 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Law for Recommendation Models: Towards General-purpose User Representations
Dec 01, 2021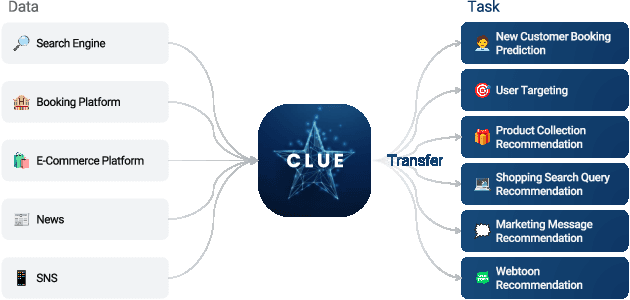
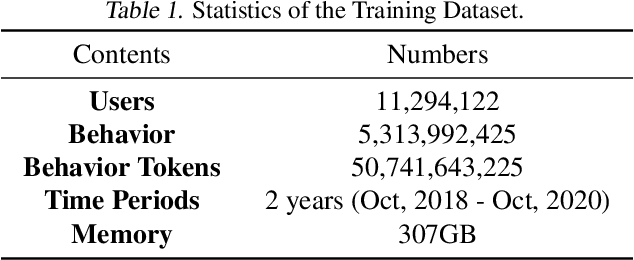
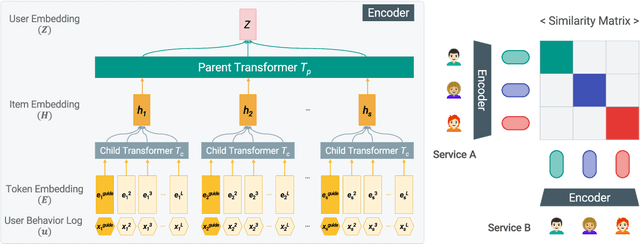

A recent trend shows that a general class of models, e.g., BERT, GPT-3, CLIP, trained on broad data at scale have shown a great variety of functionalities with a single learning architecture. In this work, we explore the possibility of general-purpose user representation learning by training a universal user encoder at large scales. We demonstrate that the scaling law holds in the user modeling areas, where the training error scales as a power-law with the amount of compute. Our Contrastive Learning User Encoder (CLUE), optimizes task-agnostic objectives, and the resulting user embeddings stretches our expectation of what is possible to do in various downstream tasks. CLUE also shows great transferability to other domains and systems, as performances on an online experiment shows significant improvements in online Click-Through-Rate (CTR). Furthermore, we also investigate how the performance changes according to the scale-up factors, i.e., model capacity, sequence length and batch size. Finally, we discuss the broader impacts of CLUE in general.