 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCAN: Animating Human Images with Temporally Consistent Pose Guidance using Diffusion Models
Paper and Code

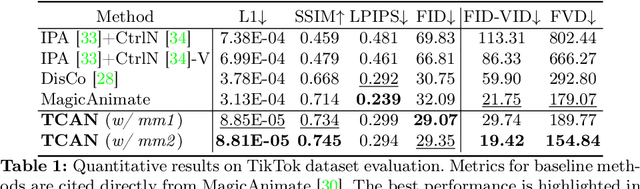
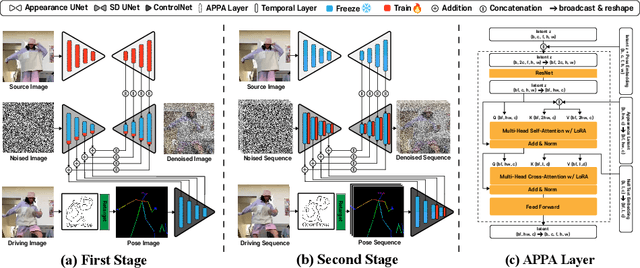

Pose-driven human-image animation diffusion models have shown remarkable capabilities in realistic human video synthesis. Despite the promising results achieved by previous approaches, challenges persist in achieving temporally consistent animation and ensuring robustness with off-the-shelf pose detectors. In this paper, we present TCAN, a pose-driven human image animation method that is robust to erroneous poses and consistent over time. In contrast to previous methods, we utilize the pre-trained ControlNet without fine-tuning to leverage its extensive pre-acquired knowledge from numerous pose-image-caption pairs. To keep the ControlNet frozen, we adapt LoRA to the UNet layers, enabling the network to align the latent space between the pose and appearance features. Additionally, by introducing an additional temporal layer to the ControlNet, we enhance robustness against outliers of the pose detector. Through the analysis of attention maps over the temporal axis, we also designed a novel temperature map leveraging pose information, allowing for a more static background. Extensive experiments demonstrate that the proposed method can achieve promising results in video synthesis tasks encompassing various poses, like chibi. Project Page: https://eccv2024tcan.github.io/