size required by Transformer architectures intensifies the memory constraints, particularly during the decoding phase, creating a significant bottleneck. Existing sparse attention mechanisms designed to address this bottleneck have two limitations: (1) they often fail to reliably identify the most relevant tokens for attention, and (2) they overlook the spatial coherence of token selection across consecutive Transformer layers, which can lead to performance degradation and substantial overhead in token selection. This paper introduces TidalDecode, a simple yet effective algorithm and system for fast and accurate LLM decoding through position persistent sparse attention. TidalDecode leverages the spatial coherence of tokens selected by existing sparse attention methods and introduces a few token selection layers that perform full attention to identify the tokens with the highest attention scores, while all other layers perform sparse attention with the pre-selected tokens. This design enables TidalDecode to substantially reduce the overhead of token selection for sparse attention without sacrificing the quality of the generated results. Evaluation on a diverse set of LLMs and tasks shows that TidalDecode closely matches the generative performance of full attention methods while reducing the LLM decoding latency by up to 2.1x.