 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamilton-Jacobi Deep Q-Learning for Deterministic Continuous-Time Systems with Lipschitz Continuous Controls
Paper and Code
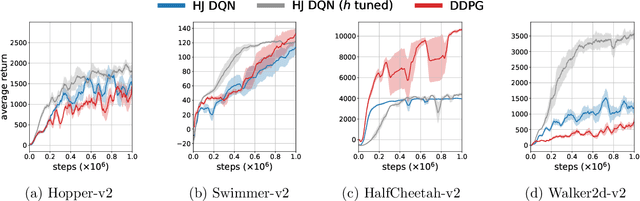

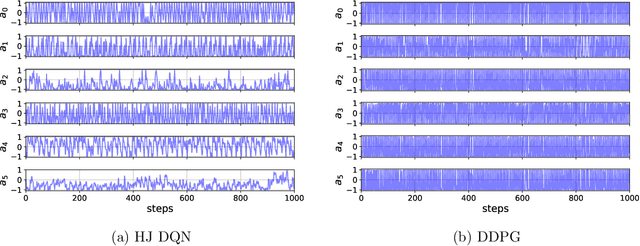
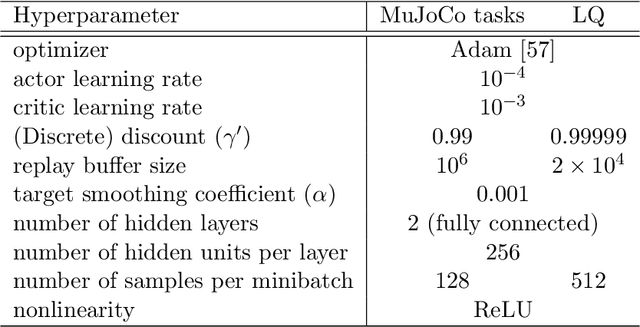
In this paper, we propose Q-learning algorithms for continuous-time deterministic optimal control problems with Lipschitz continuous controls. Our method is based on a new class of Hamilton-Jacobi-Bellman (HJB) equations derived from applying the dynamic programming principle to continuous-time Q-functions. A novel semi-discrete version of the HJB equation is proposed to design a Q-learning algorithm that uses data collected in discrete time without discretizing or approximating the system dynamics. We identify the condition under which the Q-function estimated by this algorithm converges to the optimal Q-function. For practical implementation, we propose the Hamilton-Jacobi DQN, which extends the idea of deep Q-networks (DQN) to our continuous control setting. This approach does not require actor networks or numerical solutions to optimization problems for greedy actions since the HJB equation provides a simple characterization of optimal controls via ordinary differential equations. We empirically demonstrate the performance of our method through benchmark tasks and high-dimensional linear-quadratic problems.