 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Fine-Tuning Diffusion Transformers via Dynamic Patch Sampling and Block Skipping
Mar 21, 2026Diffusion Transformers (DiTs) have significantly enhanced text-to-image (T2I) generation quality, enabling high-quality personalized content creation. However, fine-tuning these models requires substantial computational complexity and memory, limiting practical deployment under resource constraints. To tackle these challenges, we propose a memory-efficient fine-tuning framework called DiT-BlockSkip, integrating timestep-aware dynamic patch sampling and block skipping by precomputing residual features. Our dynamic patch sampling strategy adjusts patch sizes based on the diffusion timestep, then resizes the cropped patches to a fixed lower resolution. This approach reduces forward & backward memory usage while allowing the model to capture global structures at higher timesteps and fine-grained details at lower timesteps. The block skipping mechanism selectively fine-tunes essential transformer blocks and precomputes residual features for the skipped blocks, significantly reducing training memory. To identify vital blocks for personalization, we introduce a block selection strategy based on cross-attention masking. Evaluations demonstrate that our approach achieves competitive personalization performance qualitatively and quantitatively, while reducing memory usage substantially, moving toward on-device feasibility (e.g., smartphones, IoT devices) for large-scale diffusion transformers.
InsertAnywhere: Bridging 4D Scene Geometry and Diffusion Models for Realistic Video Object Insertion
Dec 19, 2025Recent advances in diffusion-based video generation have opened new possibilities for controllable video editing, yet realistic video object insertion (VOI) remains challenging due to limited 4D scene understanding and inadequate handling of occlusion and lighting effects. We present InsertAnywhere, a new VOI framework that achieves geometrically consistent object placement and appearance-faithful video synthesis. Our method begins with a 4D aware mask generation module that reconstructs the scene geometry and propagates user specified object placement across frames while maintaining temporal coherence and occlusion consistency. Building upon this spatial foundation, we extend a diffusion based video generation model to jointly synthesize the inserted object and its surrounding local variations such as illumination and shading. To enable supervised training, we introduce ROSE++, an illumination aware synthetic dataset constructed by transforming the ROSE object removal dataset into triplets of object removed video, object present video, and a VLM generated reference image. Through extensive experiments, we demonstrate that our framework produces geometrically plausible and visually coherent object insertions across diverse real world scenarios, significantly outperforming existing research and commercial models.
Infinite-Homography as Robust Conditioning for Camera-Controlled Video Generation
Dec 18, 2025



Recent progress in video diffusion models has spurred growing interest in camera-controlled novel-view video generation for dynamic scenes, aiming to provide creators with cinematic camera control capabilities in post-production. A key challenge in camera-controlled video generation is ensuring fidelity to the specified camera pose, while maintaining view consistency and reasoning about occluded geometry from limited observations. To address this, existing methods either train trajectory-conditioned video generation model on trajectory-video pair dataset, or estimate depth from the input video to reproject it along a target trajectory and generate the unprojected regions. Nevertheless, existing methods struggle to generate camera-pose-faithful, high-quality videos for two main reasons: (1) reprojection-based approaches are highly susceptible to errors caused by inaccurate depth estimation; and (2) the limited diversity of camera trajectories in existing datasets restricts learned models. To address these limitations, we present InfCam, a depth-free, camera-controlled video-to-video generation framework with high pose fidelity. The framework integrates two key components: (1) infinite homography warping, which encodes 3D camera rotations directly within the 2D latent space of a video diffusion model. Conditioning on this noise-free rotational information, the residual parallax term is predicted through end-to-end training to achieve high camera-pose fidelity; and (2) a data augmentation pipeline that transforms existing synthetic multiview datasets into sequences with diverse trajectories and focal lengths. Experimental results demonstrate that InfCam outperforms baseline methods in camera-pose accuracy and visual fidelity, generalizing well from synthetic to real-world data. Link to our project page:https://emjay73.github.io/InfCam/
MultiHuman-Testbench: Benchmarking Image Generation for Multiple Humans
Jun 25, 2025Generation of images containing multiple humans, performing complex actions, while preserving their facial identities, is a significant challenge. A major factor contributing to this is the lack of a a dedicated benchmark. To address this, we introduce MultiHuman-Testbench, a novel benchmark for rigorously evaluating generative models for multi-human generation. The benchmark comprises 1800 samples, including carefully curated text prompts, describing a range of simple to complex human actions. These prompts are matched with a total of 5,550 unique human face images, sampled uniformly to ensure diversity across age, ethnic background, and gender. Alongside captions, we provide human-selected pose conditioning images which accurately match the prompt. We propose a multi-faceted evaluation suite employing four key metrics to quantify face count, ID similarity, prompt alignment, and action detection. We conduct a thorough evaluation of a diverse set of models, including zero-shot approaches and training-based methods, with and without regional priors. We also propose novel techniques to incorporate image and region isolation using human segmentation and Hungarian matching, significantly improving ID similarity. Our proposed benchmark and key findings provide valuable insights and a standardized tool for advancing research in multi-human image generation.
ReCDAP: Relation-Based Conditional Diffusion with Attention Pooling for Few-Shot Knowledge Graph Completion
May 12, 2025Knowledge Graphs (KGs), composed of triples in the form of (head, relation, tail) and consisting of entities and relations, play a key role in information retrieval systems such as question answering, entity search, and recommendation. In real-world KGs, although many entities exist, the relations exhibit a long-tail distribution, which can hinder information retrieval performance. Previous few-shot knowledge graph completion studies focused exclusively on the positive triple information that exists in the graph or, when negative triples were incorporated, used them merely as a signal to indicate incorrect triples. To overcome this limitation, we propose Relation-Based Conditional Diffusion with Attention Pooling (ReCDAP). First, negative triples are generated by randomly replacing the tail entity in the support set. By conditionally incorporating positive information in the KG and non-existent negative information into the diffusion process, the model separately estimates the latent distributions for positive and negative relations. Moreover, including an attention pooler enables the model to leverage the differences between positive and negative cases explicitly. Experiments on two widely used datasets demonstrate that our method outperforms existing approaches, achieving state-of-the-art performance. The code is available at https://github.com/hou27/ReCDAP-FKGC.
* Accepted by SIGIR 2025, 5 pages, 1 figure
PromptDresser: Improving the Quality and Controllability of Virtual Try-On via Generative Textual Prompt and Prompt-aware Mask
Dec 22, 2024Recent virtual try-on approaches have advanced by fine-tuning the pre-trained text-to-image diffusion models to leverage their powerful generative ability. However, the use of text prompts in virtual try-on is still underexplored. This paper tackles a text-editable virtual try-on task that changes the clothing item based on the provided clothing image while editing the wearing style (e.g., tucking style, fit) according to the text descriptions. In the text-editable virtual try-on, three key aspects exist: (i) designing rich text descriptions for paired person-clothing data to train the model, (ii) addressing the conflicts where textual information of the existing person's clothing interferes the generation of the new clothing, and (iii) adaptively adjust the inpainting mask aligned with the text descriptions, ensuring proper editing areas while preserving the original person's appearance irrelevant to the new clothing. To address these aspects, we propose PromptDresser, a text-editable virtual try-on model that leverages large multimodal model (LMM) assistance to enable high-quality and versatile manipulation based on generative text prompts. Our approach utilizes LMMs via in-context learning to generate detailed text descriptions for person and clothing images independently, including pose details and editing attributes using minimal human cost. Moreover, to ensure the editing areas, we adjust the inpainting mask depending on the text prompts adaptively. We found that our approach, utilizing detailed text prompts, not only enhances text editability but also effectively conveys clothing details that are difficult to capture through images alone, thereby enhancing image quality. Our code is available at https://github.com/rlawjdghek/PromptDresser.
What to Preserve and What to Transfer: Faithful, Identity-Preserving Diffusion-based Hairstyle Transfer
Aug 29, 2024
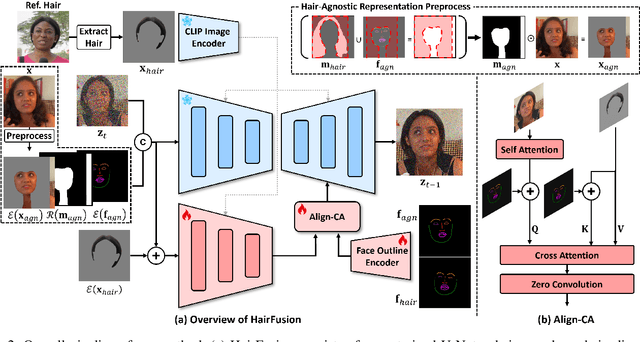


Hairstyle transfer is a challenging task in the image editing field that modifies the hairstyle of a given face image while preserving its other appearance and background features. The existing hairstyle transfer approaches heavily rely on StyleGAN, which is pre-trained on cropped and aligned face images. Hence, they struggle to generalize under challenging conditions such as extreme variations of head poses or focal lengths. To address this issue, we propose a one-stage hairstyle transfer diffusion model, HairFusion, that applies to real-world scenarios. Specifically, we carefully design a hair-agnostic representation as the input of the model, where the original hair information is thoroughly eliminated. Next, we introduce a hair align cross-attention (Align-CA) to accurately align the reference hairstyle with the face image while considering the difference in their face shape. To enhance the preservation of the face image's original features, we leverage adaptive hair blending during the inference, where the output's hair regions are estimated by the cross-attention map in Align-CA and blended with non-hair areas of the face image. Our experimental results show that our method achieves state-of-the-art performance compared to the existing methods in preserving the integrity of both the transferred hairstyle and the surrounding features. The codes are available at https://github.com/cychungg/HairFusion.
TCAN: Animating Human Images with Temporally Consistent Pose Guidance using Diffusion Models
Jul 12, 2024
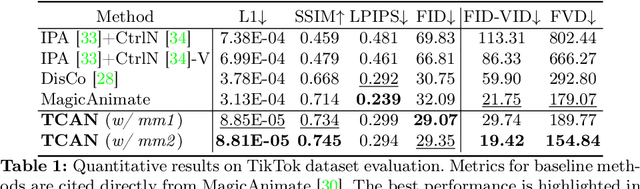
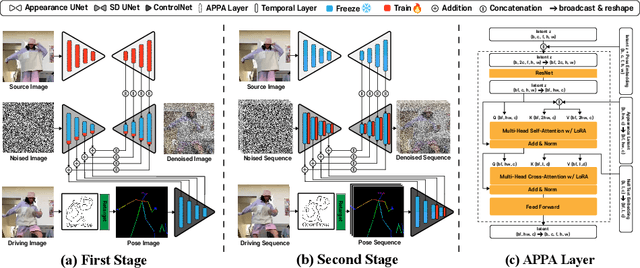

Pose-driven human-image animation diffusion models have shown remarkable capabilities in realistic human video synthesis. Despite the promising results achieved by previous approaches, challenges persist in achieving temporally consistent animation and ensuring robustness with off-the-shelf pose detectors. In this paper, we present TCAN, a pose-driven human image animation method that is robust to erroneous poses and consistent over time. In contrast to previous methods, we utilize the pre-trained ControlNet without fine-tuning to leverage its extensive pre-acquired knowledge from numerous pose-image-caption pairs. To keep the ControlNet frozen, we adapt LoRA to the UNet layers, enabling the network to align the latent space between the pose and appearance features. Additionally, by introducing an additional temporal layer to the ControlNet, we enhance robustness against outliers of the pose detector. Through the analysis of attention maps over the temporal axis, we also designed a novel temperature map leveraging pose information, allowing for a more static background. Extensive experiments demonstrate that the proposed method can achieve promising results in video synthesis tasks encompassing various poses, like chibi. Project Page: https://eccv2024tcan.github.io/
StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On
Dec 04, 2023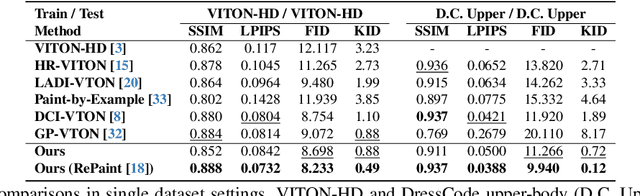

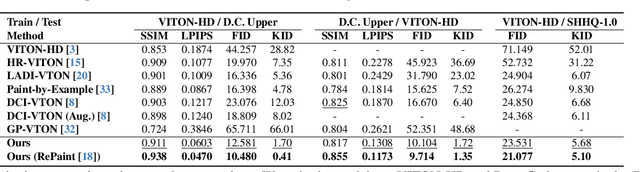

Given a clothing image and a person image, an image-based virtual try-on aims to generate a customized image that appears natural and accurately reflects the characteristics of the clothing image. In this work, we aim to expand the applicability of the pre-trained diffusion model so that it can be utilized independently for the virtual try-on task.The main challenge is to preserve the clothing details while effectively utilizing the robust generative capability of the pre-trained model. In order to tackle these issues, we propose StableVITON, learning the semantic correspondence between the clothing and the human body within the latent space of the pre-trained diffusion model in an end-to-end manner. Our proposed zero cross-attention blocks not only preserve the clothing details by learning the semantic correspondence but also generate high-fidelity images by utilizing the inherent knowledge of the pre-trained model in the warping process. Through our proposed novel attention total variation loss and applying augmentation, we achieve the sharp attention map, resulting in a more precise representation of clothing details. StableVITON outperforms the baselines in qualitative and quantitative evaluation, showing promising quality in arbitrary person images. Our code is available at https://github.com/rlawjdghek/StableVITON.
Hamilton-Jacobi Deep Q-Learning for Deterministic Continuous-Time Systems with Lipschitz Continuous Controls
Oct 27, 2020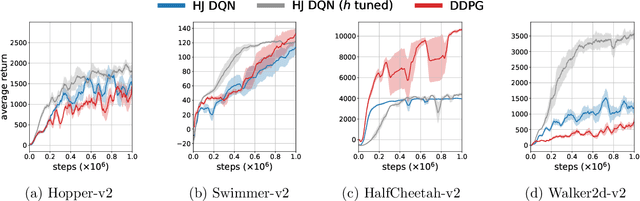

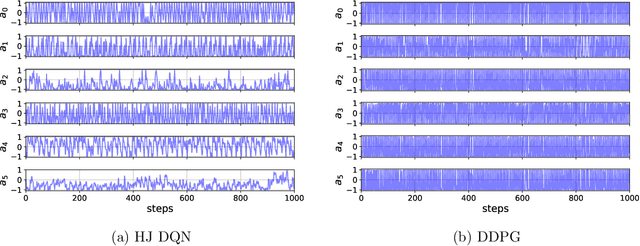
In this paper, we propose Q-learning algorithms for continuous-time deterministic optimal control problems with Lipschitz continuous controls. Our method is based on a new class of Hamilton-Jacobi-Bellman (HJB) equations derived from applying the dynamic programming principle to continuous-time Q-functions. A novel semi-discrete version of the HJB equation is proposed to design a Q-learning algorithm that uses data collected in discrete time without discretizing or approximating the system dynamics. We identify the condition under which the Q-function estimated by this algorithm converges to the optimal Q-function. For practical implementation, we propose the Hamilton-Jacobi DQN, which extends the idea of deep Q-networks (DQN) to our continuous control setting. This approach does not require actor networks or numerical solutions to optimization problems for greedy actions since the HJB equation provides a simple characterization of optimal controls via ordinary differential equations. We empirically demonstrate the performance of our method through benchmark tasks and high-dimensional linear-quadratic problems.