Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamilton-Jacobi-Bellman Equations for Q-Learning in Continuous Time
Paper and Code
Dec 23, 2019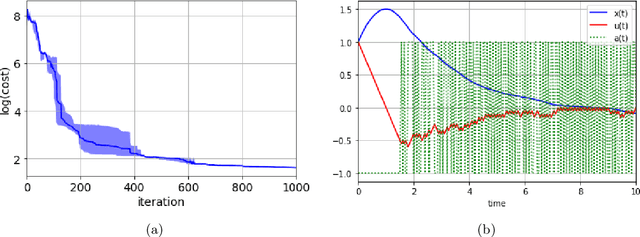
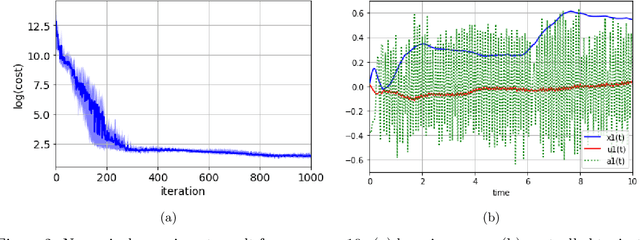

In this paper, we introduce Hamilton-Jacobi-Bellman (HJB) equations for Q-functions in continuous time optimal control problems with Lipschitz continuous controls. The standard Q-function used in reinforcement learning is shown to be the unique viscosity solution of the HJB equation. A necessary and sufficient condition for optimality is provided using the viscosity solution framework. By using the HJB equation, we develop a Q-learning method for continuous-time dynamical systems. A DQN-like algorithm is also proposed for high-dimensional state and control spaces. The performance of the proposed Q-learning algorithm is demonstrated using 1-, 10- and 20-dimensional dynamical systems.
View paper on
 OpenReview
OpenReview