 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Training with Generated Datasets for Name-Only Transfer of Vision-Language Models
Paper and Code
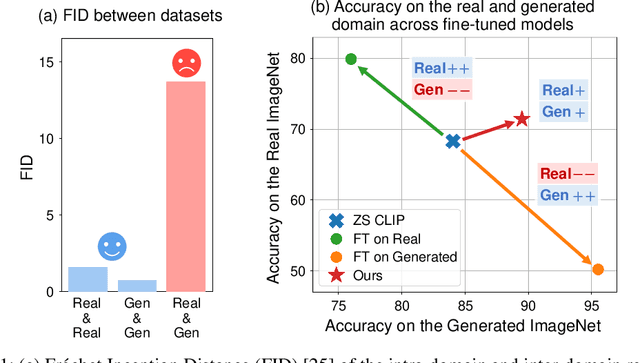
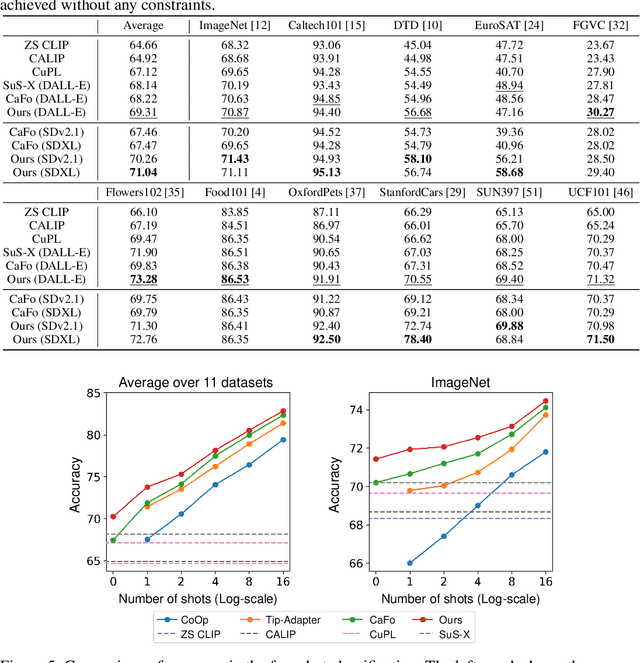
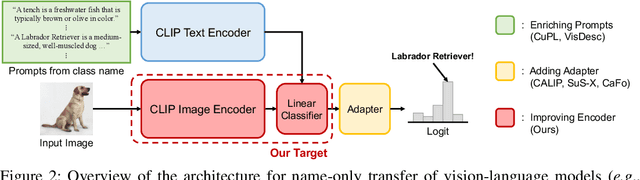
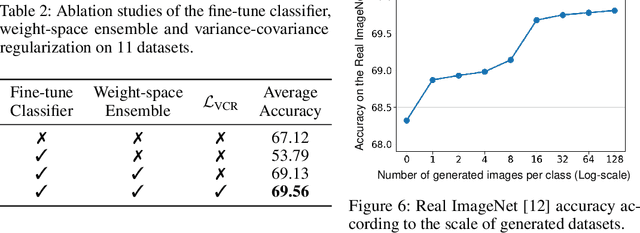
Recent advancements in text-to-image generation have inspired researchers to generate datasets tailored for perception models using generative models, which prove particularly valuable in scenarios where real-world data is limited. In this study, our goal is to address the challenges when fine-tuning vision-language models (e.g., CLIP) on generated datasets. Specifically, we aim to fine-tune vision-language models to a specific classification model without access to any real images, also known as name-only transfer. However, despite the high fidelity of generated images, we observed a significant performance degradation when fine-tuning the model using the generated datasets due to the domain gap between real and generated images. To overcome the domain gap, we provide two regularization methods for training and post-training, respectively. First, we leverage the domain-agnostic knowledge from the original pre-trained vision-language model by conducting the weight-space ensemble of the fine-tuned model on the generated dataset with the original pre-trained model at the post-training. Secondly, we reveal that fine-tuned models with high feature diversity score high performance in the real domain, which indicates that increasing feature diversity prevents learning the generated domain-specific knowledge. Thus, we encourage feature diversity by providing additional regularization at training time. Extensive experiments on various classification datasets and various text-to-image generation models demonstrated that our analysis and regularization techniques effectively mitigate the domain gap, which has long been overlooked, and enable us to achieve state-of-the-art performance by training with generated images. Code is available at https://github.com/pmh9960/regft-for-gen